reinforcement learning with human feedback Complete Guide On Fine-Tuning LLMs using RLHF Explore how LLM reinforcement learning with human feedback (RLHF) fine-tunes large language models, improving natural language responses and optimizing AI behavior through rewards, human input, and iterative learning for enhanced model performance.
dataset Data Collection and Preprocessing for Large Language Models Are you struggling to harness the full potential of Large Language Models (LLMs) due to the complexities of data collection and preprocessing? You're not alone. Many developers and researchers face significant challenges in sourcing and preparing the vast amounts of text data necessary for training these advanced AI
Large Language Models 8 Challenges Of Building Your Own Large Language Model Explore the top LLM challenges in building your own large language model, from managing massive datasets to high fine-tuning costs and data privacy.
technology DINO: Unleashing the Potential of Self-Supervised Learning DINO leverages self-supervised learning to generate visual features for tasks without human labels. Enhanced in DINOv2 by Meta AI, it uses improved training and data pipelines, setting a new standard for computer vision foundation models
CLIP Tutorial To Leverage Open AI's CLIP Model For Fashion Industry Discover how fine-tuning CLIP model can revolutionize fashion image recognition. Learn to optimize OpenAI's CLIP with domain-specific data for the fashion industry.
technology Understanding YOLOv8 Architecture, Applications & Features YOLOv8, the latest evolution of the YOLO algorithm, leverages advanced techniques like spatial attention and context aggregation, achieving enhanced accuracy and speed in object detection. This blog covers YOLOv8's architecture, applications, and unique features.
computer vision Vision Transformers For Object Detection: A Complete Guide Learn how ViT object detection models outperform traditional architectures by leveraging hierarchical layers. Discover the benefits of vision transformers in image segmentation and object recognition with detailed steps for fine-tuning and implementation
technology Evolution of Neural Networks to Large Language Models Explore the evolution from neural networks to large language models, highlighting key advancements in NLP with the rise of transformer models.
Machine Learning How to Build an End-to-End ML Pipeline This guide covers building an end-to-end ML pipeline in Python, from data preprocessing to model deployment, using Scikit-learn. It emphasizes automation, efficiency, and scalability with hands-on steps for data exploration, model selection, and prediction generation.
Large Language Models Training Small-Scale Vs Large-Scale Language Models: The Difference Explore the contrasts between training small and large-scale language models, from data requirements and computational power to model complexity and performance nuances in NLP applications
computer vision Recognize Anything: A Large Model For Multi Label Tagging Explore the Recognize Anything Model (RAM), a cutting-edge solution for multi-label image tagging. RAM integrates high-quality data, a universal label system, and transformer-based architecture for enhanced recognition, enabling broader, zero-shot image tagging.
Large Language Models Everything You Need To Know About Fine Tuning of LLMs Fine-tuning LLMs customizes pre-trained models for specific tasks by adjusting parameters with new data, enhancing model precision and relevance across unique applications from legal analysis to healthcare.
data annotation Evolution of YOLO Object Detection Model From V5 to V8 Introduction Imagine you're trying to build an object detection system for an autonomous vehicle, only to find that traditional methods struggle with accuracy, speed, or both. Imagine you're trying to build an object detection system for an autonomous vehicle, only to find that traditional methods struggle
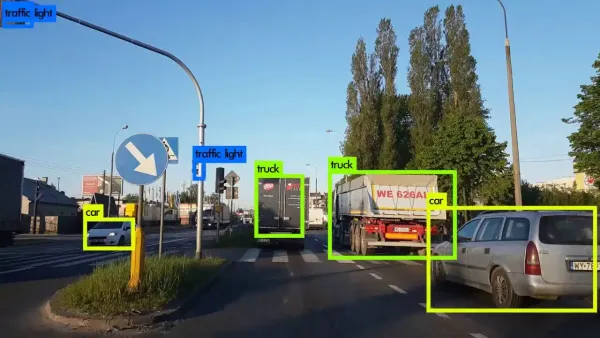
tutorial Create Object Detection Model Using Python & Open CV Learn to build real-time object detection with Python, OpenCV, and YOLOv5. This guide walks you through environment setup, using PyTorch's YOLOv5 for object recognition, and displaying labeled detections for safer driving applications.
computer vision Exploring the COCO Dataset and its Applications The COCO (Common Objects in Context) dataset is a cornerstone for computer vision, providing extensive annotated data for object detection, segmentation, and captioning tasks. Discover its features and applications.
Language Models Exploring Architectures and Configurations for Large Language Models (LLMs) Large Language Models (LLMs) like GPT-4 excel in NLP tasks through advanced architectures, including encoder-decoder, causal decoder, and prefix decoder. This article delves into their configurations, activation functions, and training stability for optimal performance.
technology Development Of Large Language Models: Methods and Challenges Explore key techniques and challenges in developing large language models (LLMs) like GPT-4, from scaling laws to alignment tuning. Discover datasets and resources that enhance LLM capabilities in NLP applications.
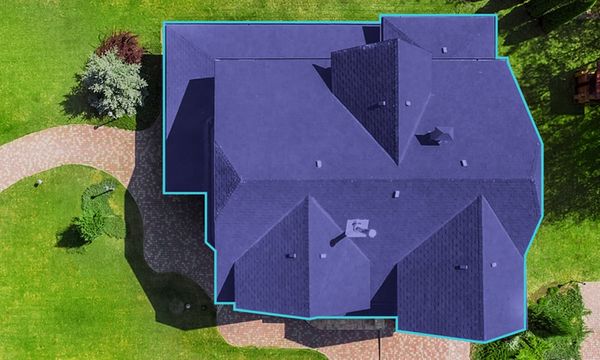
computer vision Future Prospects Of Image Annotation Image annotation involves labeling images within a dataset to train machine learning models. Once manual annotation is done, a machine learning or deep learning model processes the labeled images to replicate the annotations autonomously. This sets the standards for the model, making precise image annotation crucial for training neural networks
computer vision Image Annotation Solving Real-World Problems In our previous series of blogs, we have studied Image Annotation and its basics, covering Introduction to Image Annotation, highlighting its critical role in Why Image Annotation is Crucial for AI and ML, and presenting an overview of Types of Image Annotation. We also underwent techniques encompassing Manual Image Annotation,
data annotation Future Trends in Image Annotation Image annotation involves adding labels to images to facilitate AI and machine learning model training. Typically, human annotators use specialized tools to mark images, attaching relevant information, such as assigning specific classes to various entities within an image. The resultant structured data is then utilized to train a machine learning
data annotation Regulations and Ethical Considerations in Image Annotation When we talk about annotating data, like images or text, it's important to be fair. This means ensuring the labels accurately show what's in the data and not favor specific people or groups. For example, if we're labeling pictures of people, we should include
Image Annotation Image Annotation: Challenges & Their Solutions Creating a machine learning (ML) and artificial intelligence (AI) model that emulates human capabilities requires extensive training data. The model must be trained to recognize specific objects, enabling it to make informed decisions and take appropriate actions. The datasets used for training must be meticulously categorized and labeled according to
computer vision A Detailed Guide To Best Practices In Image Annotation In our previous blogs, we learn about what image annotation is and saw an overview of where Image Annotation can be applied. Image annotation plays a pivotal role in the training of machine learning models, as the accuracy of annotations is essential for your model's ability to identify
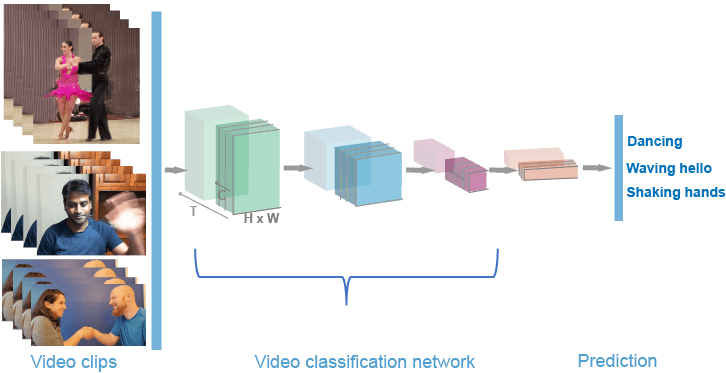
computer vision Tutorial On Using Vision Transformers In Video Classification Explore using Vision Transformers in video classification with this tutorial by Akshit Mehra. Learn to adapt image models to handle sequences of frames, utilizing ViViT and the OrganMNIST3D dataset for effective video analysis.
computer vision Vision Transformers For Identification of Healthy and Diseased Leaves - Tutorial This blog shows how we can utilize a vision transformer for an Image classification tasks. Particularly, we use Leaf disease classification dataset.