

Exploring Architectures and Configurations for Large Language Models (LLMs)
Large Language Models (LLMs) like GPT-4 excel in NLP tasks through advanced architectures, including encoder-decoder, causal decoder, and prefix decoder. This article delves into their configurations, activation functions, and training stability for optimal performance.


Introduction
Language models have become increasingly successful in recent years, especially large language models (LLMs) like GPT-4.
These models have shown remarkable abilities in various natural language processing (NLP) tasks, such as text generation, language translation, question-answering, and more.
Their success can be attributed to their ability to learn from large amounts of text data and sophisticated architecture and training methods.
Moreover, LLMs have opened up new possibilities for various applications in artificial intelligence (AI) and NLP. For example, they have been used to improve chatbots, automated content generation, and voice assistants.
In this blog, we discuss the architecture design of Language Models (LLMs), including the mainstream architecture, pre-training objective, and detailed configuration.
The Transformer architecture is widely used for LLMs due to its parallelizability and capacity, enabling the scaling of language models to billions or even trillions of parameters.
Existing LLMs can be broadly classified into three types: encoder-decoder, causal decoder, and prefix decoder.
Table of Contents
General Architecture
As discussed above, the existing LLMs can be broadly classified into 3 types: encoder-decoder, causal decoder, and prefix decoder.
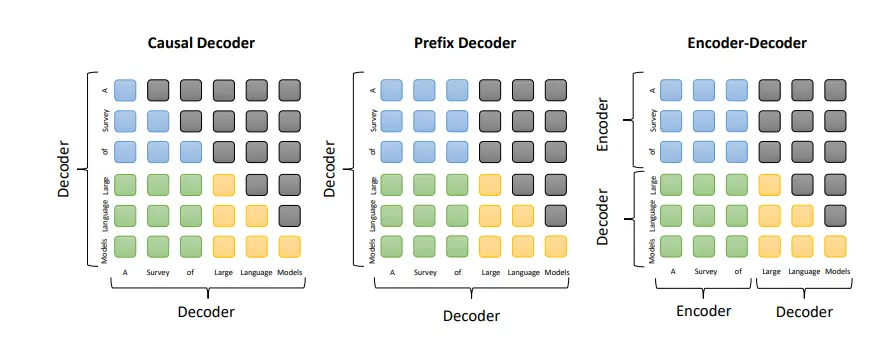
Figure 1: Examining the attention patterns of three prominent architectures reveals distinct differences. The attention between prefix tokens, attention between prefix and target tokens, attention between target tokens, and masked attention are represented by rounded rectangles in blue, green, yellow, and grey colors, respectively.
Encoder-Decoder Architecture
Based on the vanilla Transformer model, the encoder-decoder architecture consists of two stacks of Transformer blocks - an encoder and a decoder.
The encoder utilizes stacked multi-head self-attention layers to encode the input sequence and generate latent representations. The decoder performs cross-attention on these representations and generates the target sequence.
Encoder-decoder PLMs like T5 and BART have demonstrated effectiveness in various NLP tasks. However, only a few LLMs, such as Flan-T5, are built using this architecture.
Causal Decoder Architecture
The causal decoder architecture incorporates a unidirectional attention mask, allowing each input token to attend only to past tokens and itself. Both the input and output tokens are processed in the same manner within the decoder.
The GPT-series models, including GPT-1, GPT-2, and GPT-3, are representative language models built on this architecture. GPT-3 has shown remarkable in-context learning capabilities.
Various LLMs, including OPT, BLOOM, and Gopher have widely adopted causal decoders.
Prefix Decoder Architecture
The prefix decoder architecture, also known as the non-causal decoder, modifies the masking mechanism of causal decoders to enable bidirectional attention over prefix tokens and unidirectional attention on generated tokens.
Like the encoder-decoder architecture, prefix decoders can encode the prefix sequence bidirectionally and predict output tokens autoregressively using shared parameters.
Instead of training from scratch, a practical approach is to train causal decoders and convert them into prefix decoders for faster convergence. LLMs based on prefix decoders include GLM130B and U-PaLM.
All three architecture types can be extended using the mixture-of-experts (MoE) scaling technique, which sparsely activates a subset of neural network weights for each input.
This approach has been used in models like Switch Transformer and GLaM, and increasing the number of experts or the total parameter size has shown significant performance improvements.
Detailed Configurations
Since introducing the Transformer model, researchers have made several advancements to improve its training stability, performance, and computational efficiency.
In this section, we will examine the configurations related to four crucial components of the Transformer: normalization, position embeddings, activation functions, and attention and bias.
Normalization
To address the issue of training instability in pre-training Language Models (LLMs), layer normalization (LN) has been widely used in Transformer architectures.
The position of LN is crucial for LLM performance. While the original Transformer model used post-LN, most LLMs employ pre-LN to achieve more stable training, even though it may slightly decrease performance.
Researchers introduced additional LN layers, known as Sandwich-LN, before residual connections to prevent value explosion. However, observations reveal that Sandwich-LN sometimes fails to stabilize LLM training and may cause training collapse.
Models like Gopher and Chinchilla use alternative normalization techniques like RMS Norm for faster training and better performance.GLM-130B adopts DeepNorm, which offers better stability in training through post-normalization.
Adding an extra LN after the embedding layer can also stabilize LLM training but often results in a significant performance drop, leading to its exclusion in recent LLMs.
Activation Functions
To achieve good performance in feed-forward networks, selecting activation functions is crucial. GeLU activations are commonly used in existing LLMs.
Furthermore, recent LLMs such as PaLM and LaMDA have employed variants of GLU activation, particularly the SwiGLU and GeGLU variants, which have demonstrated better performance in practical applications.
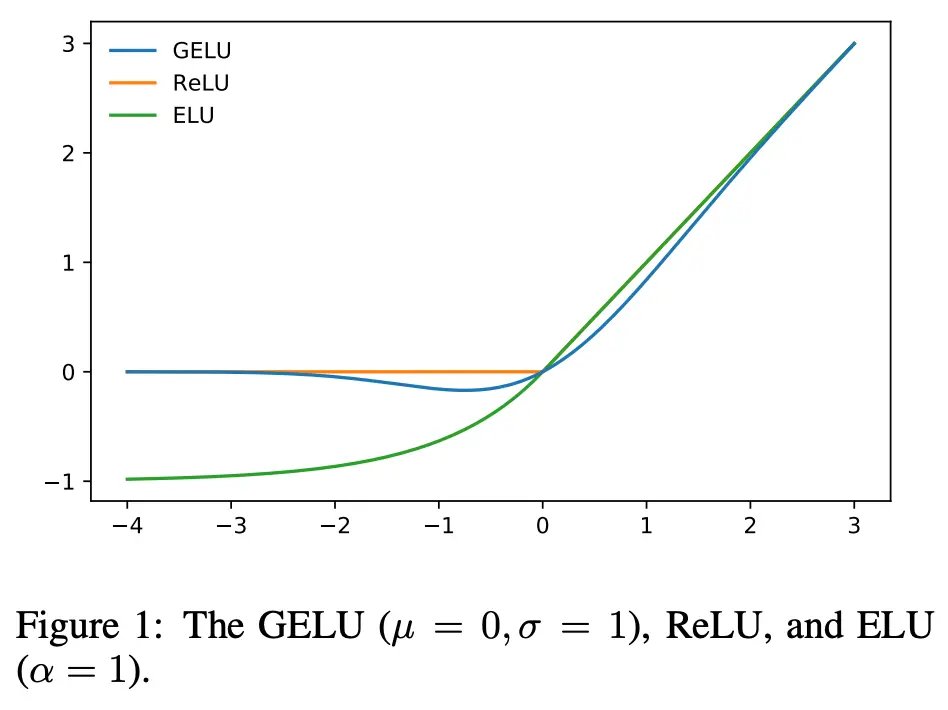
Figure 2: Activation Function Comparison
However, these variants require additional parameters (approximately 50%) in the feed-forward networks compared to GeLU activations.
Positional Embeddings
Position embeddings are used in Transformers to incorporate absolute or relative position information in modeling sequences since the self-attention modules are permutation equivariant.
The vanilla Transformer has two absolute position embeddings: sinusoids and learned position embeddings. LLMs commonly utilize learned position embeddings.
On the other hand, relative positional encodings generate embeddings based on the offsets between keys and queries. This allows them to perform well on longer sequences, even ones beyond the lengths encountered during training, enabling extrapolation.
ALiBi introduces a penalty based on the distance between keys and queries to bias attention scores, resulting in better zero-shot generalization and stronger extrapolation capabilities than other position embeddings.
RoPE, on the other hand, uses rotatory matrices based on absolute positions to compute scores between keys and queries, incorporating relative position information for modeling long sequences. Recent LLMs widely adopt RoPE as a consequence of its benefits.
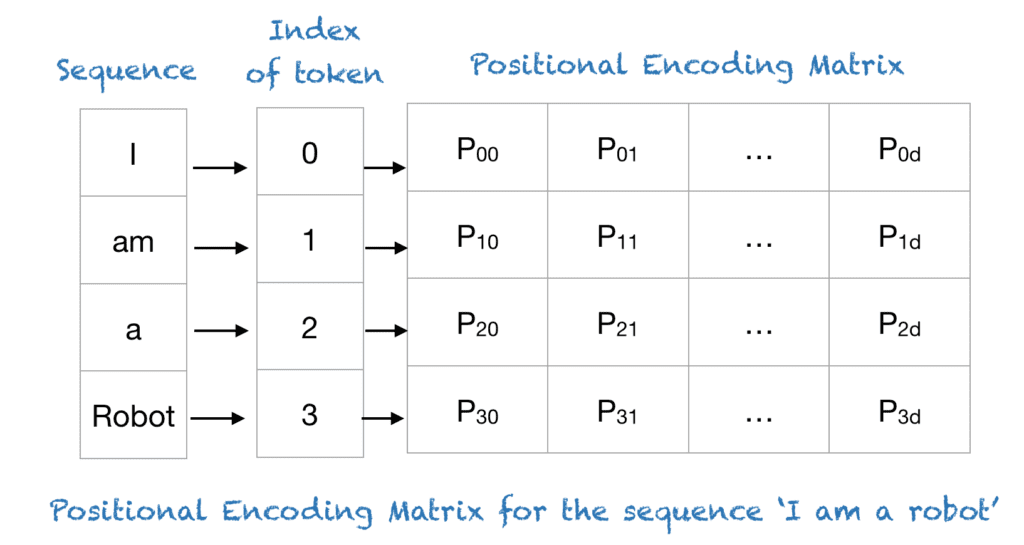
Figure 3: Positional Embedding
Attention and Bias
In addition to the full self-attention mechanism in the original Transformer, GPT-3 utilizes sparse attention, specifically Factorized Attention, to reduce computation complexity.
Researchers explore various approaches to effectively model longer sequences, including introducing special attention patterns or optimizing GPU memory access, as seen in models like FlashAttention.
Moreover, while biases are typically included in each dense kernel and Layer Norm following the original Transformer, recent LLMs like PaLM and Galactica have removed biases. Removing biases improves training stability in LLMs, as demonstrated in studies.
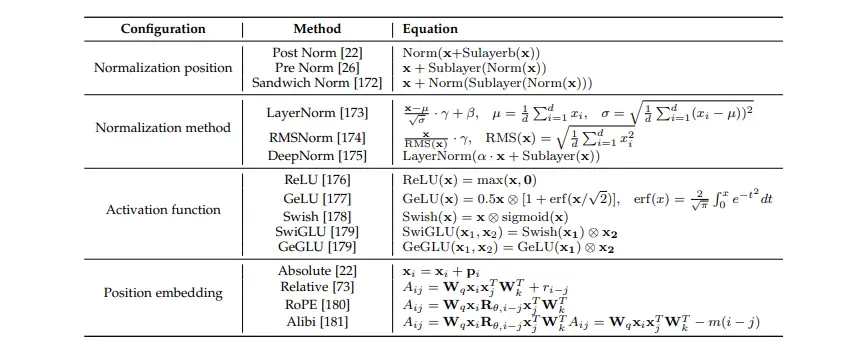 Detailed formulations for the network configurations.
Detailed formulations for the network configurations.
Figure 4: Detailed formulations for the network configurations.
To summarize the suggestions from existing literature regarding detailed configuration for Language Models (LLMs): for stronger generalization and training stability, it is recommended to use pre-RMS Norm for layer normalization and SwiGLU or GeGLU as the activation function.
It is advised not to use LN immediately after embedding layers as it may lead to performance degradation.
Regarding position embeddings, RoPE or ALiBi is a better choice as they perform well on long sequences.
Conclusion
Large language models (LLMs) have changed how we solve natural language tasks, thanks to improvements in their design and training methods. Key advancements like better model architectures, smarter attention mechanisms, and efficient training techniques are shaping the future of AI.
What do you think will be the next big breakthrough in LLMs?
As these models improve, areas like handling long sequences and making them more efficient will remain important.
For more in-depth articles and the latest insights on large language models, check out the LLM Blog Series.
Frequently Asked Questions (FAQ)
1. What are large language models (LLMs)?
Large language models (LLMs) are powerful artificial intelligence models that excel in natural language processing tasks. They are trained on vast amounts of text data and have shown remarkable capabilities in tasks like text generation, language translation, and question-answering.
2. How do LLMs contribute to advancements in AI and NLP?
LLMs have opened up new possibilities in AI and NLP applications. They have improved chatbots, automated content generation, and voice assistants. LLMs have also enhanced various NLP tasks, enabling more accurate language understanding and generation.
3. What are the different types of LLM architectures?
LLM architectures can be broadly classified into three types: encoder-decoder, causal decoder, and prefix decoder. Each type has its own advantages and has been used in different LLM models for specific purposes.
4. Which activation functions are commonly used in LLMs?
GeLU (Gaussian Error Linear Unit) activations are commonly used in existing LLMs. However, recent models like PaLM and LaMDA have employed variants of GLU (Gated Linear Unit) activation, such as SwiGLU and GeGLU, which have shown better performance in practical applications.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
