Video Annotation Platform To Label 10X Faster
With Labellerr’s AI-assisted video annotation platform, perform object tracking, segmentation, and detection with ease.
Book a demo

Designed for Precision
From semantic segmentation to creating your own custom annotation, Labellerr ensures your data is always model-ready with its advanced video annotation platform.
Easily apply semantic segmentation to your video data. Label every pixel in a frame, from key objects to background elements, and ensure your models capture every detail with the help of our video annotation platform.


Easily apply semantic segmentation to your video data. Label every pixel in a frame, from key objects to background elements, and ensure your models capture every detail.



Built to Scale with You

Label and track key points on objects, such as joints or landmarks, to capture complex movements and poses with our video annotation platform.

Label objects with complex or irregular shapes by creating custom, multi-point boundaries.

Precisely label linear structures like roads or pipelines by drawing parallel lines in each video frame using lane annotation.

Annotate specific points of interest within an object, such as facial landmarks, joints, or object corners.

Identify and label objects with hollow spaces like rings or tires that can’t be accurately captured with simple shapes using Labellerr's video annotation platform.

Labellerr allows ML teams to combine annotation methods to create custom video training datasets for specific needs using the video annotation platform.
Free Data Annotation Workflow Plan
.webp)





Supervise Annotation Project With Advanced Analytics Dashboard
Manage image annotation projects with a comprehensive dashboard to track progress and quality using Labellerr’s efficient video annotation platform.

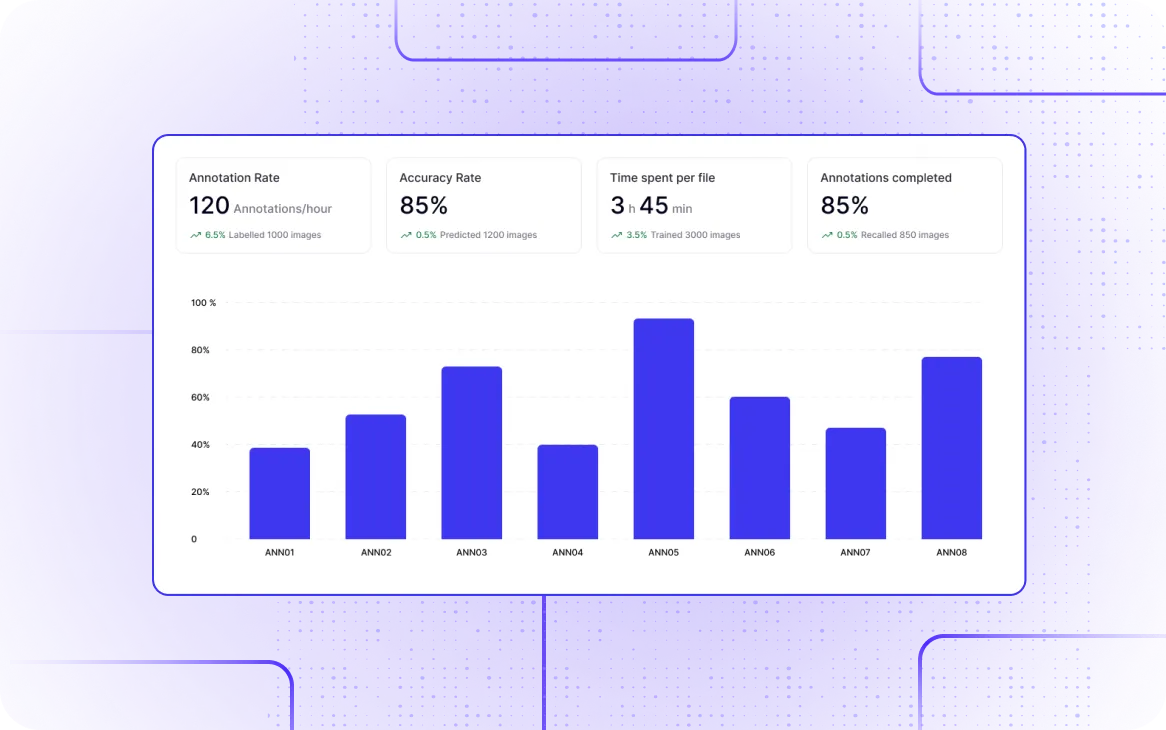
Track time spent per file, annotations completed, and accuracy in real-time for each annotator.

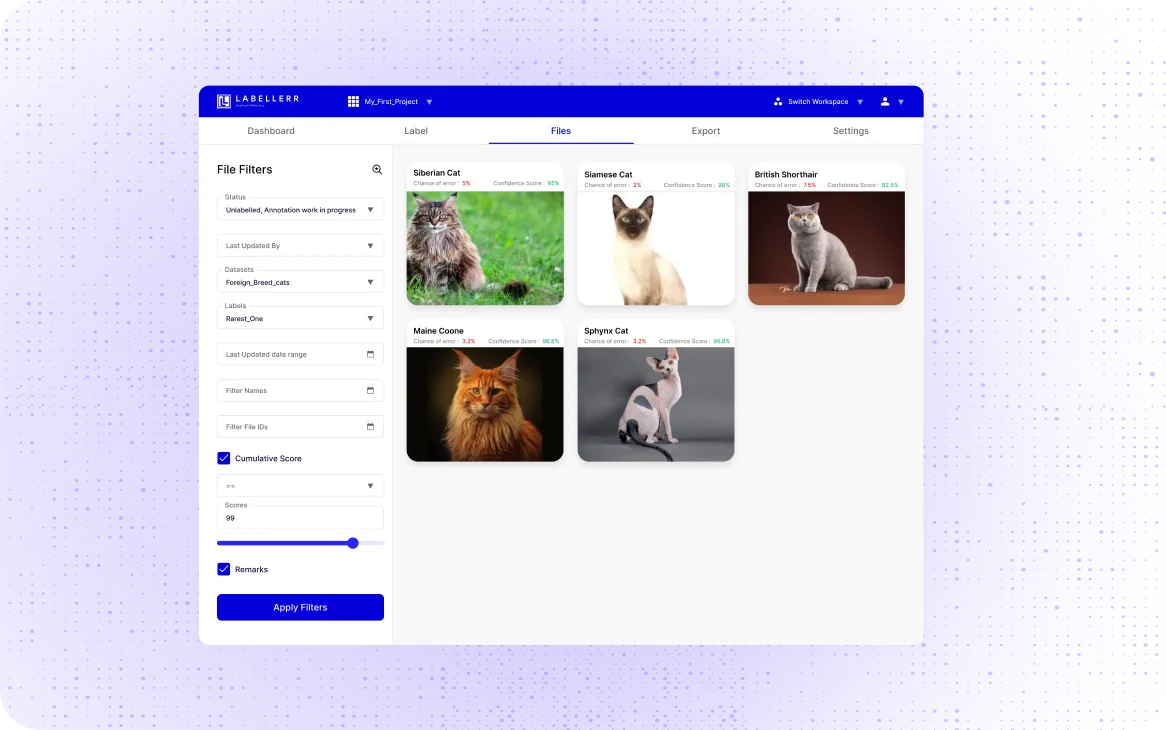
Add consensus between annotators to automatically improve the accuracy, model-assisted QA, and more.

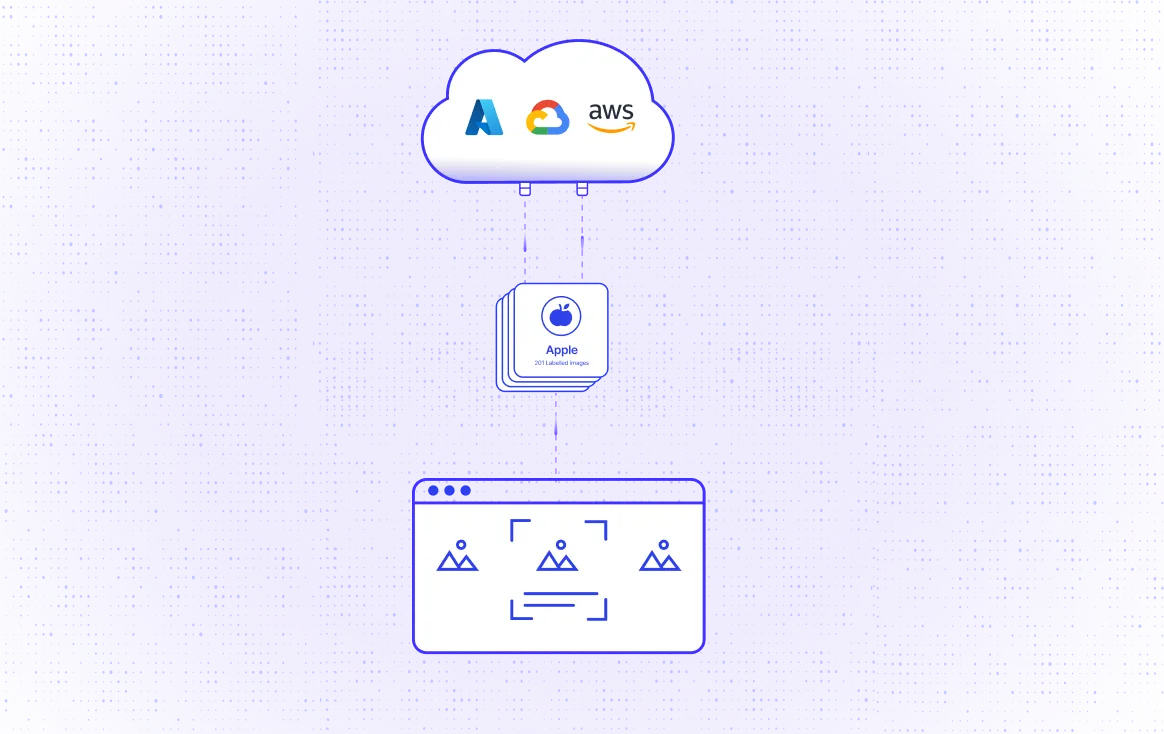
Export of Data
Create a batch run on your data import/export with the cloud and save time using Labellerr's video annotation platform.





















