

Exploring the COCO Dataset and its Applications
The COCO (Common Objects in Context) dataset is a cornerstone for computer vision, providing extensive annotated data for object detection, segmentation, and captioning tasks. Discover its features and applications.


Table of Contents
- Introduction
- Key Features of the COCO Dataset
- COCO Dataset Formats
- Analysis of the COCO Dataset
- Applications of COCO Dataset
- Conclusion
- Frequently Asked Questions
Introduction
The COCO (Common Objects in Context) dataset is a widely used benchmark dataset in computer vision. It was created to facilitate the developing and evaluation of object detection, segmentation, and captioning algorithms.
The COCO dataset consists of an extensive collection of images that depict everyday scenes with various objects in different contexts.
The dataset contains over 200,000 images, covering 80 object categories, such as people, animals, vehicles, household items, and more.

Figure: Samples of annotated images in the MS COCO dataset
Each image is carefully annotated with bounding box coordinates and segmentation masks, providing precise information about the location and shape of the objects present in the scene.
In addition to object annotations, the COCO dataset includes captions for a subset of the images. These captions are human-generated textual descriptions that provide a contextual understanding of the objects and activities depicted in the images.
The COCO dataset has become a standard benchmark for evaluating the performance of computer vision models and algorithms, particularly in object detection, instance segmentation, and image captioning.
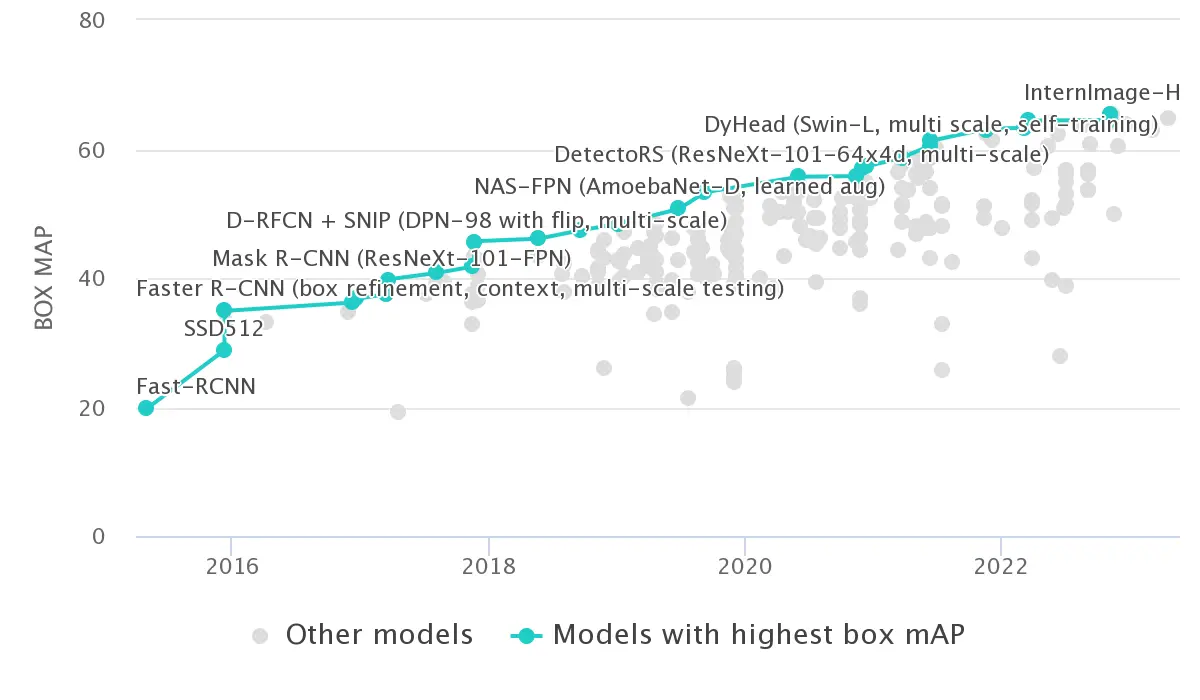
Figure: BOX MAP metric vs. Different Models
Its size, diversity, and detailed annotations make it a valuable resource for training and evaluating models on various visual recognition tasks.
Researchers and developers often use the COCO dataset to benchmark their algorithms, compare results, and advance the state-of-the-art in computer vision.
It has played a significant role in advancing the field by enabling the development of more accurate and robust models for object detection, segmentation, and image understanding tasks.
Key features of the COCO Dataset
The COCO dataset includes detailed annotations for object segmentation and recognition in context.
It consists of 330,000 images, with over 200,000 images having labels for 1.5 million object instances.
These annotations cover 80 object categories referred to as "COCO classes," which include easily labelable individual instances such as people, cars, chairs, and more.
Additionally, 91 "COCO stuff" categories representing materials and objects with less defined boundaries, such as sky, street, grass, and others, provide valuable contextual information.
Each image in the COCO dataset is accompanied by five captions, contributing to 1.5 million captions. Moreover, the dataset includes annotations for 250,000 people with 17 key points widely used for pose estimation tasks.
For more information about the COCO dataset, you can refer here.
COCO Dataset Formats
The data in COCO is stored in a JSON file structured into sections such as info, licenses, categories, images, and annotations. Generating individual JSON files for training, testing, and validation is possible, allowing for distinct datasets for each specific purpose.
Info
This format aims to provide a high-level description of the dataset.
"info": {
"year": int,
"version": str,
"description": str,
"contributor": str,
"url": str,
"date_created": datetime
}Licenses
This format contains the list of image licenses that apply to images in the dataset.
"licenses": [{
"id": int,
"name": str,
"url": str
}]Categories
This aims to provide categories and supercategories.
"categories": [{
"id": int,
"name": str,
"supercategory": str,
"isthing": int,
"color": list
}]Images
Image format contains the image information in the dataset without a bounding box or segmentation information.
"image": {
"id": int,
"width": int,
"height": int,
"file_name": str,
"license": int,
"flickr_url": str,
"coco_url": str,
"date_captured": datetime
}Annotations
This format lists every object annotation from each image in the dataset.
"annotations": {
"id”: int,
"image_id": int,
"category_id": int
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y, width,height],
"iscrowd": 0 or 1
}
Analysis of the COCO Dataset
In the below section, we analyze the COCO Dataset from various aspects, including Key point annotation, Image Segmentation, Image Captioning, etc.
Image Captioning
The captions in the COCO dataset provide textual descriptions that go beyond the object annotations. They offer additional information about the scene, activities, object relationships, and other contextual details.
This makes the dataset valuable for training models to understand images at a semantic level and generate meaningful and accurate captions.
Researchers and developers often use the COCO dataset for training and evaluating image captioning models.
By leveraging the image-caption pairs, models can learn to associate visual features with corresponding textual descriptions, enabling them to generate captions that align with the content and context of the images.
Below attached is a sample Image along with its caption.

Figure: A Sample Image from dataset
Bounding Box Annotations
The COCO (Common Objects in Context) dataset annotates bounding boxes and segmentations, making it suitable for object localization and segmentation tasks.
Bounding Box Annotations: COCO includes precise bounding box annotations for objects in the dataset. Each object instance in an image is annotated with a bounding box, represented by its top-left and bottom-right corners coordinates.
These bounding boxes define the spatial extent of the objects in the image, allowing models to localize and identify them accurately.
Segmentation Annotations: In addition to bounding boxes, the COCO dataset provides segmentation annotations that offer pixel-level masks for object instances.
These segmentation masks outline the exact boundaries of objects, providing detailed and fine-grained information about their shapes. Each pixel within the mask is labeled as belonging to a particular object instance or background.

Figure: Bounding Box using the COCO Dataset
Keypoint Annotations
The COCO (Common Objects in Context) dataset contains annotations for key points, specifically for human instances in a subset of images.
These key points indicate the spatial positions of various body parts, enabling tasks like human pose estimation and activity recognition.
The COCO dataset annotates key points for approximately 250,000 individuals across multiple images. They represent specific landmarks on the human body, including the head, shoulders, elbows, wrists, hips, knees, and ankles.
Each key point is assigned a label corresponding to its body part and is associated with its respective spatial coordinates.
The availability of keypoint annotations in COCO facilitates the development of models that can understand the spatial relationships between different body parts and accurately estimate human poses depicted in images.

Figure: Key Point annotations available in COCO Dataset
Human pose estimation has practical applications in several fields, such as action recognition, human-computer interaction, sports analysis, and augmented reality.
By incorporating key point annotations, the COCO dataset enables researchers and developers to train and evaluate models for pose estimation and related tasks. This contributes to a better understanding human activities and interactions in visual data.
Applications of COCO Dataset
The COCO (Common Objects in Context) dataset is widely used in the field of computer vision for a variety of purposes. Here are some typical applications and tasks for which COCO is used:
- Object Detection: COCO is often used for training and evaluating object detection algorithms. The dataset's annotations, including bounding box coordinates, enable the development of models that can accurately identify and localize objects in images.
- Instance Segmentation: With its detailed segmentation annotations, COCO is also utilized for training instance segmentation models. These models detect and segment objects at the pixel level, providing a more precise understanding of object boundaries.
- Semantic Segmentation: The COCO dataset's segmentation annotations can be used to train models for semantic segmentation. This task involves assigning semantic labels to each pixel in an image, enabling a fine-grained understanding of scene composition.
- Object Recognition: COCO supports training and evaluating models for object recognition or image classification. The dataset's diverse range of object categories allows models to learn to recognize and classify various objects accurately.
- Image Captioning: Besides object annotations, COCO includes human-generated captions for a subset of images. This makes it suitable for training models to generate descriptive and contextual captions given an input image.
- Benchmarking and Evaluation: COCO serves as a benchmark dataset for evaluating the performance of computer vision models. Researchers and developers compare their algorithms against established metrics on the COCO dataset to assess their accuracy, robustness, and generalization capabilities.

Figure: Different applications of COCO Dataset
The COCO dataset thus offers a rich resource for developing, training, and evaluating various computer vision tasks, including object detection, segmentation, recognition, image captioning, and more.
Its size, diversity, and detailed annotations make it a valuable asset in advancing the field of computer vision and fostering the development of more accurate and sophisticated models.
Conclusion
To conclude, the COCO dataset is a widely used benchmark dataset in computer vision, offering a diverse collection of images with precise annotations for object detection, segmentation, and image captioning.
It provides detailed bounding box annotations, segmentation masks, and captions, enabling the development and evaluation of models across various visual recognition tasks.
Additionally, the dataset includes keypoint annotations for human instances, supporting tasks like pose estimation and activity recognition.
The COCO dataset has played a significant role in advancing computer vision research and serves as a standard benchmark for evaluating the performance of models in the field.
Its comprehensive features and annotations make it a valuable resource for training and evaluating models on various visual recognition tasks.
Frequently Asked Questions
What is COCO Dataset Used For?
The COCO dataset is a highly utilized resource in computer vision research. It serves as a valuable tool for training and evaluating cutting-edge models for object detection and segmentation. Comprised of images and their associated annotations, the dataset plays a significant role in advancing the field of computer vision.
How many images are in the Coco dataset?
The MS COCO (Microsoft Common Objects in Context) dataset is an extensive collection of data used for object detection, segmentation, key-point detection, and captioning tasks. It encompasses 328,000 images, making it a substantial resource for training and evaluation purposes.
What is the image size of the COCO dataset?
The images in the COCO dataset have a resolution of 640×480 pixels.
What is Coco in computer vision?
COCO, short for Common Objects in Context, is a computer vision database designed to support various research tasks such as object detection, instance segmentation, image captioning, and person key points localization. Its purpose is to facilitate and advance future research in these areas.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
