

Automating object detection AI development with Labellerr


If you're a data scientist working in the AI and machine learning space, then you know how time-consuming it can be to label datasets manually. This process is critical for training object detection algorithms, but automation becomes essential with traditional methods of labeling datasets, often taking days or even weeks to complete.
Labellerr provides an intelligent solution that streamlines this tedious process and helps developers accelerate their object detection AI development without sacrificing accuracy.
Read on to learn more about Labellerr's automated object annotation capabilities and how they are revolutionizing the way we approach data set production.
Let’s first understand, What object detection is?
About Object Detection
A computer vision technology called object detection helps locate and identify things in an image or video. To be more precise, object detection creates bounding boxes all around items it has found, allowing us to determine their location inside (or how they move across) a scene. Before we continue, it's crucial to clarify the distinctions between object detection and picture recognition, as they are sometimes misconstrued.
An image is given a label through image classification. The word "dog" is used to describe an image of a dog. The word "dog" is still used to describe an image of two canines. Contrarily, object detection surrounds each dog with a box that is labeled "dog." The model forecasts the location of each object and the appropriate label. Consequently, object detection offers more details about a picture than object recognition.
How does object detection work?
A computer vision technology called object detection helps locate and identify items in pictures and movies. It entails analyzing and categorizing the contents of an image or video using machine learning techniques and then drawing bounding boxes around any identified items.
There are several ways to detect items, but one common technique is to use a convolutional neural network (CNN) to examine photos and find traits that the objects of interest have. For instance, CNN might search for characteristics of human figures such as edges, forms, and textures if the objective is to identify pedestrians in an image.
The CNN can identify the items in the image and create bounding boxes around it once it has discovered these features. The items and their positions in the image can then be determined using the bounding boxes.
The particular method employed will vary depending on the specific applications and the needs of the work at hand. There are numerous distinct strategies and approaches for object identification.
Different approaches to object detection
There are various object detection methods, such as
- Traditional computer vision algorithms: Traditional computer vision algorithms employ hand-crafted features and heuristics to identify objects in images. Although they can be quicker and more effective, these techniques are typically less precise than machine learning techniques.
- Convolutional neural networks (CNNs): Convolutional neural networks (CNNs) are created specifically for object and image detection. CNN's may be trained to recognize characteristics of items of interest in images and use those features to classify and identify the objects depicted in the image.
.webp)
- Region-based CNNs (R-CNNs): Such CNNs use a sliding window method to find objects in images. If an object is found in one of the image's many overlapping regions, the CNN classifies it and draws a bounding box around it.
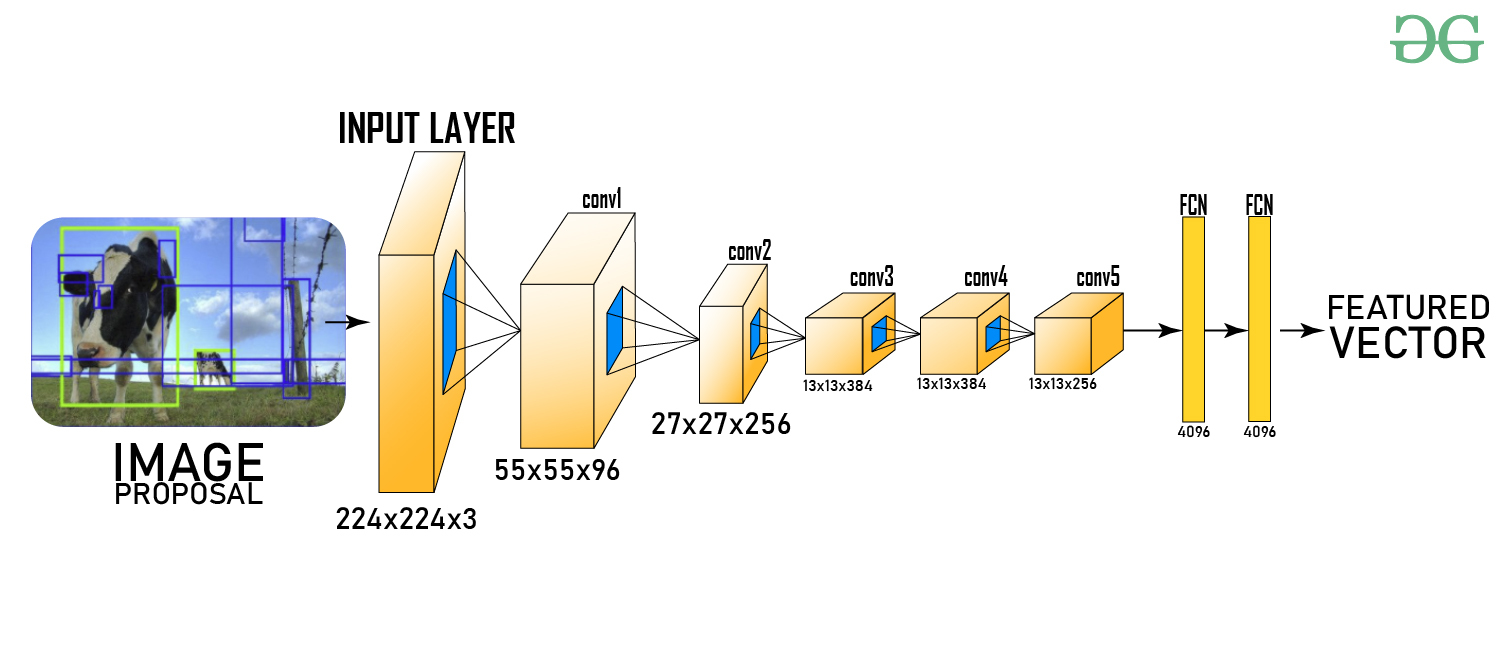
- You Only Look Once (YOLO): It is a real-time object identification technique that uses a single CNN to analyze the full image and forecast the kind and position of objects inside it.
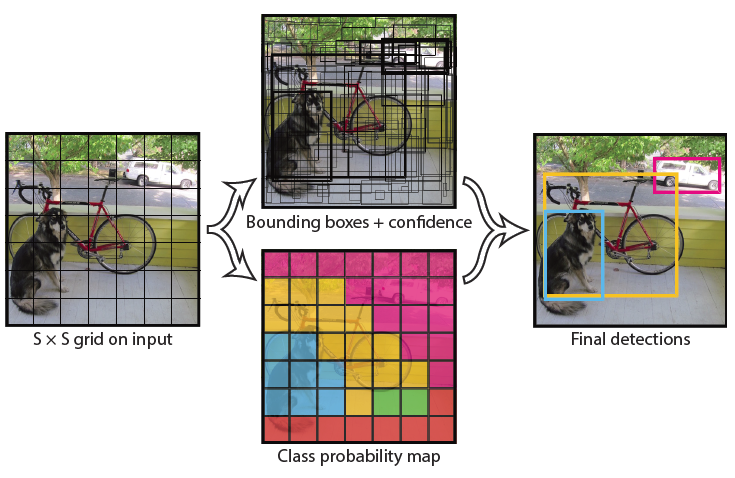
- Single Shot Detector (SSD): A single CNN is used by the Single Shot Detector (SSD) to predict the kind and location of objects in a photograph in real-time. It is speedier and more efficient than R-CNNs and YOLO, albeit it might necessitate greater accuracy.
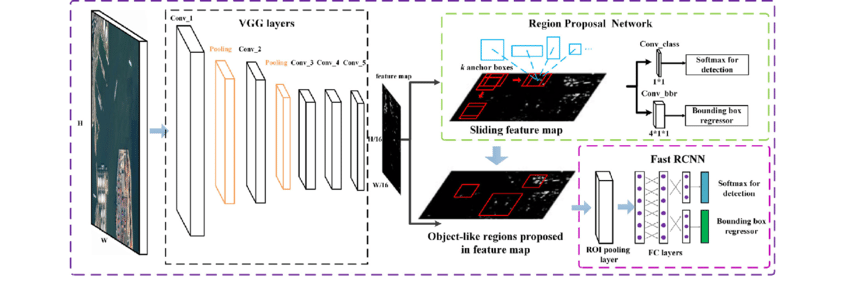
- Faster R-CNN: In this variation of R-CNN, a CNN is used faster to process a series of region proposals produced by a region proposal system to classify and find the objects within the image.
- Mask R-CNN: It is a development of the Faster R-CNN method that additionally anticipates a mask for every identified object, offering more specific details on its location and shape.
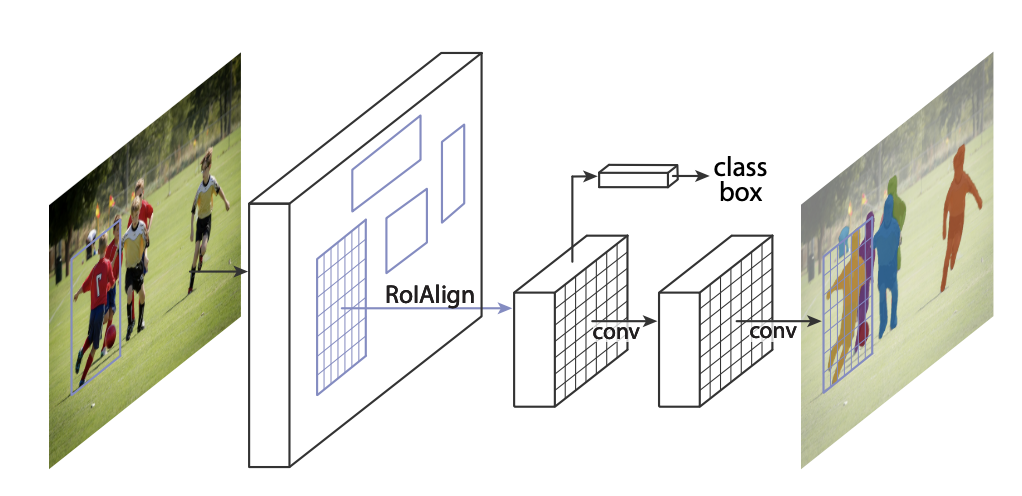
These are only a few of the several methods for object detection which have been created. Depending on the demands of the task at hand, such as the desired precision, speed, and efficiency, a particular approach will be employed.
How can you perform object detection on a training data platform?
On the training data platform, users will generally need to take the following actions to conduct object detection:
- Gather and label the training data: The initial stage is to gather a sizable dataset of pictures or videos that include the target objects. The dataset needs to be properly annotated all around the relevant objects. If you require the right help, we can assist you in bringing on board trained annotators to speed up your process.
- After gathering and labeling the training data, you must preprocess it to make it suitable for training. The photos or videos may be scaled, the pixel values may be normalized, and the data may be divided into training, approval, and test sets.
- Next, you must train a machine-learning model to use the training data for object detection.
- The model may need to be tweaked once it has been trained to perform better on the targeted items of interest. This can entail changing the model's parameters or including more network layers.
- Review the model: You must assess its effectiveness on the test set once it has been trained and tweaked to determine how effectively it can identify the objects of interest.
- Activate the model: You can activate the model to recognize objects in fresh images or videos after training and optimizing it to your satisfaction.
These are the fundamental steps in developing a model for object detection on a platform for training data. The particulars will vary depending on the platform you're using and your assignment's demands.
What are the benefits of using automated object detection?
Using automatic object detection has a number of advantages, including the following:
Efficiency gain: Automated object detection is more effective for activities that require analyzing several images or movies since it can analyze vast volumes of data considerably faster than humans can.
Accuracy is increased: Automated object detection techniques can be trained to detect objects with high accuracy, which lowers the possibility of human error-related mistakes and false positives.
Cost savings: Automated object recognition can eliminate manual labor requirements, lowering the cost of jobs that otherwise call for manual labor.
Enhanced extensibility: Automated object detection methods may be easily scaled up to analyze enormous amounts of data, enabling quick and accurate analysis of many photos or movies.
Safety is increased: Automated object detection can be employed to increase safety in various settings, such as spotting possible dangers in manufacturing settings or spotting pedestrians in autonomous vehicles.
Regarding efficiency, accuracy, affordability, scalability, and safety, automated object detection offers considerable advantages in various applications.
See it in action using Labellerr
Labellerr is here to avail the benefits of the automated object detection process. Our automated object detection feature allows you to work on exploratory data analysis and helps you gain actionable insights.
We have made it easier for you to detect labels. No need to annotate all the data manually. Go ahead and automate your processes with Labellerr.
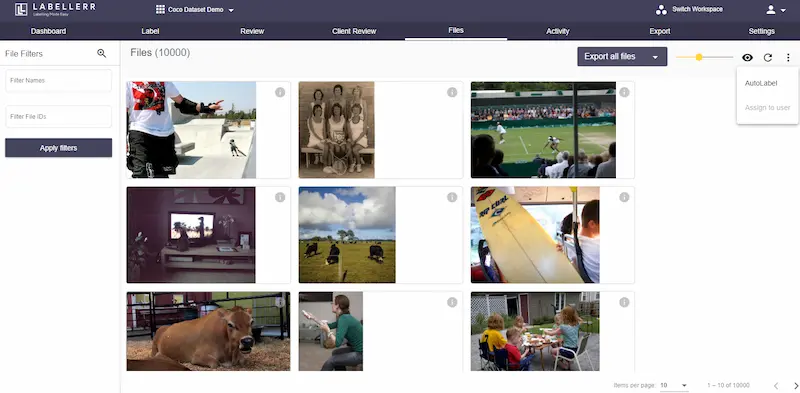
Here, is what you have to do to perform auto-labeling on our platform. Connect your data with our platform by various means be it through Google Drive, AWS data connector, or many more.
Next, move after connecting your datasets, go to the files tab and select the auto-label feature.
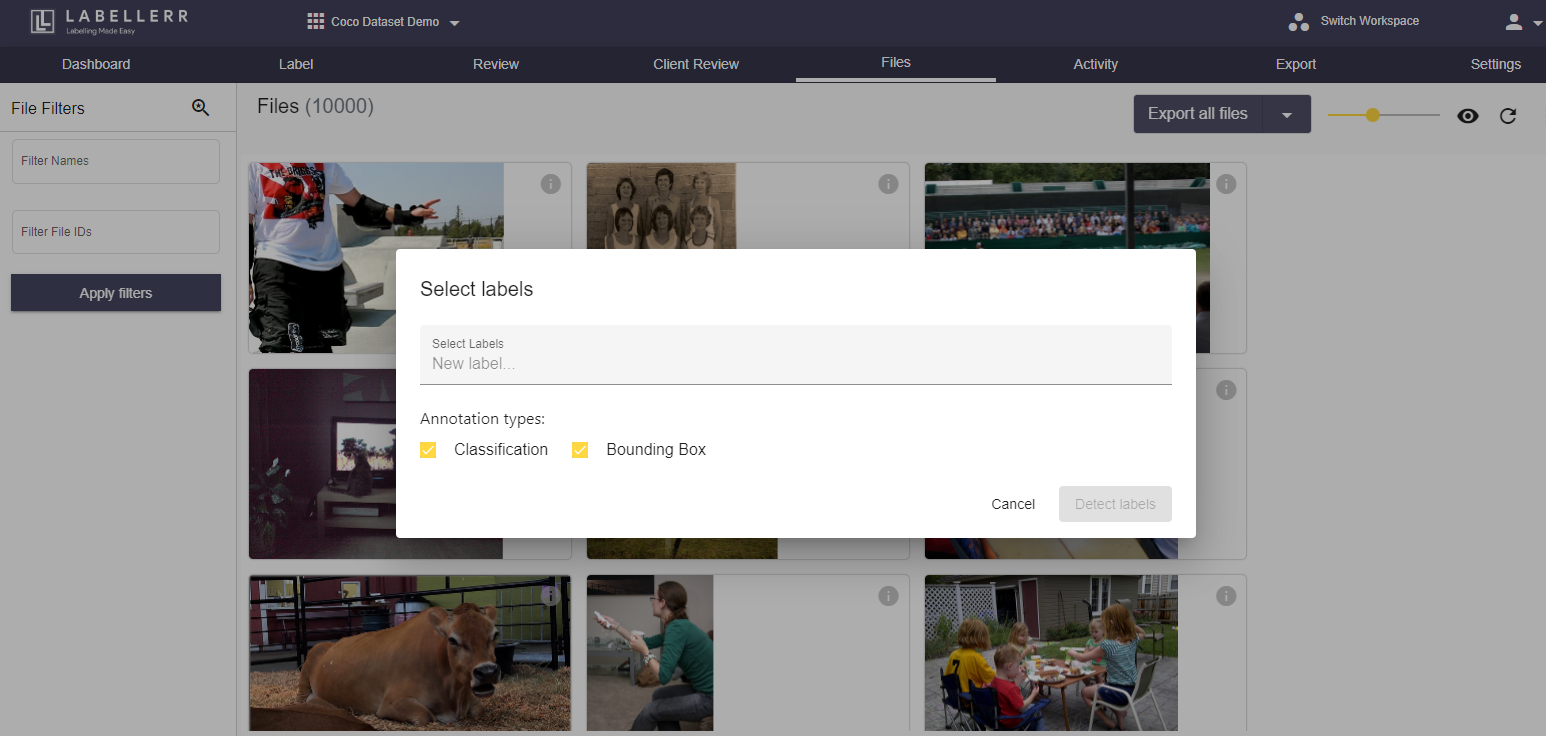
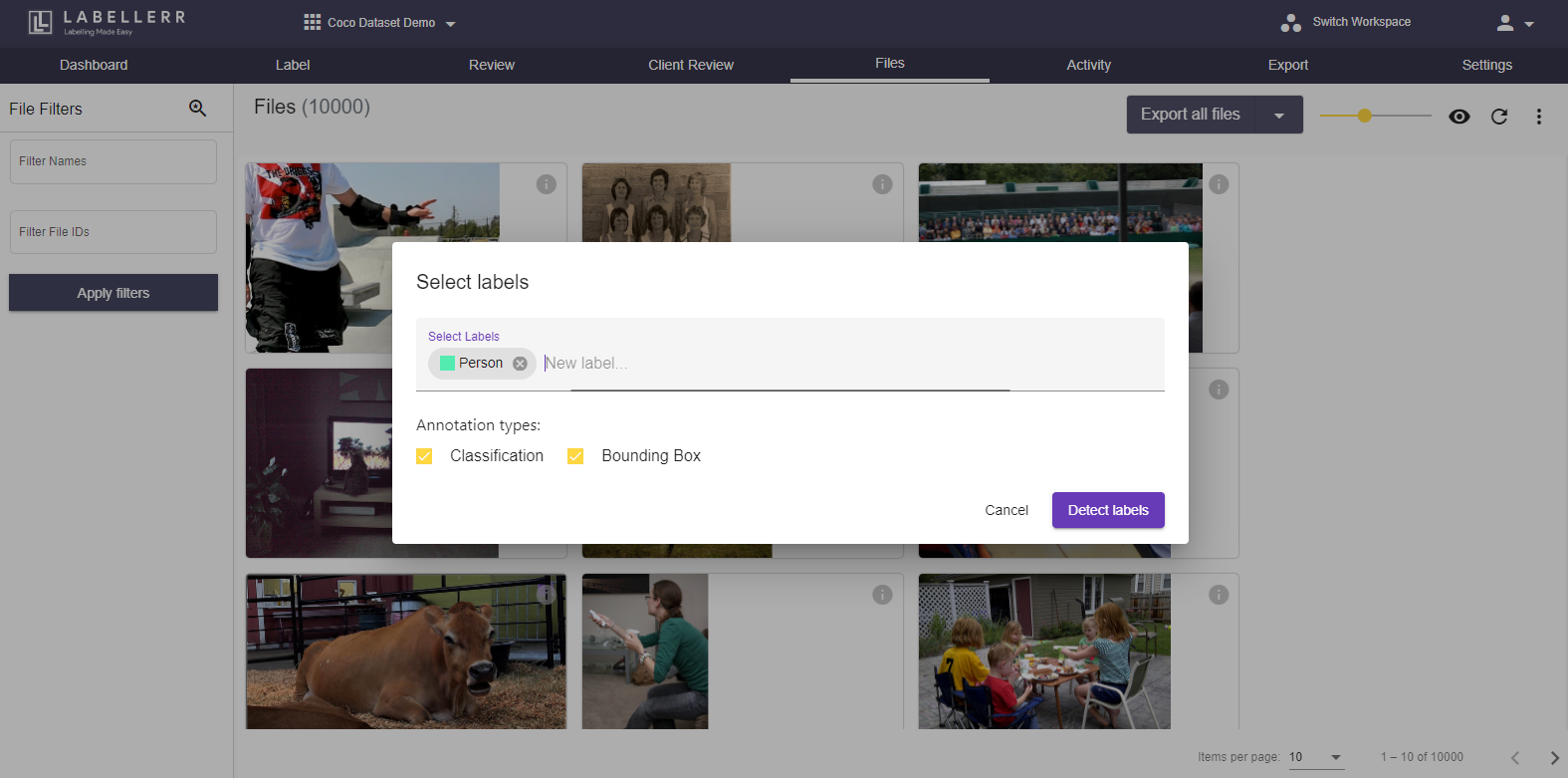
Then, select the label that you want to apply and go ahead with detecting labels.
The end result is what you have been looking for on different platforms. You will be able to see the annotated data alongside the analytics, recommendation, and dataset details.
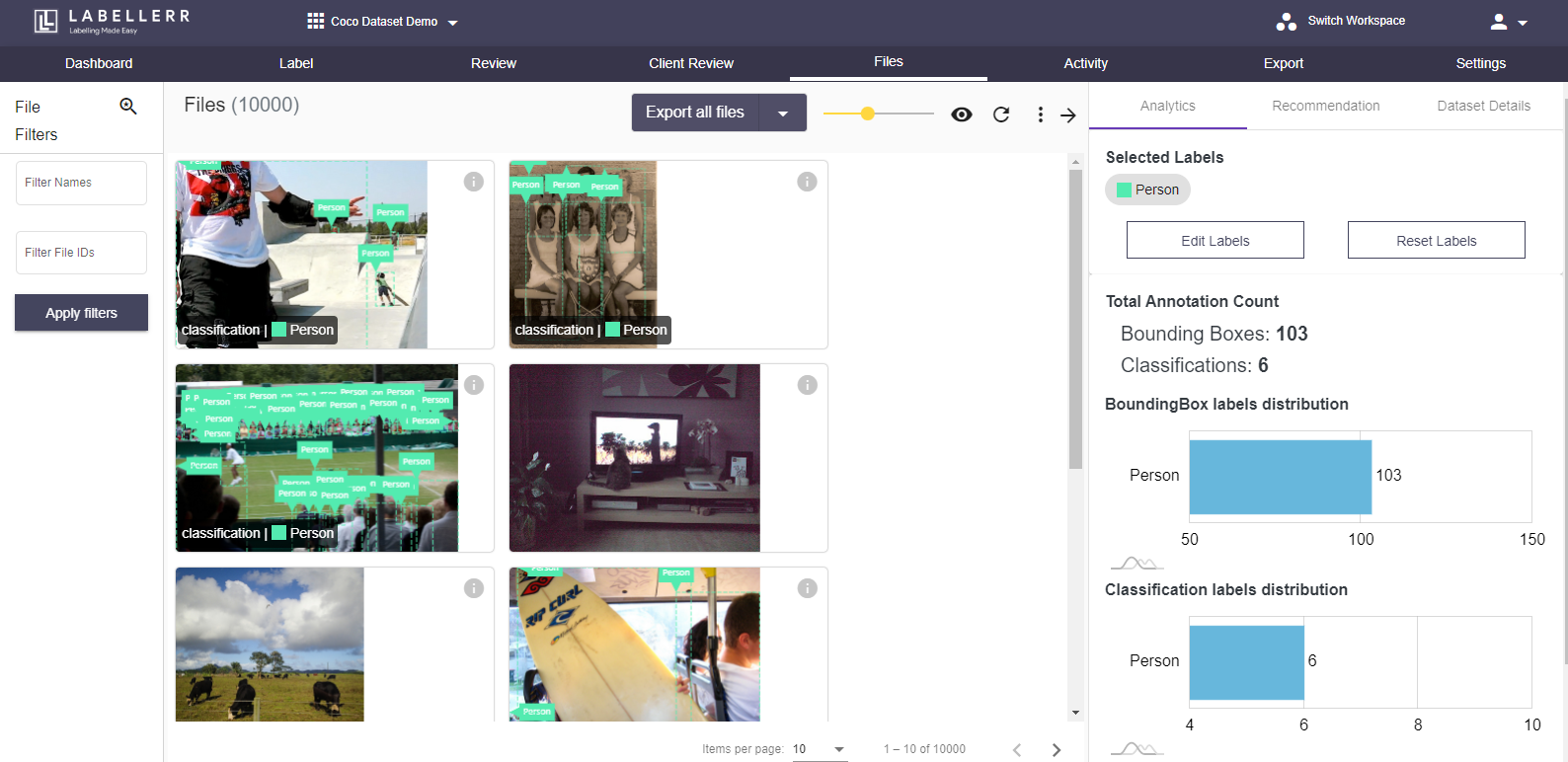
So, with the 3000+ labels category, our platform provides lot of access to explore and train datasets. Our platform help users to do quality assurance with high convenience in just few clicks.
User can check the cumulative score of your connected datasets. The major benefit that comes along with it is that you can sort your data based on the cumulative score. Why would you waste your time on such effective data? Move on to the next part, right?
Example- For object detection project of 100,000 images teams can save their time and effort by up to 40%. Our platform can auto annotate large volume of image in one click and user can select based on confidence score which images can be removed from the pipeline.
So all you need to do is collect your data, analyze data and perform insightful analytics by just connecting with our platform.
Learn initially: Training your object detection AI model with Labellerr
If you're interested in setting up our object detection feature for your company, don't hesitate to contact us. We'll be more than happy to get you started on making your data analysis faster and easier.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
