

Training your object detection AI model with Labellerr


The development, training, and application of algorithms for machine learning that simulate sound decisions based on accessible facts are known as the AI model.
When it comes to object detection AI models, the process of collecting, training, and evaluating the model becomes hectic without any support from a data training platform.
But do you know you can train your object detection with Labellerr with great accuracy and ease? Wondering how? Read a complete blog to get detailed information!
Let’s first understand what object detection is.,
Table of Contents
- What is Object Detection?
- How is Object Detection Performed?
- Get Your Datasets Ready
- Train Your Model
- Evaluate Your Model
What is Object Detection?
A computer vision technology called object detection helps locate and identify things in an image or video. To be more precise, object detection creates bounding boxes all around items it has found, allowing us to determine their location inside (or how they move across) a scene.
Before we continue, it's crucial to make the distinctions between object detection and picture recognition clear, approximate as they are sometimes misconstrued.
An image is given a label through image classification. The word "dog" is used to describe an image of a dog. The word "dog" is still used to describe an image of two canines.
Contrarily, object detection surrounds each dog with a box that is labeled "dog." The model forecasts the location of each object and the appropriate label. Consequently, object detection offers more details about a picture than object recognition.
How is object detection performed?
Generally speaking, object detection is divided into two stages:
- Detectors for objects in one stage
- Object detectors with two stages
Typically, deep learning-based object detectors take features out of the input picture or video frame. Two more jobs are resolved by an object detector:
Task 1: Locate any quantity of items (maybe even 0), and
Task 2: Sort every single object into a category and get its bounding box size. You can divide those chores into two stages to make the procedure easier. Other techniques, which aim to increase performance at the expense of accuracy, integrate both tasks into a single step (single-stage detectors).
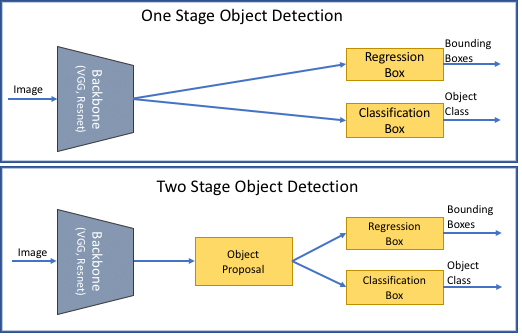
Single-stage detectors
Single-stage detectors forecast bounding boxes across the images without a region proposal step. Because it takes less time, this method can be applied in real-time scenarios. One-stage object detectors favor inference speed and are extremely quick, but they struggle to distinguish between a collection of small items or objects with odd shapes.
The YOLO, SSD, & RetinaNet are the most widely used one-stage detectors. The most recent real-time detectors are YOLOR and YOLOv4-Scaled (2020). (2021). View the comparisons of benchmarks below. The fundamental benefit of single-stage algorithms is that they are typically faster and more streamlined architecturally than multi-stage detectors.
Two-stage detectors
Two-stage object detectors provide dataset object areas utilizing deep features before such features are employed for the classification and bounding box for the object candidate.
- The two-stage design starts with the proposal of an object region using traditional computer vision techniques or deep networks and then moves on to object classification using bounding-box regression based on features taken from the suggested region.
- The maximum detection accuracy is achieved by two-stage approaches, which are often slower. The performance (fps) is inferior to one-stage detectors because of the several inference stages required for each image.
- The Region convolutional neural network (RCNN)can evolve to Faster R-CNN or Mask R-CNN, which is one of many two-stage detectors. The granulated RCNN is the most recent evolution (G-RCNN).
- Two-stage object detectors locate a region of interest first, then classify the cropped region using it. However, due to cropping being a non-differentiable process, such multi-stage monitors are typically not end-to-end trainable.
Training your object detection AI model with Labellerr -
Get your datasets ready
Firstly, log in to Labellerr’s platform and create a workspace on our platform. After entering the dashboard area, select the option to create a new project. Now, go ahead and select the types of datasets that you want to use for your project.
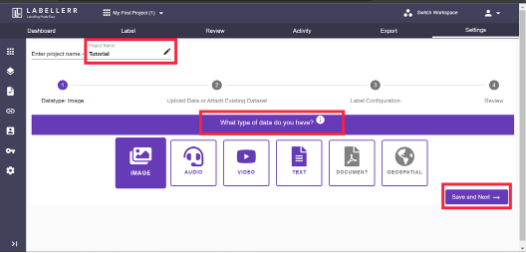
You can get various datasets options to choose from such as images, audio, videos, text, documents, and geospatial.
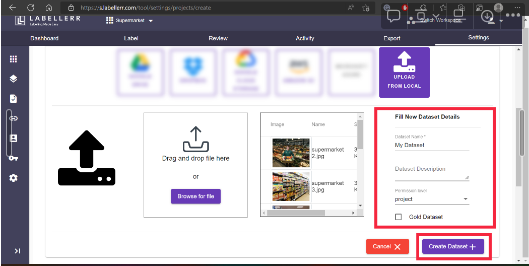
You can upload your Drive from any location, whether it be your device, google drive, cloud storage, etc. Now, after uploading your data, name the dataset and create a dataset. If you are an existing user, then you can select from the stored dataset.
Train your model
After uploading your data, the next step is to train the AI model. For that, the objective is to produce objects and classifications depending on the labeling specifications.
You can go to the ‘label’ option, next to the dashboard. Start creating your template or use an existing template.
Now, add objects and classifications based on your project’s requirements. While you are annotating your data, you get six types of annotations, such as:
- Bounding Box
- Polygon
- Dot
- Line
- Segmentation
- Landmark/Keypoint
An additional feature of our tool is that you can add guidelines along with some classification whenever required. You also get an option to do basic editing to your data. Now, enable the review procedure and save your project.
Object detection tools like Labellerr simplify the complex process of training AI models by providing intuitive annotation interfaces and automation features. With support for bounding boxes, polygons, segmentation, and keypoints, Labellerr’s tool ensures precise labeling for diverse use cases. Its seamless integration with cloud storage and collaborative workspace capabilities makes it an ideal object detection tool for teams aiming to accelerate model development without compromising quality. Whether you are working on real-time detection or multi-stage models, Labellerr’s solution helps you streamline your workflow and achieve higher accuracy faster.
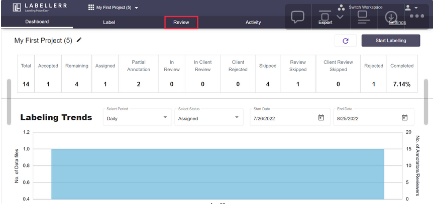
Evaluate your model
When training is complete, if you want, then move on to the review stage. You can find all the details about the model you trained right here. Similar to the labeling page, it is organized similarly and has all the labeling tools, enabling the addition and removal of annotations as well as editing and question correction.
You can add remarks and select or reject a particular instance. After you are done with the evaluation, you can export your dataset in various formats by visiting the export section.
So, if you want to train your AI model with ease and do not want to use burdensome tools with a challenging interface, then Labellerr is for you. We also help in providing data and assistance that can help you get an accurate model with greater efficiency.
We also have an experienced team of annotation experts to support you at a higher level. So, don’t wait! Contact us to fasten your objection detection AI model performance.
Why Choose Labellerr for Your Object Detection Projects
Labellerr offers a powerful data annotation tool designed to accelerate your object detection AI model development. Enjoy automated labeling, expert support, and flexible export options. Get started today with a free trial and see your AI projects succeed faster!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
