

Object Detection: The Process Behind Autonomous Vehicle Tech

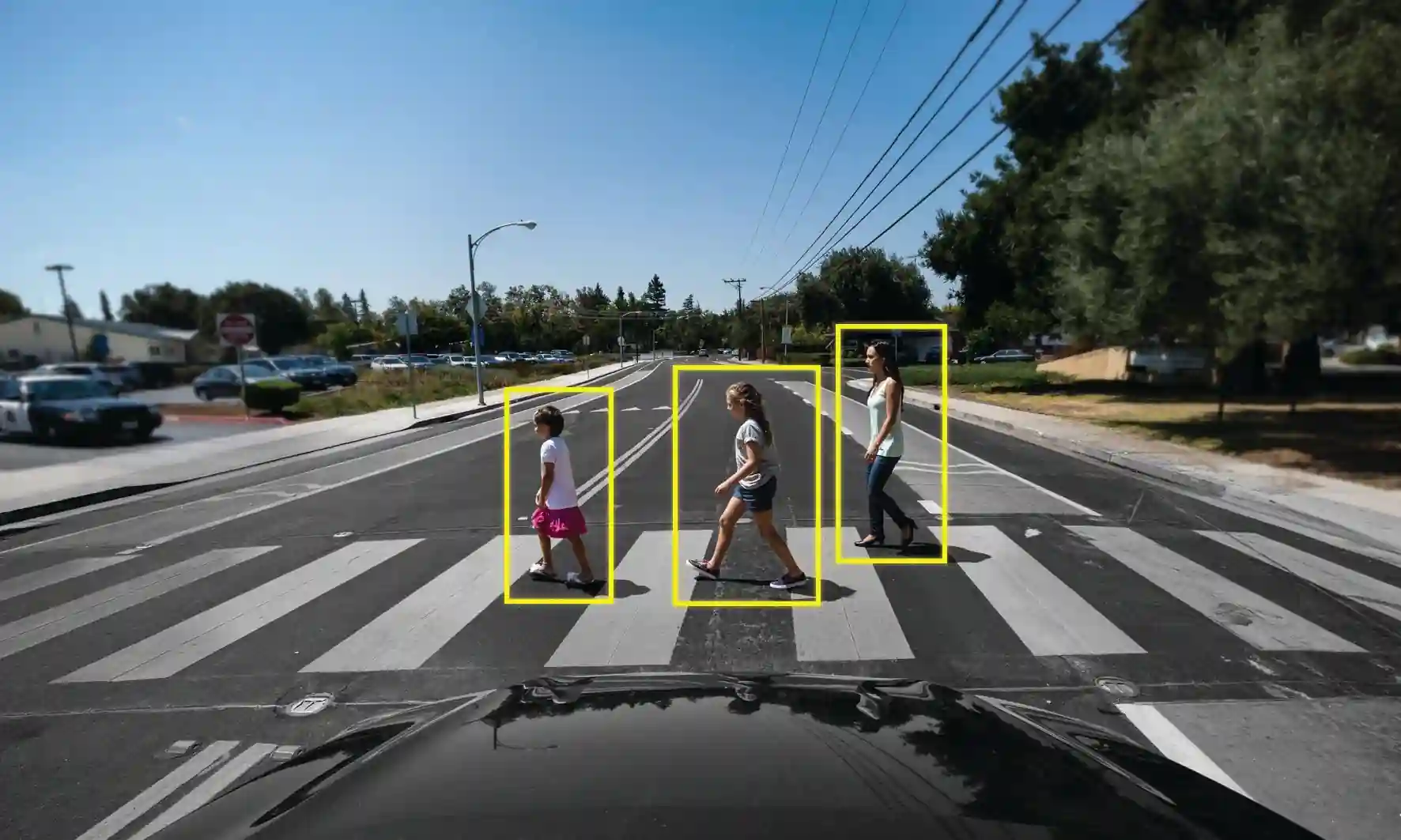
Knowing where the other vehicles are on the road and being able to anticipate where they’re heading next and also determining things like how far away they are, which way they’re going, and how fast they’re moving is essential in an autonomous vehicle. Much the same way as we do with our own eyes as we drive.
To be able to do this, we need to be able to detect and locate objects such as cars and pedestrians in the scene, as we can also see in the image below. Hence, reliable detection of objects is a crucial requirement to realize autonomous driving. As the vehicle shares the road with many other traffic participants, particularly in urban areas, the awareness of other traffic participants or obstacles is necessary to avoid accidents that might be life-threatening.
Img: Object Detection in Autonomous Vehicle
Introduction
Recognizing what’s in an image is the essence of computer vision. When we look at the world through our own eyes, we’re constantly performing classification tasks with our brain. And in the case of autonomous vehicles, reliable object detection is essential to giving the car to see the world just like we do.
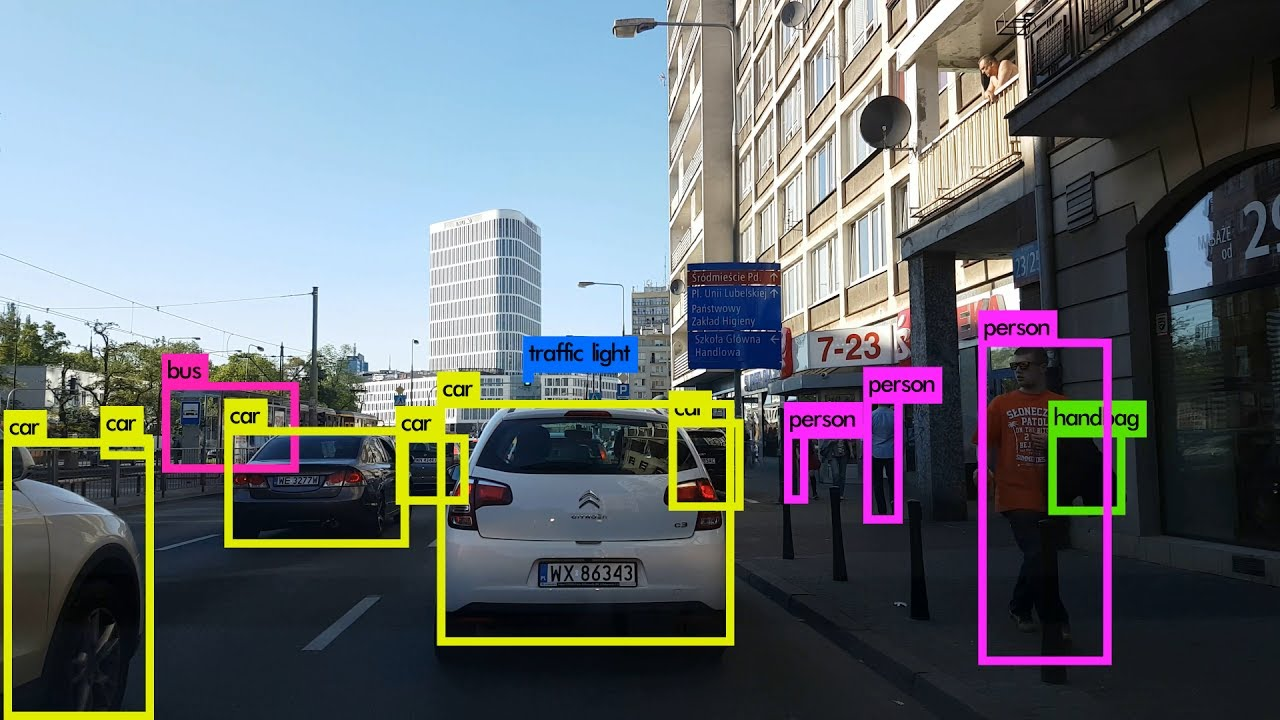
Object detection is the task of identifying what objects are present in an image, locating their position in the image and drawing bounding boxes around them. The image below is an example of the same.

Img: Object Detection
In this blog, we will discuss in brief about object detection, the steps we need to follow to achieve it and some common challenges.
Let’s begin by knowing more about what object detection actually is.
What is object detection?
Object detection is a computer vision technique for locating instances of objects in images or videos. In simple words, object detection is a technology where things like humans, buildings, cars can be detected as objects in images or videos. The detections are then labeled with bounding boxes. Object detection algorithms typically leverage machine learning or deep learning to produce meaningful results. When humans look at images or video, we can recognize and locate objects of interest within a matter of moments. The goal of object detection is to replicate this intelligence using a computer.
Object detection is generally thought of as a combination of Image Classification and Object Localization. We can distinguish these three computer vision tasks like this:
1. Image Classification: Predict the type or class of an object in an image.
2. Object Localization: Locate the presence of objects in an image and indicate their location with a bounding box.
3. Object Detection: Locate the presence of objects with a bounding box and types or classes of the located objects in an image.

Img: (Left) Classification (Middle) Localization (Right) Object Detection
You can learn more about this from here: What Is Object Detection?
Classical object detection systems usually consist of multiple steps that are applied consecutively to solve the object detection task. We’ll discuss them in the next section.
Object detection pipeline
A classical detection pipeline usually comprises the following steps:
1. Pre-processing:
- Image pre-processing are the steps taken to format images before they are used by model for training or inference with the aim of improving the image data by suppressing undesired distortions or enhancing some image features relevant for further processing and analysis tasks.
- This includes tasks such as resizing, orienting, color corrections and image rectification.
2. Region of interest extraction (ROI):
- ROI is a portion of an image that we want to filter or operate on in some way. Suppose, if we want to detect a cat in image, then the region belonging to or occupied by the cat or where there are chances of locating the cat is our ROI.
- ROIs can be extracted using a sliding window approach, which shifts a window over the image at different scales and searches for features belonging to the object we are looking for. This is also known as exhaustive search and is very computationally expensive. An example of this is given below.

Img (GIF): Sliding Window Approach
- Selective Search is an alternative approach to generate regions of interest. Instead of an exhaustive search over the full image domain, selective search exploits a segmentation of the image to extract approximate locations efficiently and then searches at those locations only.
3. Object classification:
- The goal of object classification is to determine the class of each object in an image such as a car. This can be seen in the image below too where the ROI extraction is done first and then the objects are classified into classes.
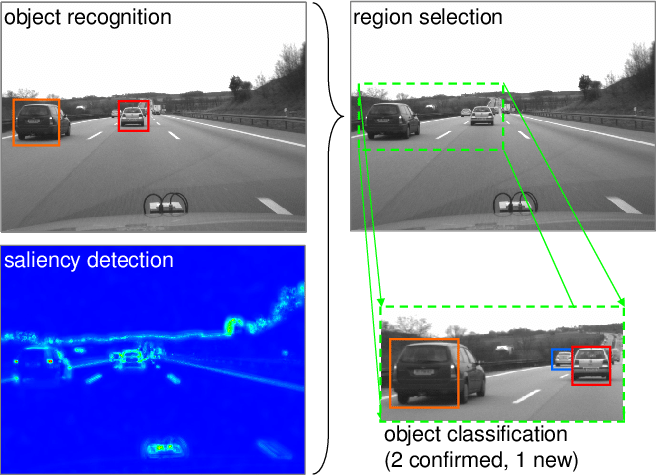
Img: ROI Extraction and Object Classification
- Convolutional Neural Networks (CNNs) are the most commonly used algorithm for the task of object classification due to their high speeds and accuracy. We have discussed more about them in our other blog.
4. Verification or refinement:
- We need to measure if the model found all the objects and also a way to verify if the found objects belong to the correct class.
- Generally, a labeled validation or test dataset is provided to the system for the same. The system tries to predict on those images and then checks if its predictions were correct, based on which the performance of the model can be verified and further refinement could be done, if required.
With the success of deep neural networks, most of these steps and even the complete pipeline have been replaced by learned models. Hence, CNN-based object detection algorithms like Faster-RCNN or YOLO are most commonly used methods nowadays. We have discussed more about deep learning for object detection in our other blog.
Before we conclude, let us discuss a few challenges that object detection algorithms face usually.
Challenges
Image classification is tricky. And it becomes even trickier when we don’t know exactly where in an image our objects of interest will appear or what size they’ll be or even how many of them we might find.
In addition, the resemblance of objects to each other or to the background and physical effects like cast shadows or reflections can make the detection of objects even more difficult.
Another challenge is that an autonomous vehicle needs a flawless object detection system which is robust against all weather conditions and efficient for real-time detection. Although, cameras are the cheapest and most commonly used type of sensors for the detection of objects. But, they might face difficulties during night-time or bad weather when the visibility is low, which can be seen in the image below.

Img: Low visibility during bad weather
A solution to this might be to use active sensors that emit signals and observe their reflection, like laser scanners. Such sensors provide range information at all times of day and in all weathers which can help to detect an object and localize it in 3D. You can see an example of this here: How is LiDAR remote sensing used for Autonomous vehicles?
However, laser scanners often have a smaller resolution compared with video cameras. So, depending on the weather conditions, time of day, or material properties, it can be problematic to rely on a single type of sensor alone. Hence, the combination of information from different sensors via sensor fusion is used in most autonomous vehicles.
Summary
Object detection is the task of identifying and locating objects in an image. It is very important for autonomous vehicles as it can help identify and avoid possible obstacles. Also, it serves as a first step for other important tasks like object tracking and motion estimation, which too are very essential for realizing autonomous driving.
Object detection has demonstrated impressive performance in case of high resolution images with little occlusions. For the easy and moderate cases of the car detection task, many methods provide accurate detections. But the detection of small objects, distant objects and highly occluded objects is a challenging task.
Also, improving accuracy during low light conditions and bad weather with low visibility is another area which requires more work.
Artificial Intelligence (AI) is still not as smart as humans and cannot drive better than humans yet. But technology is rapidly expanding and one day we might see roads filled with self-driving cars. But that one day is still very far from reality for now.
To know about such related information, stay updated with us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
