

Data Collection and Preprocessing for Large Language Models


Are you struggling to harness the full potential of Large Language Models (LLMs) due to the complexities of data collection and preprocessing?
You're not alone.
Many developers and researchers face significant challenges in sourcing and preparing the vast amounts of text data necessary for training these advanced AI systems.
In fact, studies show that up to 80% of the time spent on AI projects is devoted to data preparation tasks rather than on model training or deployment.
Through this training, they learn language structure and patterns and can perform various language-related tasks such as summarization, translation, sentiment analysis, and more.
Due to their remarkable ability to perform natural language tasks that were previously difficult for machines, LLMs have gained significant attention in recent years.
However, developing and maintaining these models can be costly, requiring significant computational resources and data to train.
Despite these limitations, LLMs are widely used in various fields, including chatbots, virtual assistants, and natural language processing.
Given LLMs' various opportunities and challenges, focusing on research and development in this area is important.
In this article, we’ll learn about the key components of successful data preparation, including recent advancements in pre-training methods, adaptation tuning for improved effectiveness and safety, practical utilization for diverse applications, and robust capability evaluation techniques.
Table of Contents
- Pretraining Of LLMs
- Corpus/Corpora
- Data Collection
- Data Source
- Data Preprocessing
- Quality Filtering
- De-duplication
- Privacy Redaction
- Tokenization
- Effects of Pretraining Data on LLMs
- Mixture of Sources
- Amount of Pretraining Data
- Quality of Pretraining Data
- Double Descent
- Conclusion
- FAQs
Pretraining Of LLMs
Pre-training on large-scale corpora is essential to establishing the fundamental language skills of LLMs. This allows LLMs to acquire the necessary abilities in language generation and understanding.
In this process, the quality and scale of the pre-training corpus are crucial factors for LLMs to gain powerful capabilities.
Additionally, to ensure effective pre-training of LLMs, model architectures, acceleration methods, and optimization techniques must be thoughtfully designed.
Corpus/Corpora
A corpus is a sizable and organized collection of machine-readable texts created in a natural communication setting. The plural form of the corpus is corpora.
These corpora can be generated through various means, such as electronic text sources, spoken language transcripts, optical character recognition, etc.
Data Collection
LLMs require better quality data for their pretraining, and their model capacity primarily depends on the pretraining corpus and its preprocessing compared to smaller language models.
This section focuses on the acquisition and processing of pretraining data, which includes the sources of data, methods for preprocessing, and an analysis of how pretraining data affects the performance of LLMs.
Data collection for AI is a foundational step that directly influences the success of training Large Language Models. Gathering diverse, high-quality text data from multiple sources ensures that AI models learn a broad range of language patterns and knowledge. However, collecting raw data is only the beginning-effective preprocessing is critical to remove noise, duplicates, and sensitive information, which can otherwise degrade model performance.
We specialize in streamlining data collection for AI by providing tools that automate data annotation, quality filtering, and privacy redaction. Our platform empowers AI developers to efficiently curate large-scale datasets tailored to their specific needs, ensuring data is ready for training without compromising quality or compliance. By leveraging Labellerr’s solution, organizations can reduce manual effort, accelerate AI project timelines, and enhance model outcomes.
Data Source
Collecting a substantial amount of natural language corpus from various sources is crucial for creating a proficient LLM. LLMs currently in existence primarily use a combination of multiple public textual datasets as their pre-training corpus.
The pre-training data used can be classified into two main types: general data and specialized data.
Most LLMs use general data, such as web pages, books, and conversations, as their pre-training corpus because it is abundant, diverse, and easily accessible. This helps improve their language modeling and generalization skills.
However, some studies have explored using specialized datasets, such as multilingual data, scientific data, and code, to give LLMs specific problem-solving abilities.
These approaches are effective in enhancing the capabilities of LLMs for specific tasks. For more information on data sources, refer to this article.
Data Preprocessing
It is important to preprocess the collected text data to create a pre-training corpus for LLMs to remove noise, redundancy, irrelevance, and potentially harmful content.
This is because the data quality can significantly impact the capacity and performance of the language models. This section discusses various data preprocessing strategies to enhance the quality of data.

Figure: Data Preprocessing Pipeline
Struggling to prepare quality data for your Large Language Models? Labellerr offers an advanced platform that automates data annotation, quality filtering, and privacy redaction, helping you prepare clean, high-quality datasets faster and more efficiently. Start your AI project with a free demo today!
Quality Filtering
Two main approaches ensure that only high-quality data is included in the pre-training corpus: classifier-based and heuristic-based.
Classifier-based approaches train a binary classifier to identify and filter out low-quality data, with high-quality texts (e.g., Wikipedia pages) used as positive and candidate data as negative instances.
However, classifier-based approaches may unintentionally remove high-quality texts in dialectal, colloquial, and sociolectal languages, leading to bias and decreased corpus diversity.
In contrast, heuristic-based approaches, such as BLOOM and Gopher, employ well-designed rules to eliminate low-quality texts.
These rules include language-based filtering, metric-based filtering, statistic-based filtering, and keyword-based filtering.
Language-based filtering removes texts in languages irrelevant to the LLM's tasks, while metric-based filtering uses evaluation metrics like perplexity to detect unnatural sentences.
Statistic-based filtering measures text quality based on statistical features of the corpus, while keyword-based filtering removes noisy or unuseful elements based on specific keyword sets, such as HTML tags, hyperlinks, boilerplates, and offensive words.
De-duplication
Previous research has shown that having duplicate data in a pre-training corpus can reduce the diversity of language models, potentially leading to instability during training and negatively impacting the model's performance.
As a result, de-duplication is necessary to remove duplicate instances from the corpus. This can be done at different levels, including sentence-level, document-level, and dataset-level.
At the sentence level, low-quality sentences that contain repetitive phrases or words should be removed to avoid introducing repetitive patterns into the model.
At the document level, previous studies have relied on surface feature overlap (e.g., words and n-grams) to identify and remove duplicate documents with similar content.
Additionally, to prevent contamination of the training and evaluation sets, removing duplicate texts from the training set is essential.
Using all three levels of de-duplication is effective in improving the training of LLMs, and they should be used together in practice.
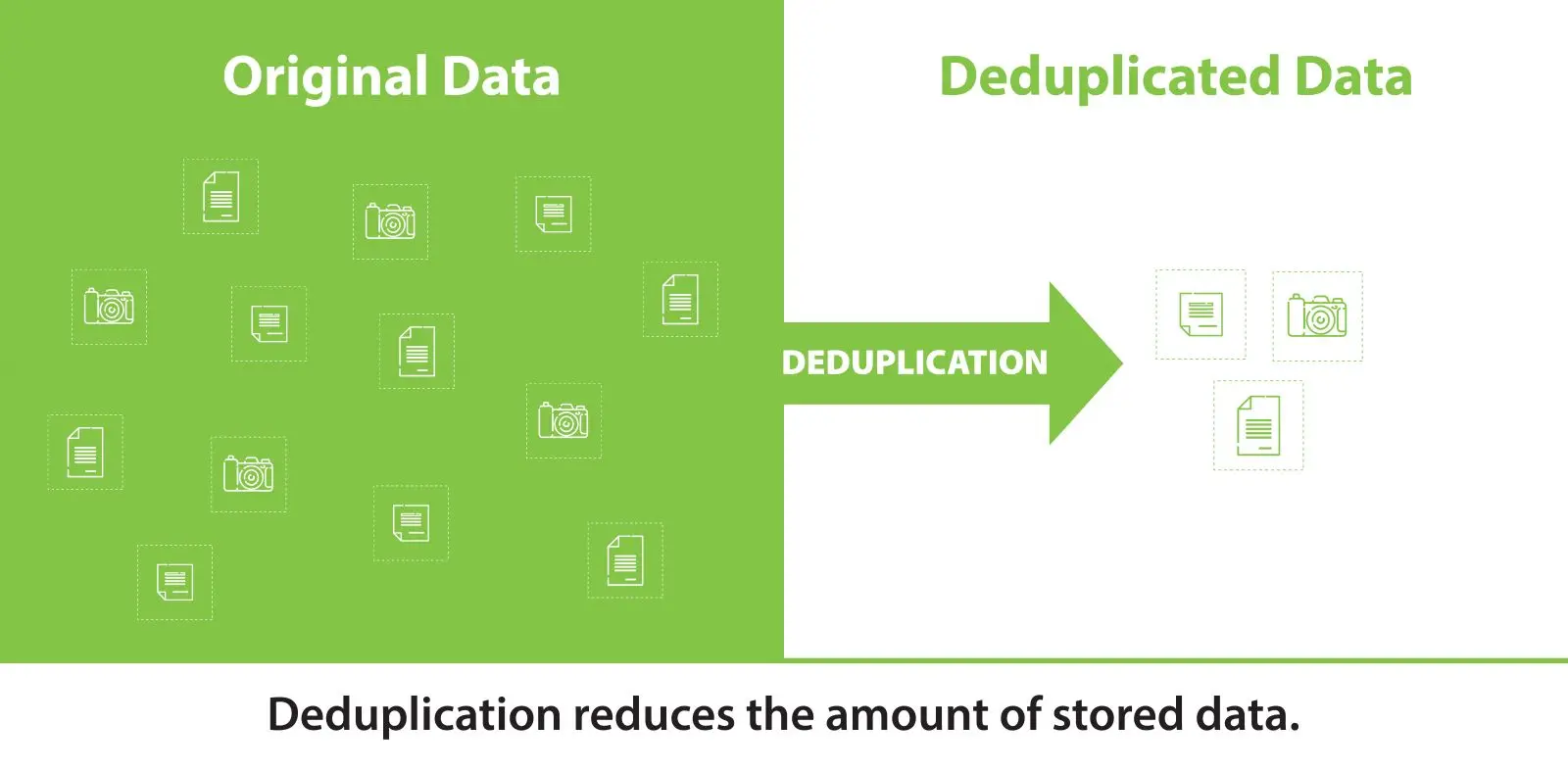
Figure 2: De-duplication of data
Privacy Redaction
Most text data used for pre-training LLMs are sourced from the web, often containing user-generated content that may involve sensitive or personal information.
This poses a risk of privacy breaches, making it necessary to remove personally identifiable information (PII) from the pre-training corpus.
Rule-based methods, such as keyword spotting, can detect and remove PII, such as names, addresses, and phone numbers. In addition, the presence of duplicate PII data in the pre-training corpus can make LLMs vulnerable to privacy attacks.
Therefore, de-duplication can also help reduce privacy risks.

Figure: Privacy Redaction in Input Data
Tokenization
Tokenization is a critical data preprocessing step in which raw text is segmented into individual tokens to input LLMs.
While it may be convenient to use an existing tokenizer, such as the one in GPT-2, using a tokenizer tailored to the pre-training corpus can be highly advantageous, particularly for corpora containing diverse domains, languages, and formats.
To this end, recent LLMs have developed customized tokenizers using SentencePiece. These tokenizers employ the byte-level Byte Pair Encoding (BPE) algorithm to ensure that the information is not lost during tokenization.
However, normalization techniques such as NFKC may negatively affect tokenization performance.
Effects of Pretraining Data on LLMs
In contrast to small-scale PLMs, it is not feasible to repeatedly pre-train LLMs due to the high computational demands.
Therefore, it is crucial to have a high-quality pre-training corpus that is well-prepared before training an LLM. In this section, we will explore how the quality and distribution of the pre-training corpus can affect the performance of LLMs.
Mixture of Sources
As mentioned earlier, pre-training data from various domains or situations have unique linguistic characteristics and semantic knowledge.
By training LLMs on a combination of text data from various sources, they can obtain a wide range of expertise and demonstrate a strong generalization ability.
However, the distribution of pre-training data also impacts the performance of LLMs on downstream tasks.
Gopher experimented with data distribution to examine the impact of mixed sources on downstream tasks.
The results show that increasing the proportion of book data can improve the model's ability to capture long-term dependencies from text while increasing the proportion of the C4 dataset leads to performance improvement on the C4 validation dataset.
On the other hand, training on excessive data about a certain domain would affect the generalization capability of LLMs on other domains.
Therefore, it is recommended that researchers carefully determine the proportion of data from different domains in the pre-training corpus to develop LLMs that better meet their specific needs.
Amount of Pretraining Data
To pre-train a high-performing LLM, it is crucial to gather enough high-quality data that meets the data quantity requirements of the model.
Previous research has shown that more data is needed to train the model effectively as the LLM's parameter scale increases.
A study also revealed that certain LLMs did not achieve optimal training because they lacked adequate pre-training data.
Additionally, it was found that scaling the data size in proportion to the model size could lead to a more compute-efficient model. Another recent study showed that smaller models could perform well with more extended training and more data.
Therefore, researchers must pay attention to collecting enough high-quality data to sufficiently train their models, especially when scaling the model parameters.
Quality of Pretraining Data
Previous research has indicated that pre-training on low-quality data, such as noisy, toxic, or duplicate data, can harm the performance of language models.
To develop an effective LLM, it is important to consider both the quantity and quality of the collected training data. Recent studies, including T5, GLaM, and Gopher, have investigated the impact of data quality on downstream task performance.
Comparing models trained on filtered and unfiltered data found that pre-training on cleaned data can improve performance.
Duplicate data can lead to "double descent" or overwhelm the training process, and it degrades the ability of LLMs to copy from the context, potentially affecting generalization capacity.

Figure 3: Double Descent
Therefore, preprocessing methods should be carefully employed on the pre-training corpus to improve the stability of the training process and avoid negative effects on model performance.
Double Descent
The term "double descent" describes a machine learning phenomenon where the generalization error of a model initially decreases as the model complexity rises, achieves a minimum, and then ascends once again as the model becomes more complex.
Contrary to popular belief, overfitting should cause the generalization error to increase as a model's complexity increases constantly.
The traditional trade-off between bias and variance is represented by the first descent, where an increase in model complexity results in a better fit to the training data due to a drop in bias but a worse fit to the test data due to an increase in variance.
The interpolation threshold is the location where the bias and variance curves converge. As the model complexity rises over this point, the generalization error decreases again.
The regularisation characteristics of the model, which can prevent overfitting and enhance generalization performance, can cause this second descent.
Conclusion
As you reflect on the complexities of developing Large Language Models (LLMs), it’s crucial to recognize the pivotal role that data collection and preprocessing play in your success.
You’ve learned how vital high-quality, diverse, and well-prepared training data is for enhancing model performance and generalization.
By implementing strategies such as quality filtering, de-duplication, and privacy redaction, you can elevate your LLMs to meet the demands of various applications effectively.
Remember, the careful selection and preparation of your data are not mere steps in the process; they are the foundation upon which the capabilities of your models are built.
In this rapidly advancing field, the ability to navigate these complexities will set you apart as a leader in AI.
So, take these insights to heart, and start applying them today. The future of natural language processing is within your reach—are you ready to harness its full potential?
Frequently Asked Questions
1. What is data collection and preprocessing?
Data collection and preprocessing refer to the processes involved in gathering and preparing raw data for further analysis.
Data preprocessing, a crucial part of data preparation, involves various operations performed on the raw data to make it suitable for subsequent data processing tasks. Traditionally, this step is an essential preliminary stage in data mining.
2. What are large language models in AI?
Large language models in the field of AI are advanced generative models designed to produce human-like text that is contextually meaningful.
These models primarily specialize in generating text, but they can also extend their capabilities to generate other forms of content such as audio, images, video, synthetic data, 3D models, and more.
3. How much data does it take to train an LLM?
The data required to train a large language model (LLM) may vary, and there is no definitive answer.
However, it is common for an LLM to have a minimum of one billion or more parameters, which are the variables used in the model's training process to generate new content.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
