

Training Small-Scale Vs Large-Scale Language Models: The Difference
Explore the contrasts between training small and large-scale language models, from data requirements and computational power to model complexity and performance nuances in NLP applications


Language model development has significantly evolved, leading to the emergence of small-scale and large-scale models.
These models have revolutionized various natural language processing related tasks and profoundly impacted the artificial intelligence field.
Understanding the differences between small-scale and large-scale language models is crucial for grasping their capabilities and implications.
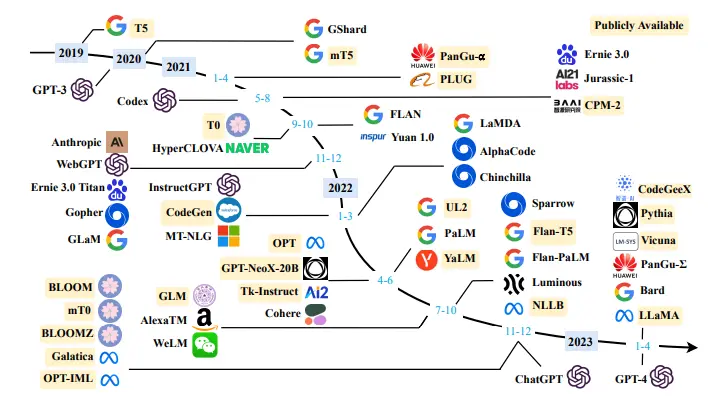
Figure: Timeline of LLMs
Small-scale language models, also known as PLMs (Pre-trained Language Models), were the earlier iterations in the development of language models.
These models were trained on relatively smaller datasets and had limited computational resources. They provided a foundation for understanding language structure, word relationships, and basic language processing tasks.
With advancements in computational power and the availability of vast amounts of training data, large-scale language models (LLMs) emerged.
LLMs are significantly larger and more complex compared to their small-scale counterparts.
They are trained on massive datasets, often comprising billions or even trillions of words, allowing them to capture a deeper understanding of language nuances and contextual dependencies.
So, what’s the difference between these two technologies?
In this blog, we will discuss the differences faced while developing any Large Language model compared to any small-scale model.
Table of Contents
- Data Requirements
- Computational Resources
- Storage Capacity
- Training Time
- Maintenance and Infrastructure
- In-context Learning
- Step-by-Step Reasoning
- Example of difference between GPT-2 (small scale model) Vs. GPT-3 (large scale model)
- Conclusion
- Frequently Asked Questions (FAQ)
Developing Small vs Large Language Models: Key Differences
In this blog, we aim to discuss the differences faced while developing any Large Language model compared to any small-scale model.
Developing small-scale and large-scale models differ significantly in their resource requirements. Here are the key differences:
1. Data Requirements
Creating small-scale models typically involves utilizing a moderate quantity of training data.
These models can be trained on datasets that encompass several thousand to a few million data points. Although data collection and processing remain crucial, managing the scale of data is relatively feasible.
On the other hand, developing large-scale models requires a significant volume of training data. These models necessitate extensive datasets that span from millions to billions of data points.
Acquiring, storing, and processing such vast amounts of data can pose challenges, demanding robust data infrastructure and storage systems.
2. Computational Resources
Small-scale models can be accomplished with moderate computational resources. These models can be trained on standard hardware setups like personal computers or small server clusters.
They typically do not require specialized hardware accelerators or high-performance computing systems.
Large-scale models demand significant computational resources. Training these models efficiently often requires powerful GPUs, specialized hardware accelerators (like TPUs), or access to high-performance computing clusters.
The computational infrastructure must support distributed training to handle the massive parallel processing required for large-scale models.
3. Storage Capacity
Small-scale models generally have smaller model sizes and require less storage capacity for storing the model parameters. The storage requirements are manageable, and standard storage solutions are sufficient.
Large-scale models have significantly larger model sizes due to their complex architectures and a higher number of parameters.
Storing and managing these large model files necessitate substantial storage capacity. High-capacity storage systems or distributed storage solutions may be required to handle large model files effectively.
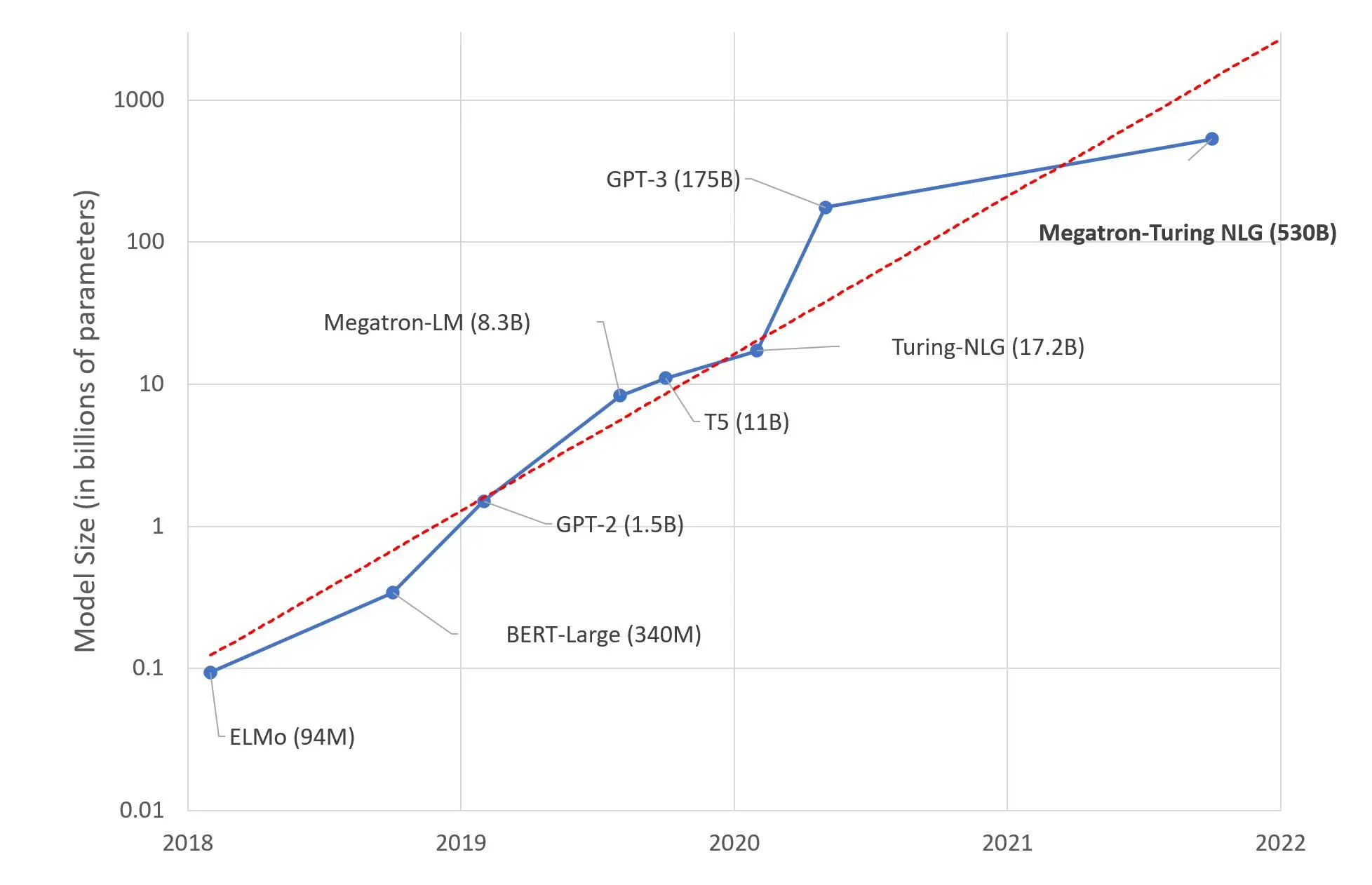
Figure: Comparison of the Number of Parameters for Different Models
4. Training Time
Training small-scale models typically take a relatively shorter amount of time. With a smaller dataset and less complex model architecture, training iterations can be completed within a reasonable timeframe, ranging from hours to a few days.
If we talk about large-scale models can be a time-consuming process. The extensive data, complex model architectures, and the need for multiple training iterations significantly increase the training time.
Training large-scale models can take days, weeks, or even months, depending on the available computational resources and training techniques used.
5. Maintenance and Infrastructure
Developing and maintaining small-scale models require relatively fewer infrastructure resources.
The infrastructure can be simpler, with fewer server instances, reduced networking requirements, and less need for specialized monitoring and management systems.
Large-scale models require a robust infrastructure to handle the computational and storage demands.
This includes high-performance servers, distributed computing frameworks, scalable storage systems, and advanced monitoring and management tools. Maintaining and scaling the infrastructure to accommodate the needs of large-scale models can be complex and resource-intensive.
6. In-context Learning
In-context learning (ICL) is a specific capability pioneered by the GPT-3 model. It involves providing the language model with a natural language instruction or task demonstration, enabling it to generate the expected output for test instances by completing the word sequence in the input text.
ICL is impressive because it can accomplish this without requiring additional training or gradient updates.

Figure: Performing tasks without any Gradient Update
GPT-3, with its massive 175 billion parameters, has been found to possess a notably strong ICL ability compared to its predecessors, GPT-1 and GPT-2.
While GPT-1 and GPT-2 models lack this advanced in-context learning capability, GPT-3 showcases a significant improvement. GPT-3 is more proficient at leveraging natural language instructions or task demonstrations to generate accurate and contextually appropriate outputs.
By incorporating in-context learning, GPT-3 can effectively adapt to specific instructions or demonstrations, making it more versatile in various applications.
Whether understanding and responding to prompts, following specific guidelines, or generating desired outputs, GPT-3's ICL ability enhances its overall performance and flexibility.
7. Step-by-Step Reasoning
Step-by-step reasoning refers to the ability of language models to solve complex tasks that involve multiple reasoning steps.
Small language models often struggle with such tasks, particularly those that require solving mathematical word problems.
However, the chain-of-thought (CoT) prompting strategy addresses this limitation by utilizing intermediate reasoning steps to derive the final answer.
The CoT prompting strategy enables large language models (LLMs) to solve complex tasks effectively by breaking them down into interconnected reasoning steps.
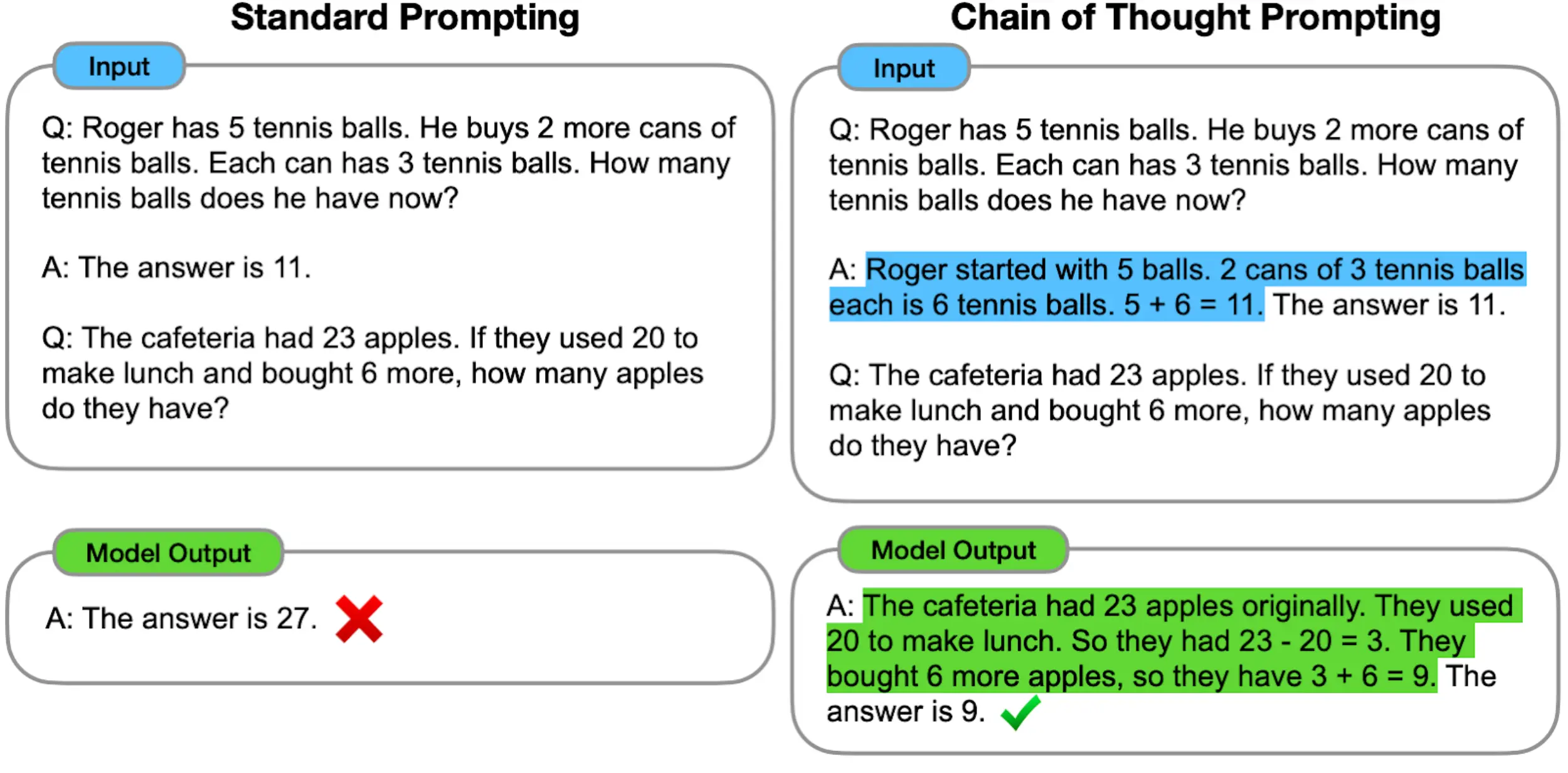
Figure: Chain of Thought Prompting
This prompts the model to make logical deductions, ultimately leading to the desired solution. Empirical studies have demonstrated the effectiveness of CoT prompting, particularly in arithmetic reasoning benchmarks.
Research has shown that when applied to LLM variants like PaLM and LaMDA with a model size exceeding 60 billion parameters, CoT prompting can significantly improve performance.
Moreover, as the model size increases beyond 100 billion parameters, the advantage of CoT prompting over standard prompting becomes more pronounced.
Example of difference between GPT 2 (small scale model) Vs. GPT3 (large scale model)
In this section, we explore some differences between GPT-2, a small-scale language model, vs. GPT-3, which is a Large-Scale Language Model.
Figure: Comparisons of various GPT versions
Small-Scale Language Model (GPT-2)
GPT-2 (Generative Pre-trained Transformer 2) is an example of a small-scale language model developed by OpenAI. It was released in 2019 and gained significant attention for its impressive language generation capabilities.
Development Differences
- GPT-2 was trained on a substantial but limited amount of data. It was trained on approximately 40 gigabytes of text data, comprising a mixture of books, internet articles, and other written sources. While the training data was diverse, it was not as extensive as the data used to train GPT-3.
- The GPT-2 model has a relatively smaller size compared to GPT-3. It consists of around 1.5 billion parameters,, which determines the complexity and capacity of the model.
Large-Scale Language Model: GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is an example of a large-scale language model developed by OpenAI. It was released in 2020 and is known for its impressive size and capabilities.
Development Differences
- GPT-3 benefits from a significantly larger and more diverse training dataset. It was trained on vast text data, estimated at around 800GB. The training data for GPT-3 includes many sources, such as books, websites, articles, and other textual resources. The larger dataset helps GPT-3 capture a broader spectrum of language patterns and knowledge.
- GPT-3 is significantly larger compared to GPT-2. It is available in sizes ranging from 125 million to 175 billion parameters. The largest variant, 175B, has a massive model size, enabling it to capture and process vast information.
Conclusion
Developing small-scale and large-scale language models significantly advances natural language processing.
Small-scale models serve as a foundation for understanding language structure and basic tasks, while large-scale models offer more complex and nuanced language processing capabilities.
The differences in developing these models are substantial. Large-scale models require more diverse training datasets, extensive computational resources, and significant storage capacity.
Training large-scale models takes longer and necessitates advanced infrastructure for handling the computational and storage demands.
On the other hand, developing small-scale models is less resource-intensive, with moderate data requirements, less computational power, and smaller storage needs. Maintenance and infrastructure requirements are also comparatively simpler.
Understanding these differences is crucial for researchers and practitioners in effectively utilizing language models for various applications.
Developers can make informed decisions based on their specific requirements and available resources by considering the trade-offs between small-scale and large-scale models.
Unsure which large language model to choose?
Read our other blog on the key differences between GPT-4 and Llama 2.
FAQs
What is the difference between a language model and a large language model?
The distinction between a language model and a large language model lies in their complexity and scale.
While a language model can encompass a range of models, including simpler n-gram models, a large language model typically refers to advanced models utilizing deep learning techniques.
These large language models are characterized by their extensive parameter count, spanning millions to billions.
What are large-scale language models?
Large-scale language models, often abbreviated as LLMs, are advanced language models that employ artificial neural networks with a significant number of parameters.
These models are trained on extensive volumes of unlabeled text data using self-supervised or semi-supervised learning techniques.
The parameter count of these models ranges from tens of millions to billions, enabling them to capture complex patterns and generate coherent and contextually relevant text.
What are examples of large language models?
Several notable examples of large language models have been developed by leading organizations. OpenAI has created models such as GPT-3 and GPT-4, while Meta has developed LLaMA, and Google has introduced PaLM2.
These models can comprehend human language and generate text based on their input.
How to compare two language models?
To compare two language models, A and B, you can assess their performance by subjecting both models to a particular natural language processing task.
Execute the task using both models and analyze their respective accuracies.
By comparing the accuracies of models A and B, you can evaluate and conclude their relative performance.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
