

Everything You Need To Know About Fine Tuning of LLMs
Fine-tuning LLMs customizes pre-trained models for specific tasks by adjusting parameters with new data, enhancing model precision and relevance across unique applications from legal analysis to healthcare.

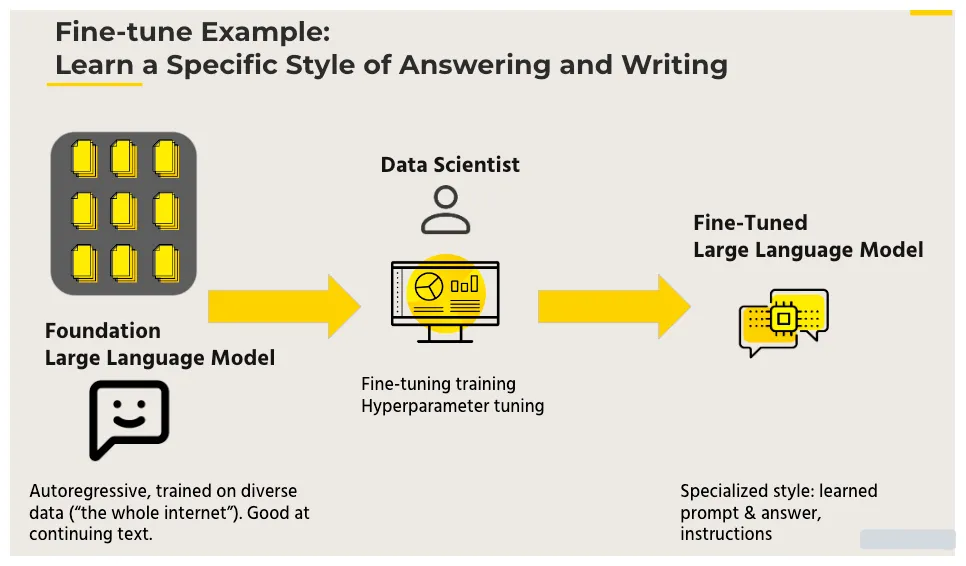
Pre-trained large language models (LLMs) come with impressive capabilities, such as text generation, summarization, and coding. Nevertheless, these LLMs are only universally suitable solutions for some scenarios.
Depending on your specific application, you may encounter tasks the language model cannot handle successfully.
In such situations, one viable approach is to engage in LLM fine-tuning. Fine-tuning involves the process of retraining a foundational model using new data.
While it can be resource-intensive, complex, and not necessarily the primary solution to consider, fine-tuning is an immensely potent technique that should be part of the toolkit for organizations that are incorporating LLMs into their applications.
Here's a breakdown of what you need to comprehend about fine-tuning large language models. Even if you lack the expertise to perform fine-tuning yourself, understanding the mechanics of fine-tuning can guide you in making well-informed decisions.
Table of Contents
- What Does LLM Fine-Tuning Entail?
- Out-of-Distribution Data in Machine Learning
- Selecting a Pre-trained LLM Model
- Various Approaches to Fine-Tune LLMs
- Reinforcement Learning from Human Feedback (RLHF)
- Parameter-Efficient Fine-Tuning (PEFT)
- Case Studies for Fine-Tuning of LLMs
- Conclusion
- Frequently Asked Questions
What does LLM fine-tuning entail?
Though this article primarily addresses LLM fine-tuning, the concept isn't exclusive to language models. Any machine learning model could require fine-tuning or retraining under certain circumstances.
When a model is trained on a dataset, its objective is to approximate the patterns inherent in the underlying data distribution.
To illustrate this concept, consider a convolutional neural network (CNN) built for identifying images of automobiles. This model has undergone training on tens of thousands of images depicting passenger cars in urban settings.
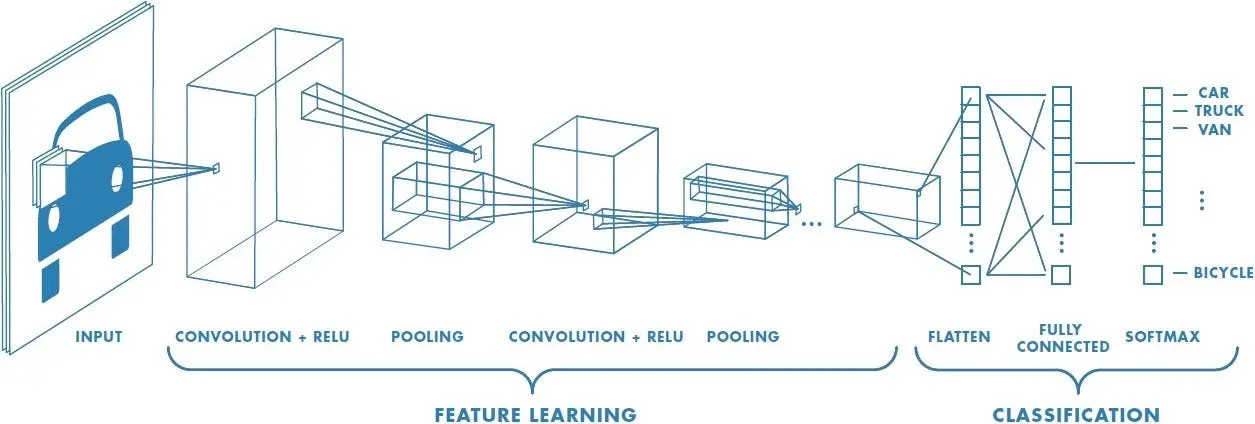
Figure: Convolutional Neural Network Architecture
Its parameters have been adjusted to recognize the shapes, colors, and pixel configurations typically associated with such vehicles and environments. Consequently, the model performs exceedingly well when applied to images of cars within cityscapes.
Now, envision a scenario where you intend to employ the same model to detect trucks on highways. Suddenly, the model's performance would decline because the distribution of images has significantly shifted.
In this case, one potential solution would be to initiate training from scratch, this time focusing on images of trucks on highways. However, this endeavor necessitates the creation of an extensive dataset containing tens of thousands of labeled truck images, an undertaking that can be both costly and time-consuming.
Out-of-Distribution Data in Machine Learning
Pre-trained ML models exhibit suboptimal performance when dealing with out-of-distribution examples.
Coincidentally, trucks and passenger cars share numerous visual attributes. Consequently, instead of starting anew, you can build upon the pre-trained model's foundation.
Armed with a relatively modest dataset of truck images (perhaps a few thousand or even a few hundred) and a few training epochs, you can refine the existing model for the new application. Fundamentally, fine-tuning operates beneath the surface by adjusting the model's parameters to align with the distribution of the fresh dataset.
This encapsulates the essence of fine-tuning. You take an already trained ML model and leverage novel data to recalibrate its parameters, adapting it to novel contexts or repurposing it for new applications.
The same principle extends to language models. If your model's training data distribution significantly diverges from the requirements of your application, fine-tuning might be a prudent consideration.
For instance, fine-tuning could be advantageous if you're employing an LLM for a medical application, but the model's training data needs to include medical literature. However, it's important to delve into the intricacies of fine-tuning LLMs, as they harbor unique nuances worth exploring.
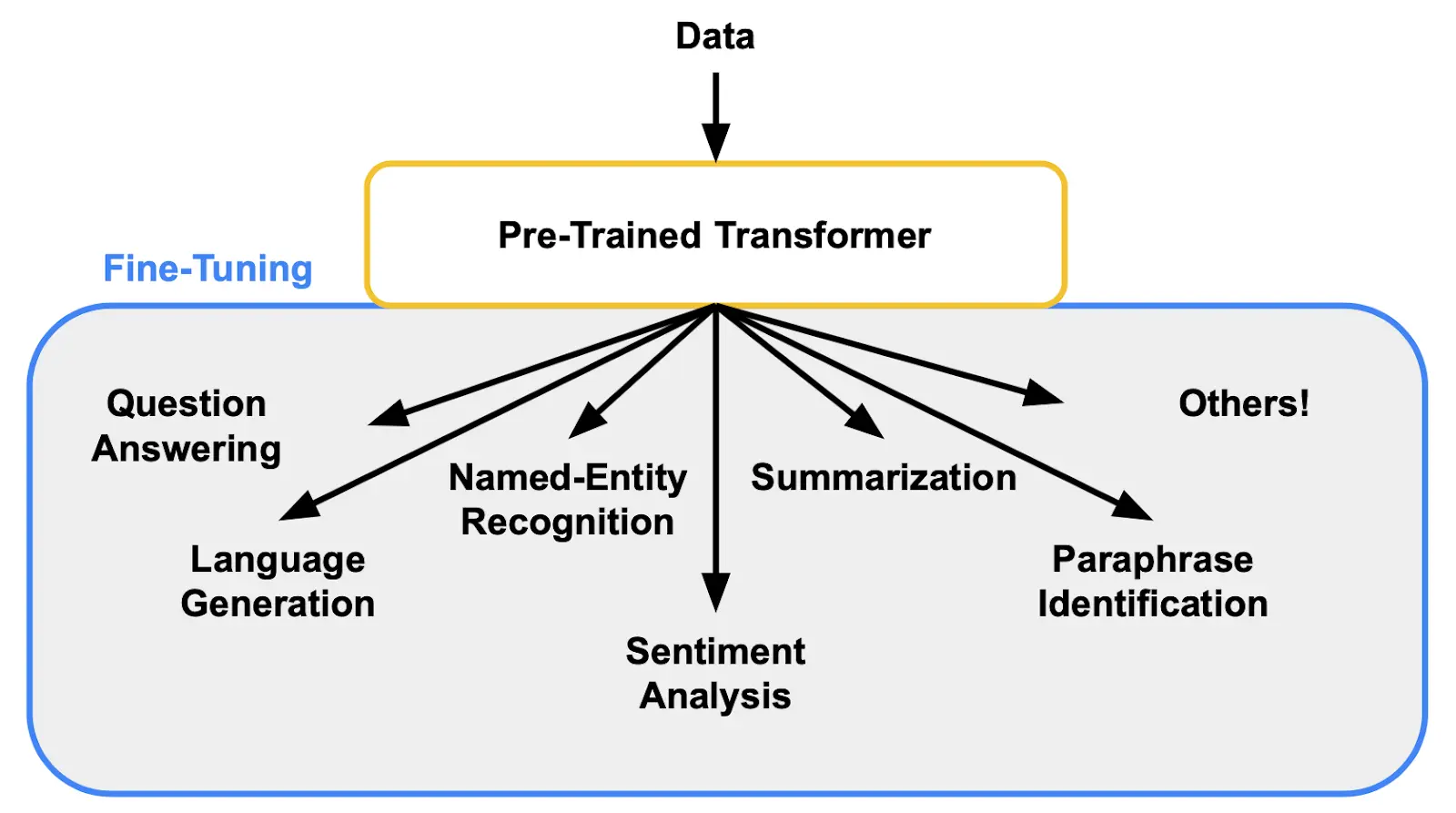
Figure: Fine-Tune a Pre-trained LLM for multiple tasks
Selecting a pre-trained LLM Model
The beginning phase involves opting for a large language model suitable for your specific objective. What are the alternatives at your disposal? The current array of cutting-edge large language models comprises GPT-3, Bloom, BERT, T5, and XLNet.
Among these, GPT-3 (Generative Pretrained Transformers) stands out with its exceptional performance due to its training on a staggering 175 billion parameters, enabling it to adeptly handle a variety of natural language understanding (NLU) tasks.
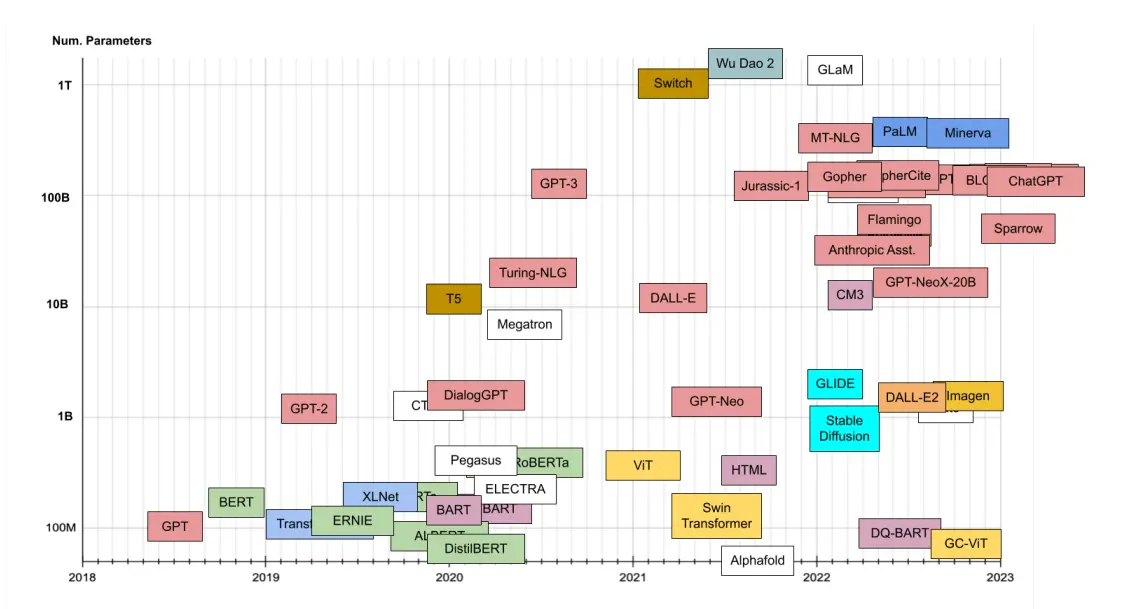
Figure: Different LLMs along with Number of Parameters
However, accessing GPT-3 fine-tuning necessitates a paid subscription, rendering it relatively pricier than other choices.
In contrast, BERT, an open-source expansive language model, offers the opportunity for free fine-tuning. BERT, which stands for Bidirectional Encoder Decoder Transformers, excels in comprehending contextual word representations.
How should you make your selection?
Should your task center more on text generation, opting for the GPT-3 (paid) or GPT-2 (open source) models might prove more fitting.
Conversely, if your objective involves text classification, question answering, or Entity Recognition, the BERT model would be a suitable direction. In my scenario of addressing questions related to Diabetes, I would proceed with utilizing the BERT model.
Various Approaches to Fine-Tune LLMs
Not all techniques for fine-tuning large language models (LLMs) are created equal; each serves distinct purposes based on different applications. In some scenarios, you aim to adapt a model for a new task.
Consider a scenario where you possess a pre-trained LLM proficient in text generation and desire to employ it for sentiment or topic classification. In such cases, you would repurpose the model by introducing minor modifications to its architecture before proceeding with fine-tuning.
For this particular application, you would exclusively utilize the embeddings generated by the transformer component of the model. Embeddings are numeric vectors that encapsulate diverse attributes of the input prompt.
While some language models directly generate embeddings, others, like the GPT family of LLMs, employ embeddings to produce tokens or text.
In the process of repurposing, you connect the model's embedding layer to a classifier model, often involving a series of fully connected layers responsible for mapping embeddings to probabilities of classes. In this context, your focus rests on training the classifier using the model's generated embeddings.
The attention layers of the LLM remain fixed and do not require further adjustments, leading to substantial savings in computational resources. However, to train the classifier, you must have a dataset rooted in supervised learning, comprising instances of text and their corresponding classes.
The extent of your fine-tuning dataset will hinge on the complexity of the task and the nature of the classifier component.
However, certain situations warrant updating the parameter weights of the transformer model. To achieve this, you would need to unfreeze the attention layers and execute a comprehensive fine-tuning process across the entire model.
Such an operation can be computationally intensive and intricate, contingent upon the model's size. (In select cases, it's feasible to retain certain model portions as frozen to mitigate fine-tuning costs. Various techniques are available to diminish the expenses associated with fine-tuning LLMs; we'll delve into this topic shortly.)
Unsupervised vs. Supervised Fine-Tuning (SFT)
Certain circumstances call for updating the knowledge base of the LLM without altering its behavior. Suppose you intend to fine-tune the model on medical literature or a new language. In these cases, an unstructured dataset comprising articles and scholarly papers from medical journals can prove effective.
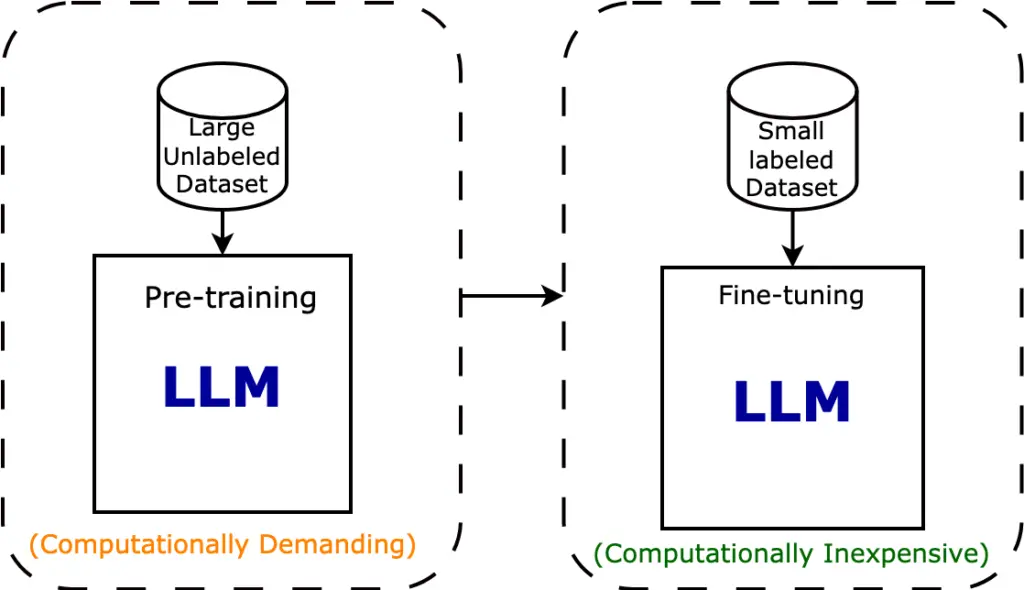
Figure: For a specific task, either go for Unsupervised Pretraining with a large unlabelled dataset or supervised fine-tuning with the small labeled dataset.
The objective is to train the model on a substantial volume of tokens that adequately represent the new domain or the specific input it will encounter in the target application.
Capitalizing on unstructured data offers scalability through unsupervised or self-supervised learning methodologies. Most foundational models are trained on unstructured datasets spanning billions of tokens.
Accumulating unstructured data for fine-tuning the model for a fresh domain can be relatively straightforward, particularly if you possess in-house knowledge repositories and documents.
Nevertheless, updating the model's knowledge base may prove insufficient in specific scenarios, prompting the desire to modify the LLM's behavior.
In such instances, a supervised fine-tuning (SFT) dataset becomes essential, comprising a compilation of prompts and their corresponding responses. These SFT datasets can either be curated manually by users or generated by other LLMs.
SFT becomes especially crucial for LLMs such as ChatGPT, engineered to follow user instructions and sustain a particular task over extensive text passages. This variant of fine-tuning is also referred to as instruction fine-tuning.
Reinforcement Learning from Human Feedback (RLHF)
Certain entities take supervised fine-tuning or instruction fine-tuning a step further, implementing reinforcement learning from human feedback (RLHF).
This intricate and resource-intensive process entails enlisting human evaluators and setting up auxiliary models to facilitate LLM fine-tuning. As of now, only organizations and AI research labs with considerable technical and financial resources can practically engage in RLHF.
Diverse RLHF techniques exist, but the core concept involves enhancing an LLM's training through human intervention. When training an LLM on massive volumes of tokens, it generates token sequences most likely to appear sequentially.
The text maintains coherency and intelligibility but may not fully align with user or application requirements. RLHF introduces human reviewers to guide the LLM toward desired outputs. Human reviewers rate the model's output for specific prompts, thereby informing the fine-tuning process to generate high-rated outputs.
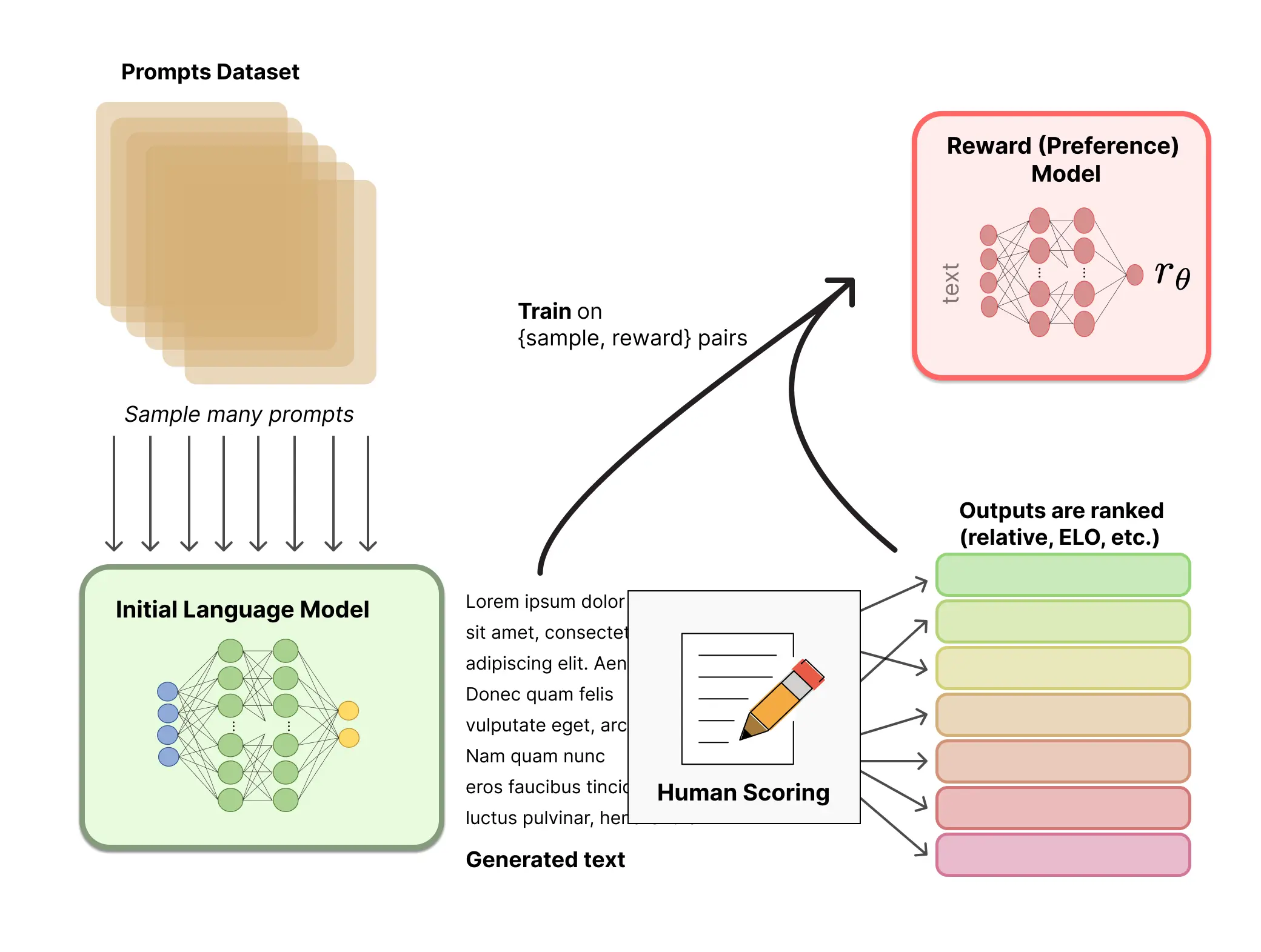
Figure: Reinforcement Learning from Human Feedback
A notable RLHF example is ChatGPT. OpenAI refined the model based on its InstructGPT research. Initially, a GPT-3.5 model underwent SFT using manually created prompts and responses.
Subsequently, human evaluators were enlisted to rate the model's output across various prompts. Human feedback data contributed to training a reward model that emulates human preferences.
The language model then underwent deep reinforcement learning, wherein it generates outputs, the reward model rates them, and the LLM optimizes its parameters to maximize rewards.
Parameter-Efficient Fine-Tuning (PEFT)
A noteworthy avenue of research within LLM fine-tuning explores strategies to reduce the expenses associated with updating model parameters. This endeavor is the essence of parameter-efficient fine-tuning (PEFT), a collection of techniques aiming to curtail the number of parameters requiring adjustments.
Various PEFT techniques exist, and one prominent example is a low-rank adaptation (LoRA), a technique gaining popularity among open-source language models.
LoRA operates on the premise that fine-tuning a foundational model for downstream tasks only necessitates updates across some parameters. Instead, a low-dimensional matrix can effectively represent the space related to the downstream task.
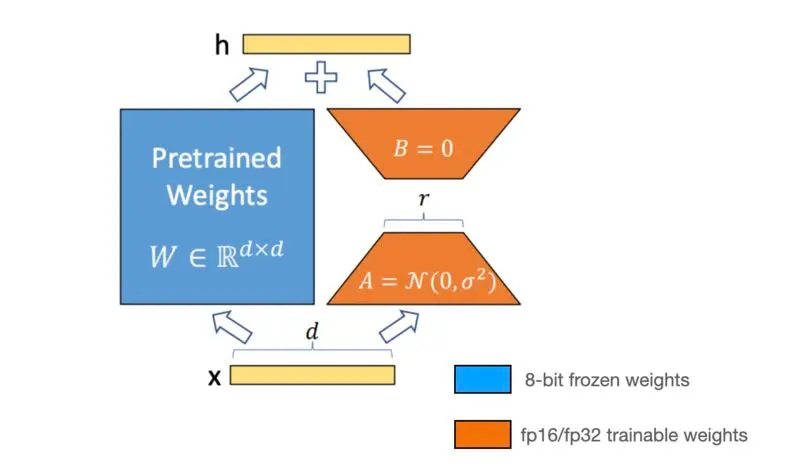
Figure: Parameter-Efficient Fine-Tuning (PEFT)
Incorporating LoRA involves training this low-rank matrix in lieu of adjusting the primary LLM's parameters.
The parameter weights of the LoRA model are subsequently integrated into the main LLM or incorporated during inference.
LoRA can dramatically reduce fine-tuning costs by up to 98 percent. Additionally, it facilitates the storage of multiple small-scale fine-tuned models that can be seamlessly integrated into the LLM during runtime.
Case Studies for Fine-tuning of LLMs
In the below section, we discuss some case studies where fine-tuning models (LLMs) have come in handy to solve real-world problems.
Enhancing Legal Document Analysis through LLM Fine-Tuning
Legal documents, characterized by intricate language and specialized terminology, pose a substantial obstacle.
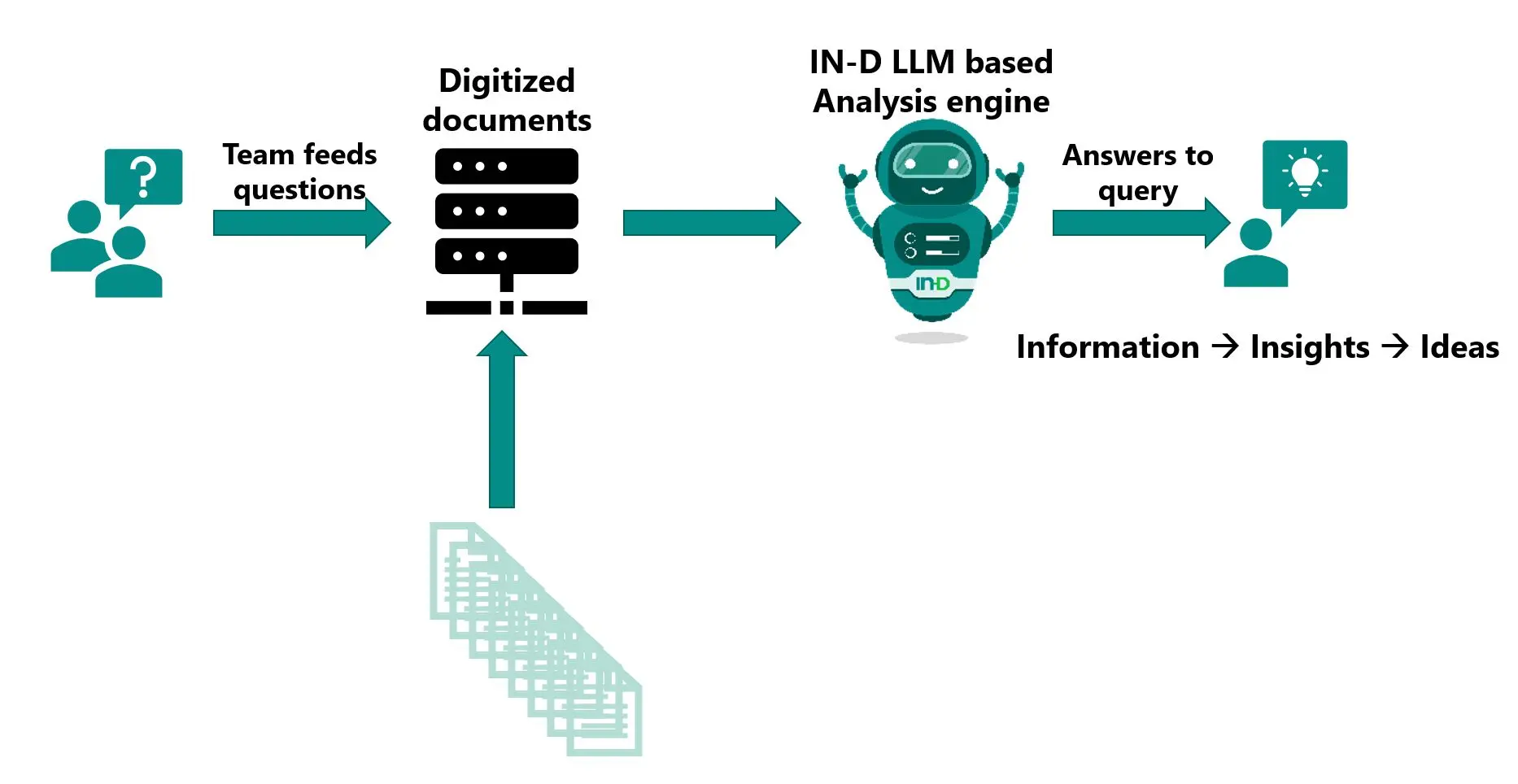
Figure: Enhancing Document Analysis via Integration of LLMs
Nevertheless, enterprises such as Lawgeex have effectively honed large language models (LLMs) through targeted fine-tuning utilizing a specific collection of legal texts. This process has resulted in the development of a model capable of swiftly and precisely evaluating and producing summaries for legal documents.
This implementation notably diminishes the time attorneys expend on document scrutiny, granting them the ability to allocate more attention to strategic responsibilities. This instance serves as a prominent illustration of how fine-tuning can metamorphose a generalized LLM into a specialized instrument.
Conclusion
In the ever-evolving landscape of artificial intelligence and machine learning, the role of large language models (LLMs) has been paramount. Their remarkable ability to comprehend and generate human language has unlocked unprecedented possibilities across various applications.
However, these models are more than one-size-fits-all solutions and might fall short in addressing specific tasks.
This comprehensive guide has shed light on the concept of fine-tuning LLMs, a technique that bridges the gap between pre-trained models and tailored applications. Fine-tuning involves recalibrating an existing model with new data, aligning it more closely with the specific requirements of a given task.
While this process can be complex and resource-intensive, its potential impact cannot be overstated, making it an indispensable tool for organizations integrating LLMs into their workflows.
By understanding the intricacies of fine-tuning, even if you lack the technical expertise to perform it yourself, you can effectively make informed decisions about leveraging LLMs.
We've explored the fundamental principles behind fine-tuning, delved into the selection of appropriate pre-trained models, and examined various approaches to refining model performance.
From repurposing models for new tasks to accommodating out-of-distribution data and utilizing supervised fine-tuning, this guide has offered a comprehensive overview of the techniques at your disposal.
Moreover, we've discussed reinforcement learning from human feedback and parameter-efficient fine-tuning as advanced strategies for enhancing LLM capabilities.
Several case studies have highlighted the real-world impact of fine-tuned LLMs. From revolutionizing legal document analysis to facilitating sentiment analysis in financial markets, these case studies underscore the transformative potential of this technique in diverse industries.
In essence, fine-tuning represents the fusion of pre-trained models with domain-specific expertise, enabling organizations to harness the full power of natural language processing for their unique requirements.
As technology continues to advance, the synergy between refined LLMs and human ingenuity holds the promise of unlocking new frontiers of innovation, efficiency, and understanding across countless applications.
Frequently Asked Questions
1. How do you instruction tune an LLM?
Typically, this process involves constructing a reward model (RM) that evaluates responses based on how well they match human preferences. Subsequently, this reward model is employed to refine the Large Language Model (LLM) by incorporating the corresponding scores. To begin, establish a reward model or heuristic.
2. What is the difference between fine-tuning and retraining LLM?
What sets apart fine-tuning from retraining an LLM is primarily the extent of data and computational resources needed.
Initiating the training process for an LLM starting from the ground up demands an extensive collection of textual data and substantial computational capabilities. On the other hand, fine-tuning necessitates a smaller data volume and reduced computational capacity.
3. How do fine-tuning and transfer learning differ?
Transfer learning encompasses the utilization of a pre-trained model as a foundation, whereas fine-tuning entails additional training of the pre-trained model for the new task by modifying its weights.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
