

Understanding YOLOv8 Architecture, Applications & Features
YOLOv8, the latest evolution of the YOLO algorithm, leverages advanced techniques like spatial attention and context aggregation, achieving enhanced accuracy and speed in object detection. This blog covers YOLOv8's architecture, applications, and unique features.


YOLO (You Only Look Once) is an object detection algorithm in the computer vision field.
This innovative deep learning model utilizes a single neural network to simultaneously predict bounding boxes along with class probabilities for each object in an image.
YOLOv8 is the latest version of the YOLO algorithm, which outperforms previous versions by introducing various modifications such as spatial attention, feature fusion, and context aggregation modules.
These improvements result in faster and more accurate object detection, making YOLOv8 one of the key object detection algorithms in the field.
Want to know more about YOLOv8?
Well, you’ve landed on the right place!
In this blog, we’ll discuss YOLOv8 in more detail, uncover its key features, architecture, and potential applications in real-world scenarios.

Figure: Object Detection using YOLOv8
Table of Contents
Key Features of YOLOv8
If you’re searching for a cutting-edge tool for objection detection tasks, YOLOv8 can be your perfect choice because of its numerous powerful features.
From pre-trained to custom models, YOLOv8 offers a variety of features to meet your unique needs.
Here are some key features of YOLOv8:
1. Improved Accuracy
This latest version enhances object detection accuracy compared to previous iterations by incorporating advanced techniques and optimizations that refine detection capabilities.
2. Enhanced Speed
Achieving faster inference speeds than other object detection models, this version maintains high accuracy, making it suitable for real-time applications.
3. Multiple Backbones
Support for various backbones, such as EfficientNet, ResNet, and CSPDarknet, provides users with the flexibility to select the best model based on their specific use case.
4. Adaptive Training
Utilizing adaptive training techniques optimizes the learning rate and balances the loss function during training, resulting in improved overall model performance.
5. Advanced Data Augmentation
Employing advanced data augmentation techniques like MixUp and CutMix enhances the model's robustness and generalization, allowing it to perform well across diverse datasets.
6. Customizable Architecture
The architecture is highly customizable, enabling users to modify the model's structure and parameters easily to fit their specific requirements.
7. Pre-Trained Models
Availability of pre-trained models facilitates easy use and transfer learning across various datasets, streamlining the deployment process for users.
Architecture
The YOLOv8 architecture is a state-of-the-art design that enhances object detection capabilities through its efficient structure, consisting of three main components: the Backbone, Neck, and Head.
Each part plays a vital role in processing and interpreting visual data to deliver accurate results.
Backbone
Function: The backbone, also known as the feature extractor, is crucial for extracting meaningful features from the input image.
Activities:
- Feature Extraction: Captures simple patterns in the initial layers, such as edges and textures.
- Hierarchical Representation: As the network processes the image, it can represent features at multiple scales, capturing information from different levels of abstraction.
- Rich Output: Provides a rich, hierarchical representation of the input, which forms the foundation for subsequent processing.
Details: YOLOv8 utilizes a custom CSPDarknet53 backbone, which employs cross-stage partial connections to improve information flow between layers and enhance detection accuracy.
Neck
Function: The neck serves as a bridge between the backbone and the head, performing feature fusion operations and integrating contextual information.
Activities:
- Feature Fusion: Merges feature maps obtained from different stages of the backbone to ensure the network can detect objects of various sizes.
- Context Integration: Integrates contextual information to improve detection accuracy by considering the broader context of the scene.
- Dimensionality Reduction: Reduces spatial resolution and dimensionality of resources, facilitating computation, which increases speed while potentially reducing model quality.
Details: Instead of the traditional Feature Pyramid Network (FPN), YOLOv8 employs a novel C2f module.
This module effectively combines high-level semantic features with low-level spatial information, significantly enhancing detection performance, particularly for small objects.
Head
Function: The head is the final part of the network and is responsible for generating the outputs, such as bounding boxes and confidence scores for object detection.
Activities:
- Bounding Box Generation: Produces bounding boxes associated with potential objects in the image.
- Confidence Scoring: Assigns confidence scores to each bounding box to indicate the likelihood of object presence.
- Category Sorting: Sorts the detected objects within the bounding boxes according to their respective categories.
Details: YOLOv8 employs multiple detection modules within the head, which predict bounding boxes, objectness scores, and class probabilities for each grid cell in the feature map.
These predictions are then aggregated to obtain the final detections.
Potential Applications
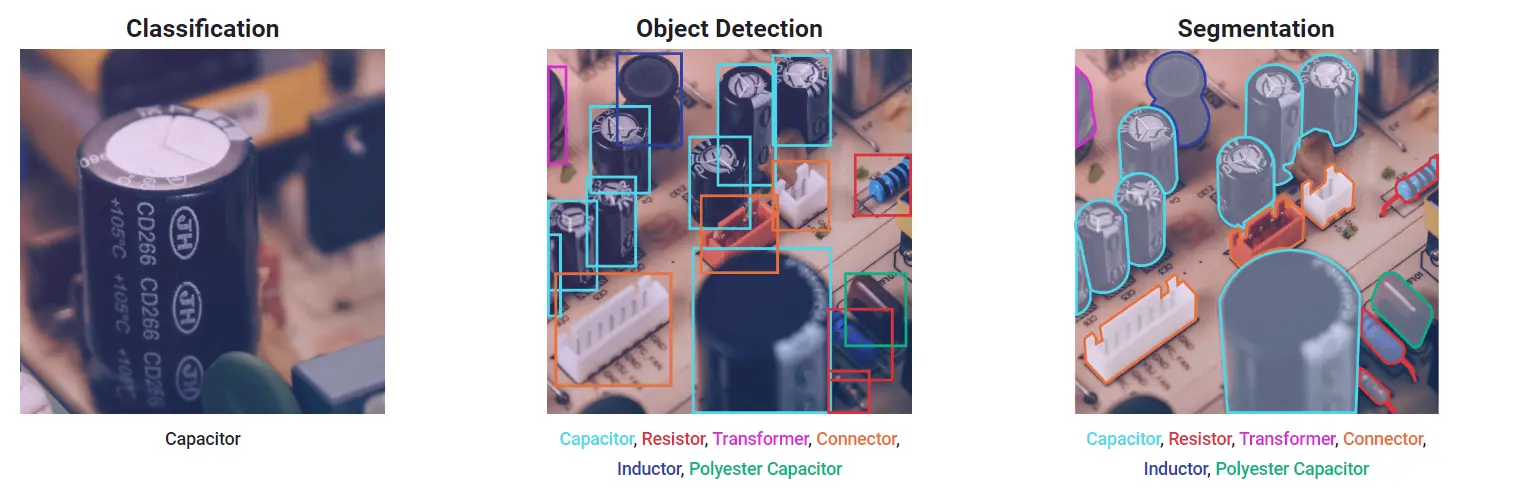
Figure: Potential Use Cases of YoloV8
YOLOv8 has various use cases in both object detection and image classification tasks. Here are some examples:
- Autonomous Vehicles: This model excels in real-time object detection for self-driving cars, enabling them to accurately detect and track other vehicles, pedestrians, and traffic signals. Its high-speed processing is crucial for safe navigation in complex environments.
- Surveillance: YOLOv8 enhances surveillance systems by detecting and tracking objects and individuals in real time. Its capability to identify unusual activities can significantly improve security measures in public spaces.
- Retail: In retail environments, this technology is used to monitor inventory levels, detect shoplifters, and analyze customer behavior. By automating these processes, retailers can optimize their operations and enhance the shopping experience.
- Medical Imaging: YOLOv8 can assist in medical imaging by detecting and classifying various anomalies and diseases, such as cancer, tumors, and fractures.
This application supports healthcare professionals in making accurate diagnoses and treatment decisions. - Agriculture: In the agricultural sector, the model is utilized to monitor crop growth, detect diseases, and identify pests.
This enables farmers to make informed decisions, improving yield and sustainability. - Robotics: This model empowers robots to recognize and interact with objects in their environment.
By providing real-time object detection capabilities, it enhances the robots' efficiency in various tasks, from warehouse operations to home assistance.
Conclusion
YOLOv8 represents a significant leap in the evolution of object detection technologies, showcasing an innovative architecture, advanced training methodologies, and impressive performance benchmarks.
This cutting-edge model enhances real-time object detection capabilities and sets a new standard for future innovations in the field.
As computer vision continues to progress, YOLOv8 emerges as a pivotal reference point, challenging and expanding the horizons of what can be achieved in object detection.
Its exceptional accuracy and versatility make it an ideal choice for various applications, from autonomous vehicles to surveillance systems.
How Labeller Can Help in Data Labeling?
To maximize the potential of YOLOv8, precise data labeling is crucial, and that’s where Labellerr comes into play. Labellerr acts as a vital partner in harnessing the power of YOLOv8 by ensuring that your data is meticulously annotated.
With our platform, users can easily define bounding boxes and assign matching labels to objects in images, creating the high-quality annotated data YOLOv8 requires for effective learning and recognition.
By utilizing Labellerr, you can enhance the accuracy and consistency of your labels, significantly boosting the performance and reliability of your trained model.
Our computer vision workflow automation platform streamlines the data preparation pipeline for machine learning teams of all sizes, making the process efficient and effective.
Don’t miss seeing how YOLOv8 can supercharge your computer vision projects!
Book a demo today to discover how our platform can accelerate your AI development and increase your object detection capabilities.
FAQs
What is YOLOv8?
YOLOv8 is the latest version of the YOLO (You Only Look Once) algorithm, which is designed for real-time object detection.
It builds upon previous iterations to improve accuracy and speed for detecting objects in images or video streams.
How does YOLOv8 work?
YOLOv8 uses a convolutional neural network (CNN) to predict bounding boxes and class probabilities for objects within an image.
It integrates advanced techniques like spatial attention and context aggregation, which help to improve both accuracy and inference speed during object detection tasks.
What are some applications of YOLOv8?
YOLOv8 can be applied to a wide range of object detection tasks, including instance segmentation, pose/keypoints detection, oriented object detection, and general image classification.
It is versatile and suitable for real-time applications across various industries.
Why is YOLOv8 significant?
YOLOv8 is significant because it outperforms earlier versions of YOLO in terms of both inference speed and accuracy.
These improvements make it especially suitable for real-time object detection applications where performance is crucial, such as autonomous driving, video surveillance, and robotics.
How is YOLOv8 trained?
YOLOv8 uses adaptive training techniques and advanced data augmentation methods to optimize its model.
It also supports multiple backbone networks, enabling it to be trained for a variety of detection tasks and achieve high performance across different use cases.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
