

DINO: Unleashing the Potential of Self-Supervised Learning
DINO leverages self-supervised learning to generate visual features for tasks without human labels. Enhanced in DINOv2 by Meta AI, it uses improved training and data pipelines, setting a new standard for computer vision foundation models


Self-supervised learning is a type of machine learning in which a model is trained to perform a task without requiring explicit human annotation or labels.
Instead, the model learns to identify patterns and relationships within the data using its internal representations.
Self-supervised learning has succeeded in Natural Language Processing (NLP) and is now applied to Computer Vision (CV) tasks.
DINO has shown promising results in generating visual features for subsequent tasks and has been further improved upon in DINOv2 by Meta AI, which builds upon its predecessor's success while improving its training process, data pipeline, and model architecture.
Table of Contents
- Foundation Model for Computer Vision
- New Emergent Properties in Self-Supervised Vision Transformers with DINO
- Introduction to DINOV2
- Data Pipeline for DINOV2
- Training Details
- Performance of DINOV2
- Conclusion
- Frequently Asked Question
Foundation Model for Computer Vision
.webp)
Figure: A Foundational Model
In recent years, foundation models, particularly large transformers, have significantly impacted Natural Language Processing (NLP) by improving language understanding tasks.
Given the success of this approach, researchers have also sought to apply self-supervised learning using large transformers in Computer Vision (CV) tasks.
The idea behind this approach is that a model should generate visual features that can be used for subsequent tasks, similar to how language models generate language embeddings.
However, one limitation of supervised learning in CV is the need for a large amount of labeled data. This is not the case for NLP, where large amounts of data can be collected without the cost of labeling.
Self-supervised learning, which is the training of a model using a pretext task (i.e., a task that does not require labeled data), has the advantage of not requiring labeled data.
This makes it a suitable approach for CV tasks, and the recently introduced DINO model has shown promising results in generating visual features for subsequent tasks.
By training using self-supervised learning, DINO can provide visual features that can be used in simple models, eliminating the need for fine-tuning a model for a new task.
New Emergent Properties in Self-Supervised Vision Transformers with DINO
DINO (Deeper Into Neural Networks) is a self-supervised learning method introduced in 2021 by researchers at Facebook AI Research. DINO aims to learn a global image representation from local views of the image.
This is achieved using two networks, a teacher and a student, with the same architecture.
During training, the images undergo a specific cropping process, where local views (small crops <50% of the image) and global views (large crops >50% of the image) are used for the student model. In contrast, the teacher model only sees global views.
This allows the student to learn how to interpolate context from a small crop (local to global).
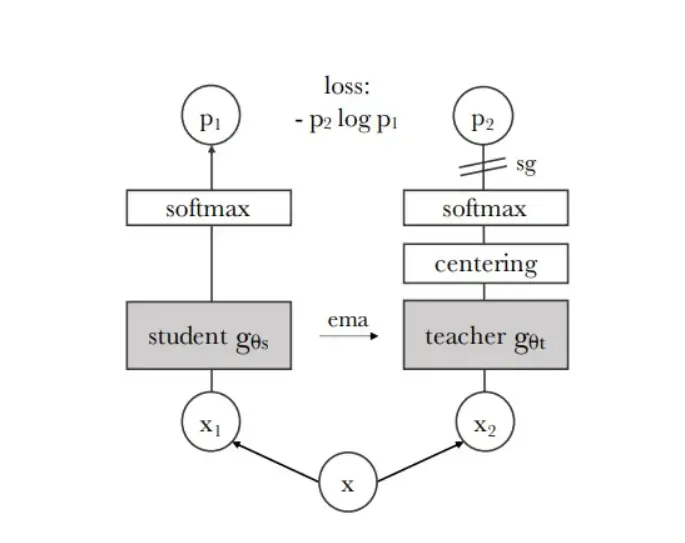
Figure: Teacher Student Architecture
The teacher is a momentum teacher whose weights are an exponentially weighted average of the student model.
The purpose of training is for the teacher model to predict high-level features, and the student must match this prediction using cross-entropy to make the two distributions similar.
In other words, the student is trained to mimic the teacher's output.
Self-distillation allows the student model to learn from its predictions rather than relying on external labels. This makes DINO a self-supervised learning method that doesn't require manual data annotation.
One interesting aspect of DINO is that it uses attention maps to visualize how the model is learning to represent images.
The attention maps show that DINO has learned about the objects within the images, indicating that the model is learning to recognize objects and their relationships.
Introduction to DINOV2
Meta AI has introduced DINOv2, a new method for training high-performance computer vision models. DINOv2 builds upon the success of its predecessor DINO, but with improvements that make it even more powerful.
DINOv2 delivers strong performance without requiring fine-tuning, which makes it suitable as a backbone for a wide range of computer vision tasks.
This is made possible by DINOv2's use of self-supervision, which means it can learn from any collection of images without the need for external labels.
One notable advantage of DINOv2 is its ability to learn features such as depth estimation, which the current standard approach cannot do.
Self-supervised learning approaches in computer vision have been limited by using pretraining contexts and small curated datasets, which failed to induce models to produce meaningful features.
To overcome this paradox of needing a large and diverse dataset while also wanting it to be curated, the authors decided to build a pipeline to obtain a curated (filtered, class-balanced) dataset from a large amount of data.
Data Pipeline for DINOV2
To create a large and diverse dataset for training the DINOv2 model, Meta AI started by collecting data from various sources, including previously curated datasets and images crawled from the web.
They filtered out images from unsafe or restricted domains unsuitable for use.
They used principal component analysis (PCA) to remove duplicates in the benchmark dataset and validation set to ensure that the dataset did not contain duplicates.
Additionally, Meta AI created a curated dataset using image embedding, which enabled them to find similar images from uncurated sources and thus increase the dataset size.
The final result was a dataset containing 142 million images, providing a diverse and comprehensive data collection for training the DINOv2 model.
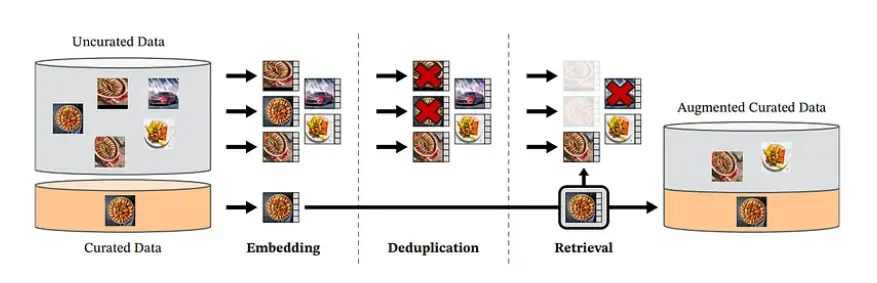
Figure: Data Curation Pipeline
Training Details
In their implementation of DINOv2, the authors opted to use various vision transformers while following a similar approach to that of DINOv1, with some tweaks to increase speed (2x faster) and reduce memory usage (1/3 less).
Since the training of DINOv2 already involves knowledge distillation from the teacher model to the student model, the authors decided to further distill smaller models from the wider models.
These smaller models have also been made available as open source.
Observations While Curating Dataset
During the training of DINOv2, experiments were conducted to determine the importance of a curated dataset. They found that:
- Models trained on curated data perform better.
- Performance scales with the amount of data.

Figure: Performance vs. Model Size. Performance evolution as a function of model size for two pretraining datasets: ImageNet-22k (14M pictures) and LVD-142M (142M images).
From the above figure, we see that on most benchmarks, the ViT-g trained on LVD-142M outperforms the ViT-g trained on ImageNet-22k.
While the latter may seem obvious, it represents a shift from the traditional model-centric approach to training models with more parameters and training, as outlined in OpenAI's power law.
Instead, the focus is on data quality and ensuring that the dataset is curated and diverse.
Further, it was also observed that a model distilled from a larger one performs better than a similar model trained from scratch.
This means that distilling a smaller, lighter model from a larger one is more effective than training a small model from scratch.
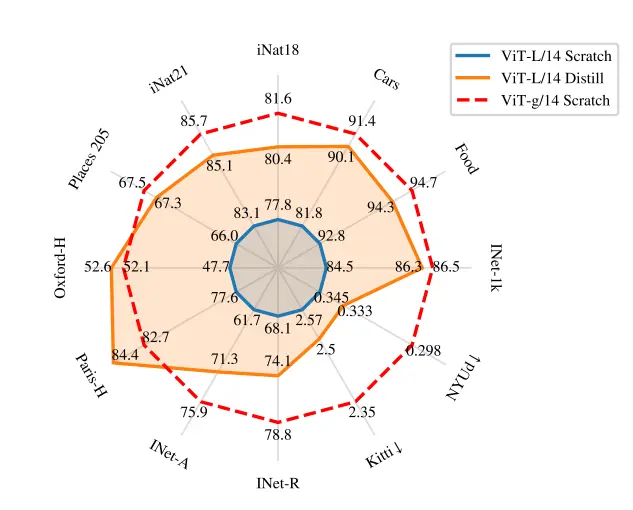
Figure: Comparison in metrics of Different models
This approach is particularly useful when a lightweight model is needed for computational efficiency or faster inference times.
Next, it was also observed that training a model with high-resolution images yields better performance but is computationally expensive.
Instead of training the entire model with high-resolution images, training just the last 10,000 iterations is sufficient for achieving similar performance without the added computational cost.
The authors used a frozen backbone to extract features and created a simple classification network.
They compared their approach with state-of-the-art weakly supervised models for classification and found that their approach outperforms theirs.
Performance of DINOV2
The authors also showed that the model can be used for various downstream tasks, from segmentation to depth estimation. In other words, they created a foundation model.
The authors performed PCA on patch features extracted by the model and found that it allows objects to be separated from the background.
The first component can delineate the object boundary, while other components highlight different parts of the object.
This is an emerging property of the model since it was not an objective during training.
This property is consistent across images from domains with similar semantic information, indicating the model can transfer and understand relationships between similar parts of different objects.
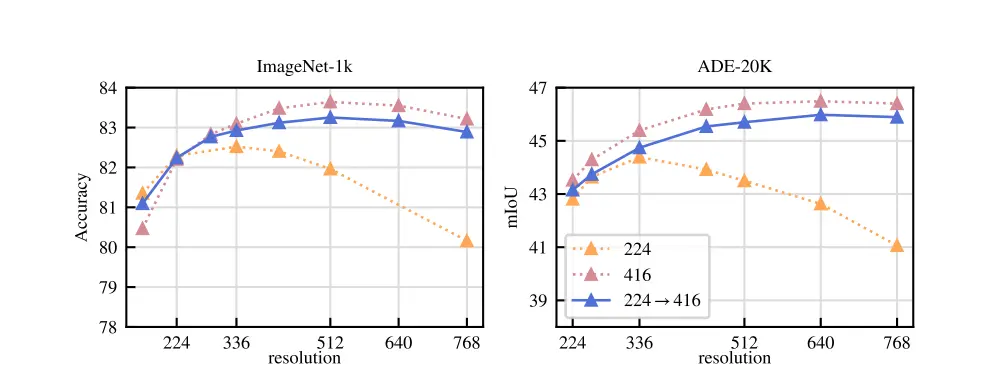
Figure: Role of resolution
Conclusion
In the above blog, we discuss how DINO demonstrates the effectiveness of self-supervised learning in computer vision by achieving competitive performance without the need for fine-tuning.
We also examined the importance of data quality and cost-effective ways to obtain curated data. The authors' work showcases META's focus on developing foundation and open-source compatible models with recent releases such as LLaMA and SAM.
Further, work demonstrates that self-supervised learning can be more effective than image-text pretraining in computer vision, as the latter may lead to the model ignoring important image information.
DINO and similar approaches address the bottleneck of image labeling and reduce the need for expensive and time-consuming data annotation.
These methods can potentially enable the scaling of models even in fields where data annotation is still necessary, such as in biological and medical applications.
Frequently Asked Question
1. What is Dino self-supervised learning?
DINO, also known as self-distillation with no labels, is an approach to self-supervised learning. It involves predicting the output of a teacher network, which is constructed using a momentum encoder, using a cross-entropy loss without the need for labeled data.
2. Is Dino a foundation model?
DINOv2, developed by Meta AI Research, is a foundational computer vision model that has been made available as open-source.
It has been pretrained on a carefully selected dataset containing 142 million images. DINOv2 can serve as a fundamental component for various computer vision tasks such as image classification, video action recognition, semantic segmentation, and depth estimation.
3. What is the difference between Dino and Dino v2?
DINOv2, developed by Meta AI Research, is a foundational computer vision model that has been made available as open-source. It has been pretrained on a carefully selected dataset containing 142 million images. DINOv2 can serve as a fundamental component for various computer vision tasks such as image classification, video action recognition, semantic segmentation, and depth estimation.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
