

Development Of Large Language Models: Methods and Challenges
Explore key techniques and challenges in developing large language models (LLMs) like GPT-4, from scaling laws to alignment tuning. Discover datasets and resources that enhance LLM capabilities in NLP applications.


Table of Contents
- Introduction
- Key Techniques for LLMs
- Commonly Used Dataset
- Library Resources
- Conclusion
- Frequently Asked Questions?
Introduction
Language models have become increasingly successful in recent years, especially large language models (LLMs) like GPT-4. These models have shown remarkable abilities in various natural language processing (NLP) tasks, such as text generation, language translation, question-answering, and more.
Their success can be attributed to their ability to learn from large amounts of text data and sophisticated architecture and training methods.
Moreover, LLMs have opened up new possibilities for various applications in artificial intelligence (AI) and NLP. For example, they have been used to improve chatbots, automated content generation, and voice assistants.
They have also been used for scientific research, including drug discovery and climate modeling. Despite the progress and impact that LLMs have made, several challenges still need to be addressed.
Firstly, it is unclear why LLMs can achieve superior abilities compared to smaller models.
Secondly, training LLMs require significant computational resources, making it challenging for researchers to explore various training strategies.
Thirdly, LLMs can produce toxic or harmful content, making it important to align their outputs with human values and preferences.
To provide a basic understanding of LLMs, the article reviews recent advances from four major aspects: pre-training, adaptation tuning, utilization, and capability evaluation.
Pre-training refers to how to train a capable LLM, while adaptation tuning refers to how to tune pre-trained LLMs for specific tasks effectively.
Utilization refers to using LLMs for solving various downstream tasks, while capability evaluation refers to evaluating the abilities of LLMs and existing empirical findings.
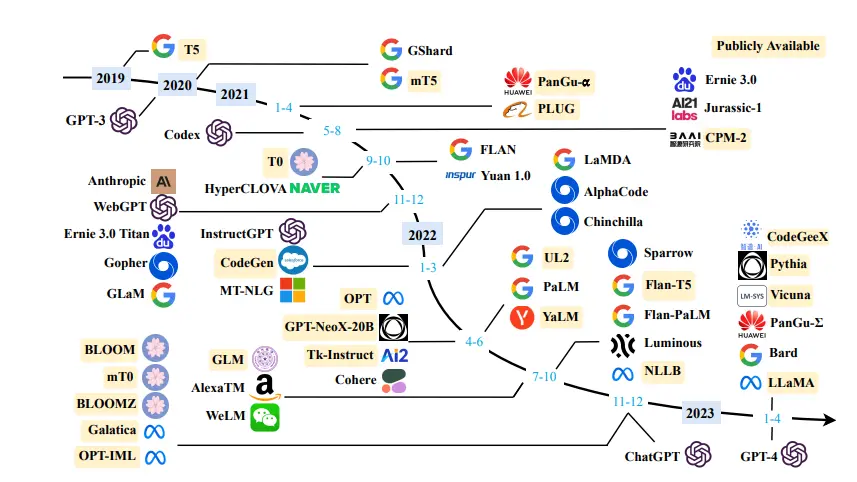
Figure: A timeline of existing large language models.
Key Techniques for LLMs
LLMs have undergone significant evolution to become the versatile learners they are today.
Along the way, many essential techniques have been proposed that have significantly increased the capabilities of LLMs. Here, we provide a concise overview of some key techniques that have contributed to the success of LLMs.
Scaling Law
The scaling effect in Transformer language models refers to how larger model/data sizes and more training compute can improve the model capacity. GPT-3 and PaLM are examples of models that have explored the scaling limits by increasing the model size to 175B and 540B, respectively.
Scaling laws like Chinchilla can be employed to allocate compute resources more efficiently, which outperforms its counterpart model, Gopher, by increasing the data scale with the same compute budget.
However, it is essential to carefully clean the pre-training data since the quality of data plays a crucial role in the model capacity.
Model Training
Training large language models (LLMs) is challenging due to their huge size. To overcome this, distributed training algorithms are required, which use various parallel strategies.
Optimization frameworks such as DeepSpeed and Megatron-LM have been developed to facilitate the implementation and deployment of parallel algorithms.
Optimization tricks such as restart and mixed precision training are also important for training stability and model performance. GPT-4 proposes developing special infrastructure and optimization methods to reliably predict the performance of large and smaller models.
Ability eliciting
Large language models (LLMs) are pre-trained on large-scale corpora and have the potential abilities of general-purpose task solvers. However, these abilities may not be evident when performing specific tasks.
Suitable task instructions or in-context learning strategies can be designed to elicit these abilities. For instance, chain-of-thought prompting can solve complex reasoning tasks, and instruction tuning with natural language task descriptions can improve generalizability on unseen tasks.
For instance, Chain-of-thought prompting, which involves providing intermediate steps in reasoning tasks, has effectively solved challenging problems.
Additionally, we can modify the instructions given to LLMs using English language task descriptions to enhance their ability to handle new and unseen problems.
While these approaches primarily address the developing skills of LLMs, they may not have a comparable impact on smaller language models.
These techniques are specific to LLMs and may not be effective for smaller language models.
Alignment Tuning
LLMs are trained on pre-training corpora that include high-quality and low-quality data, making them likely to generate toxic, biased, or harmful content for humans. Therefore, aligning LLMs with human values, such as being helpful, honest, and harmless, is necessary.
InstructGPT is a tuning approach that utilizes reinforcement learning with human feedback to enable LLMs to follow expected instructions. It incorporates humans in the training loop with elaborately designed labeling strategies. ChatGPT is developed using a similar technique too.
InstructGPT shows a strong alignment capacity by producing high-quality and harmless responses such as rejecting to answer insulting questions.
Tools Manipulation
LLMs are primarily trained as text generators and may not perform well on tasks not best expressed in text, such as numerical computation. Additionally, their capacities are limited to the pre-training data, and they may be unable to capture up-to-date information.
To overcome these limitations, an approach is to use external tools such as calculators for accurate computation and search engines to retrieve unknown information.
Recently, ChatGPT has enabled the use of external plugins, which can expand the scope of capacities for LLMs, analogous to the "eyes and ears" of LLMs.
Commonly Used Dataset
In this section, we discuss a summary of various training datasets used for large language models (LLMs). Compared to earlier language models, LLMs have significantly larger parameters and require more training data covering diverse content.
Numerous training datasets have been made available for research to meet this requirement. These corpora are categorized into six groups based on their content types: Books, CommonCrawl, Reddit links, Wikipedia, Code, and others.
Books
The BookCorpus is a well-known dataset used in earlier small-scale language models such as GPT and GPT-2. It includes over 11,000 books that cover a diverse range of genres and topics, including novels and biographies.
Another significant book corpus is Project Gutenberg, which contains over 70,000 literary books, including essays, poetry, drama, history, science, philosophy, and other works that are in the public domain.
This open-source book collection is one of the largest and is used in training MT-NLG and LLaMA. The Books1 and Books2 datasets used in GPT-3 are much larger than BookCorpus but have not been made publicly available.
Common Crawl
CommonCrawl is a vast open-source web crawling database frequently used as training data for LLMs. Due to the presence of noisy and low-quality information in web data, data preprocessing is necessary before usage.
Four filtered datasets are commonly used in existing works based on CommonCrawl: C4, CCStories, CC-News, and RealNews.
The Colossal Clean Crawled Corpus (C4) includes five variants: en, en.noclean, realnewslike, webtextlike, and multilingual.
The en version has been utilized for pre-training T5, LaMDA, Gopher, and UL2, while the multilingual C4 has been used in mT5.
Additionally, two news corpora extracted from CommonCrawl, REALNEWS, and CC-News, are commonly used as pre-training data.
Reddit Links and Posts
Reddit is a social media platform that allows users to submit links and text posts that others can vote on. Highly upvoted posts can be used to create high-quality datasets.
WebText is a popular corpus composed of highly upvoted links from Reddit, but it is not publicly available. However, an open-source alternative called OpenWebText is available.
PushShift.io is another dataset extracted from Reddit that consists of historical data from the creation day of Reddit, which is updated in real-time.
PushShift provides monthly data dumps and utility tools to help users search, summarize, and investigate the entire dataset, making it easy to collect and process Reddit data.
Wikipedia
Wikipedia is a widely used dataset in LLMs and an online encyclopedia containing many high-quality articles covering diverse topics. These articles are composed in an expository writing style and typically have supporting references.
The English-only filtered versions of Wikipedia are commonly used in most LLMs, including GPT-3, LaMDA, and LLaMA. Wikipedia is also available in multiple languages, making it useful for multilingual settings.
Codes Available
Existing work on collecting code data for LLMs involves crawling open-source licensed codes from the internet. The two major sources for this are public code repositories (such as GitHub) and code-related question-answering platforms (such as StackOverflow).
Google has released the BigQuery dataset, which includes many open-source licensed code snippets in various programming languages.
CodeGen has used a subset of the BigQuery dataset, called BIGQUERY, to train the multilingual version of CodeGen (CodeGen-Multi).
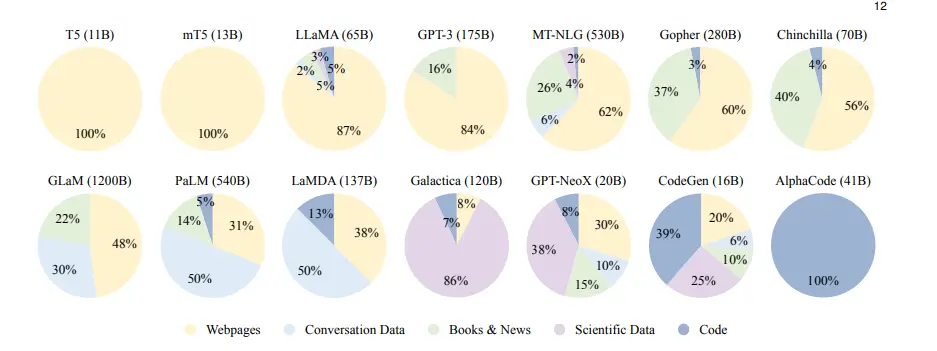
Figure: Contribution of Different Data Sources in the Development of LLMs
Library Resources
In this segment, we will discuss the libraries which are available of developing LLMs (Large Language Models).
Transformers
Transformers is a Python library for building models using the Transformer architecture. It is open-source and maintained by Hugging Face. The library has a user-friendly API, making it easy to use and customize pre-trained models.
Transformer is a powerful library with a large and active community of users and developers who regularly update and improve the models and algorithms.
DeepSpeed
DeepSpeed is a deep learning optimization library compatible with PyTorch and has been used to train several large language models, including MTNLG and BLOOM.
Developed by Microsoft, it supports various optimization techniques for distributed training, such as memory optimization, gradient checkpointing, and pipeline parallelism.
![]()
Figure: DeepSpeed Library
Megatron-LM
Megatron-LM is a deep learning library developed by NVIDIA specifically for training large-scale language models. It supports distributed training using various techniques, including model and data parallelism, mixed-precision training, and FlashAttention.
These techniques help to improve training efficiency and speed, making it possible to train large models across multiple GPUs efficiently.
JAX
JAX is a Python library developed by Google for high-performance machine learning algorithms. It enables efficient computation on various devices and supports features such as automatic differentiation and just-in-time compilation.
JAX allows users to easily perform computations on arrays with hardware acceleration (e.g., GPU or TPU).
Colossal-AI
Colossal-AI is a deep learning library used for training large-scale AI models. It is implemented using PyTorch and supports a variety of parallel training strategies.
It is also capable of optimizing heterogeneous memory management using methods proposed by PatrickStar.
ColossalChat is a recently released ChatGPT-like model that was developed using Colossal-AI and is available in two versions: 7B and 13B. These models were trained using LLaMA, a large-scale language model pretraining method.

Figure: Colossal - AI
BMTrain
BMTrain is an open-source library developed by OpenBMB for training large-scale models in a distributed manner, emphasizing code simplicity, low resource usage, and high availability.
It includes a ModelCenter with several pre-implemented LLMs, such as Flan-T5 and GLM that developers can use directly.
Conclusion
In conclusion, large language models (LLMs) have made significant strides in recent years, particularly with models like GPT-3. They can perform various natural language processing tasks, including text generation, language translation, and question-answering.
The success of LLMs is due to their ability to learn from large amounts of text data and their complex architecture and training techniques.
However, several challenges still need to be addressed, such as understanding why LLMs are so successful and aligning their outputs with human values and preferences.
LLMs have evolved significantly to become the versatile learners they are today, and several key techniques have contributed to their success.
These techniques include scaling laws, model training, ability eliciting, alignment tuning, and tool manipulation.
Regarding training datasets, various corpora are available for LLMs, which cover diverse content, such as books, CommonCrawl, Reddit links, Wikipedia, and code. These datasets are essential in improving the capabilities of LLMs.
Unsure which large language model to choose?
Read our other blog on the key differences between GPT-4 and Llama 2.
Frequently Asked Questions?
1. What are the challenges of large language models?
Data and bias present significant challenges in the development of large language models. These models heavily rely on internet text data for learning, which can introduce biases, misinformation, and offensive content. Failure to effectively address these issues can lead to the perpetuation of harmful stereotypes and influence the outputs produced by the models.
2. What are some large language models?
Several large language models have been developed, such as OpenAI's GPT-3 and GPT-4, Meta's LLaMA, and Google's PaLM2. These models can comprehend and generate text, demonstrating significant advancements in natural language understanding and generation.
3. What are the advantages of large language models?
Large language models offer numerous benefits, one of which is their ability to generate natural language. These models excel at producing text or speech that closely resembles human language, making them valuable for applications such as chatbots, virtual assistants, and content creation.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
