

How To Enhance Performance and Task Generalization in LLMs


From the previous blog, we studied that Pre-training forms the foundation of LLMs' abilities. LLMs acquire crucial language comprehension and generation skills through pre-training on extensive corpora.
The size and quality of the pre-training corpus play a vital role in enabling LLMs to possess powerful capabilities. Moreover, the design of model architectures, acceleration methods, and optimization techniques is essential for the effective pre-training of LLMs.
LLMs, after undergoing pre-training, possess general capabilities to tackle various tasks. However, recent studies have demonstrated that these abilities can be further adjusted based on specific objectives.
In this blog, we introduce two primary methods for adapting pre-trained LLMs: instruction tuning and alignment tuning.
Instruction tuning focuses on enhancing or unlocking LLMs' abilities, while alignment tuning aims to align LLM behaviors with human values or preferences.
Additionally, efficient tuning techniques for rapid model adaptation will be discussed. The following parts will provide a detailed explanation of these three aspects.
Table of Contents
- Instruction Tuning
- Formatted Instance Construction
- Formatting Existing Datasets
- Formatting Human Needs
- Instruction Tuning Strategies
- Combining Instruction Tuning and Pre-Training
- Conclusion
Instruction Tuning
Instruction tuning is an approach that involves fine-tuning pre-trained LLMs using a collection of formatted instances represented in natural language. It is closely related to supervised fine-tuning and multi-task prompted training.
To perform instruction tuning, formatted instances in the form of instructions need to be collected or created. These instances are then used to fine-tune LLMs through supervised learning, such as training with sequence-to-sequence loss.
After instruction tuning, LLMs exhibit enhanced generalization abilities, even across unseen tasks and in multilingual settings.
This approach has been widely applied in existing LLMs, such as InstructGPT and GPT-4, and has been the subject of research and investigation.
This section focuses on the impact of instruction tuning on LLMs, offering detailed guidance and strategies, for instance, collection and tuning, along with its practical application to meet users' real needs.
Formatted Instance Construction
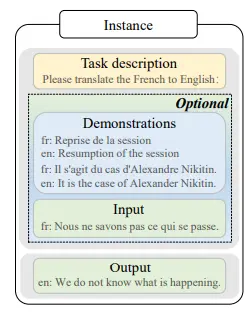
Figure: Instance Format
In instruction-formatted instances, a task description (an instruction), an input-output pair, and a few demonstrations are included optionally.
This section introduces two main approaches for constructing formatted instances, illustrated in the above figure, and discusses important factors to consider during instance construction.
Formatting Existing Datasets
Before instruction tuning was introduced, previous studies collected instances from various tasks, such as text summarization, text classification, and translation, to create supervised multi-task training datasets.
These datasets were used as a source for instruction tuning instances by formatting them with natural language task descriptions.
Recent work has augmented these labeled datasets with human-written task descriptions, which serve as instructions for LLMs to understand the tasks and their goals.
Including task descriptions has proven to be crucial for the generalization ability of LLMs, as fine-tuning the model without the task descriptions significantly reduces its performance. To generate labeled instances for instruction tuning, a crowd-sourcing platform called
PromptSource has been proposed to effectively create, share, and verify task descriptions for different datasets.
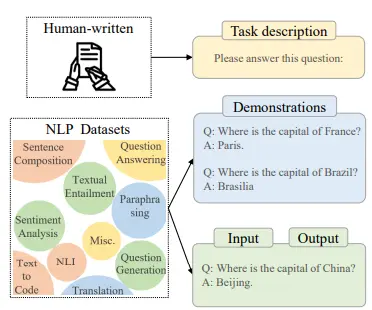
Figure: Formatting Existing Datasets
Additionally, researchers have explored methods such as inverting input-output pairs and utilizing heuristic task templates to enrich the training instances for instruction tuning.
Formatting Human Needs
InstructGPT proposes using real user queries submitted to the OpenAI API as task descriptions to address the limitations of existing instruction-formatted instances. These user queries, expressed in natural language, effectively evaluate the instruction-following ability of LLMs.
To increase the diversity of tasks, human labelers compose instructions for real-life scenarios such as open-ended generation, open-question answering, brainstorming, and chatting.
Another group of labelers provides the corresponding answers to these instructions, forming training instances with one instruction (the user query) and the expected output (the human-written answer).
These real-world tasks in natural language are also utilized for alignment tuning. For safety concerns, GPT-4 incorporates potentially high-risk instructions and guides the model to reject them through supervised fine-tuning.
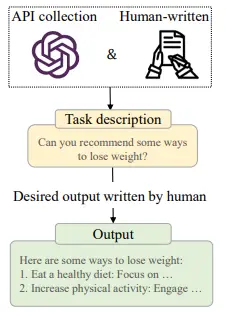
Figure: Formatting Human Needs
Several semi-automated approaches have been proposed to alleviate the burden of human annotation, leveraging LLMs to generate diverse task descriptions and instances by feeding existing instances as input.
Instruction Tuning Strategies
Instruction tuning is more efficient than pre-training as it involves training with a moderate number of instances.
It is considered a supervised training process and differs from pre-training in various aspects, including the training objective (sequence-to-sequence loss) and optimization configuration (e.g., smaller batch size and learning rate).
These differences require careful attention in practice. Alongside optimization configurations, there are two crucial aspects to consider in instruction tuning:
Balancing the Data Distribution
Balancing the distribution of different tasks during fine-tuning is crucial to ensure effective instruction tuning.
A commonly used approach is the examples-proportional mixing strategy, where all the datasets are combined, and each instance is sampled equally from the mixed datasets.
Recent studies have shown that increasing the high-quality collections' sampling ratio can improve performance.
However, to prevent larger datasets from dominating the training, a maximum cap is often set to control the number of examples in each dataset during instruction tuning.
This cap is typically set to several thousand or tens of thousands based on the specific datasets.
Combining Instruction Tuning and Pre-Training
To enhance the effectiveness and stability of the tuning process, OPT-IML incorporates pre-training data during instruction tuning, serving as a form of regularization for model tuning.
Instead of following a two-stage pre-training process and then instruction tuning, some studies explore training a model from scratch using pre-training data (unformatted plain texts) and instruction tuning data (formatted datasets) through multi-task learning.
For instance, models like GLM-130B and Galactica integrate instruction-formatted datasets as a small portion of the pre-training corpora, aiming to leverage the benefits of both pre-training and instruction tuning simultaneously.
Conclusion
In conclusion, instruction tuning is a powerful approach for enhancing the capabilities of Language Models (LLMs). By fine-tuning pre-trained LLMs using a collection of formatted instances represented in natural language, LLMs can exhibit enhanced generalization abilities across various tasks and multilingual settings.
Instruction tuning has been successfully applied in existing LLMs like InstructGPT and GPT-4 and has been the subject of extensive research.
Formulating formatted instances involves formatting existing datasets with task descriptions, augmenting them with human-written instructions, and utilizing real user queries to evaluate instruction-following ability.
Balancing the data distribution and combining instruction tuning with pre-training are important strategies to ensure effective tuning.
By leveraging the benefits of both pre-training and instruction tuning, LLMs can achieve improved performance and stability, making instruction tuning an efficient and valuable technique for enhancing LLMs' capabilities.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
