

How to enhance LLM’s Data Annotation Performance with Few-Shot Chain of Thought Process

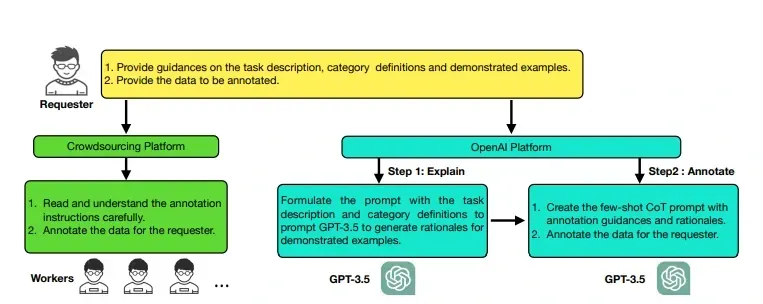
Table of Contents
- Introduction
- The Power of Labeled Data Augmentation
- 'Explain-Then-Annotate' Approach
- How to Enhance Annotation Instructions with GPT-3.5
- GPT-3.5 as a Zero-shot Data Annotator
- GPT-3.5 as a Few-shot Data Annotator
- How to Generate Explanations with GPT-3.5
- Exploring the Potential of Few-Shot CoT
- What is the Future of Data Annotation
- Conclusion
- Frequently Asked Questions
Introduction
In the realm of Natural Language Processing (NLP), the acquisition of labeled data has always been a labor-intensive and costly endeavor. Labeled data, enriched with predefined target labels or categories, is the bedrock upon which machine learning models for NLP tasks like sentiment analysis, machine translation, and word sense disambiguation are built. Traditionally, this labeling process has relied on human annotators following strict guidelines, but the demand for labeled data often far outstrips the available resources. However, a revolutionary shift has occurred with the advent of large-scale pre-trained language models (LLMs) like GPT-3.5.
These models, trained on massive amounts of text and code, have displayed remarkable few-shot and zero-shot capabilities across a wide array of NLP tasks. In this blog, we delve into the innovative approach of using LLMs, specifically GPT-3.5, to annotate data, thus reducing reliance on human annotators. We learn the construction of few-shot chain-of-thought prompt with the self generated explanations to annotate the data.
The Power of Labeled Data Augmentation
Labeled data is the lifeblood of NLP models, but obtaining it can be akin to searching for a needle in a haystack. The conventional process of manual annotation by human annotators is resource-intensive, slow, and often constrained by budget limitations. This bottleneck has led researchers to investigate alternatives, and the results have been nothing short of groundbreaking.
Recent studies have showcased the ability of LLMs like GPT-3.5 to augment manually labeled data with pseudo-labeled data. This augmentation has proven highly effective, especially when faced with limited labeling budgets. However, it's essential to acknowledge that the quality of LLM-generated labels still trails behind human-annotated data.
'Explain-Then-Annotate' Approach
To bridge this quality gap, a new approach emerges—'explain-then-annotate.' Leveraging the power of ChatGPT, a fine-tuned version of GPT-3.5, researchers have devised a strategy that not only instructs LLMs on the task but also prompts them to provide rationale behind their labels.
By constructing a few-shot chain-of-thought prompt with self-generated explanations, the annotation quality is substantially improved. This groundbreaking approach is a game-changer, as it combines the versatility and speed of LLMs with the meticulousness of human annotation. The result is a labeling process that often outperforms crowdsourced annotators.
How to Enhance Annotation Instructions with GPT-3.5
Annotating data through crowdsourcing relies heavily on the clarity and comprehensibility of the instructions given to human annotators. These instructions typically encompass three key components: the task description, category definitions, and demonstrated examples.
This meticulous guidance ensures that the crowd workers understand the task requirements and annotation standards, thereby elevating the quality and accuracy of the annotated data. Taking inspiration from these instructions for human annotators, we explore how GPT-3.5 can be transformed into a zero-shot and few-shot data annotator.
The zero-shot approach involves providing GPT-3.5 with task descriptions and category definitions, while the few-shot approach includes presenting demonstrated examples. These methods aim to replicate the precision of human annotation and are illustrated in Figure 1.
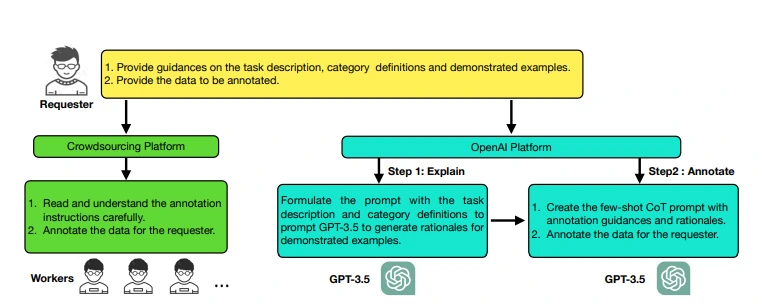
The process employed by crowdsourced workers for annotation is depicted on the left, while on the right, you can see AnnoGPT's approach. AnnoGPT closely follows the manual annotation procedure, but it diverges in one crucial aspect—it generates explanations for each example before they are annotated.
This unique feature ensures that every demonstrated example is accompanied by informative explanations, enhancing the overall usefulness and clarity of the annotation guidelines.
GPT-3.5 as a Zero-shot Data Annotator
In the zero-shot scenario, we furnish GPT-3.5 with task descriptions and category definitions. The task description conveys essential information about the task's purpose and definition, while the category definitions offer clear explanations for each category.
This empowers GPT-3.5 to serve as a zero-shot data annotator, where it can generate annotations without prior exposure to labeled examples. Examples of zero-shot prompts for tasks like user query and keyword relevance assessment, WiC, and BoolQ can be found in Tables 1, 2, and 3, respectively.

Table 1: Zero-shot prompt for the QK task

Table 2: Zero-shot exemplars prompt for the WiC task

Table 3: Zero-shot prompt for the BoolQ task
GPT-3.5 as a Few-shot Data Annotator
To further enhance GPT-3.5's capabilities, we adopt the few-shot approach, mirroring the way human annotators benefit from demonstrated examples for each category. We provide GPT-3.5 with demonstrated examples, effectively transforming it into a few-shot data annotator. Tables 4, 5, and 6 illustrate few-shot prompts for tasks such as user query and keyword relevance assessment, WiC, and BoolQ.
A recent discovery in the realm of data annotation is the effectiveness of adding human-written rationales, referred to as "chain-of-thought" (CoT), to demonstrated examples. This approach can elicit reasoning abilities in LLMs, leading to improved performance on reasoning tasks. Notably, GPT-3.5 exhibits strong reasoning abilities, automatically generating reasonable explanations for demonstrated examples.

Table 4: Few-shot exemplars prompt for the QK task

Table 5: Few-shot exemplars prompt for the WiC task


Table 6: Few-shot exemplars prompt for the BoolQ task
How to Generate Explanations with GPT-3.5
To harness GPT-3.5's reasoning prowess, we simulate how humans explain problems. We present GPT-3.5 with the task description, specific example, and the correct labels and ask it to explain why a particular example belongs to a specific category.
This process generates insightful explanations that help elucidate GPT-3.5's decision-making. To achieve this, we follow a specific procedure.
1. Task Description: We start by providing GPT-3.5 with a clear task description. This description outlines the nature of the task or problem we want the model to explain.
2. Specific Example: Next, we present GPT-3.5 with a specific example related to the given task. This example serves as a concrete instance that the model can refer to when generating explanations.
3. True Labels: Along with the example, we provide the true labels or answers associated with that example. These labels represent the correct or expected outcomes of the task.
4. Explanation Request: We then ask GPT-3.5 to explain why the corresponding answer for the given example matches the provided label. Essentially, we prompt the model to articulate the reasoning behind why a particular answer is the correct one for that example.
By employing this approach, we encourage GPT-3.5 to generate coherent and logical explanations for the tasks at hand. It helps us gain insights into how the model arrives at its conclusions and provides justification for its responses.
For instance, let's consider a task related to user query and keyword relevance assessment. We provide GPT-3.5 with the user query "google data studio sharepoint" and the keyword "sharepoint migration tool file share." We inform the model that the label for this assessment is "Bad." We then ask GPT-3.5 to explain why it considers the relevance between the user query and the keyword to be "Bad." By following this process, we leverage GPT-3.5's capabilities to generate meaningful explanations for a wide range of tasks, enabling better understanding and transparency in its decision-making processes. This approach can be adapted for different applications and domains, as demonstrated in Table 7 and Table 8 for tasks like WiC and BoolQ.

Table 7: Here's a demonstration of how to use an LLM to generate explanations for the WiC task, with "Input" as the prompt given to the LLM and "Output" as the resulting explanations.
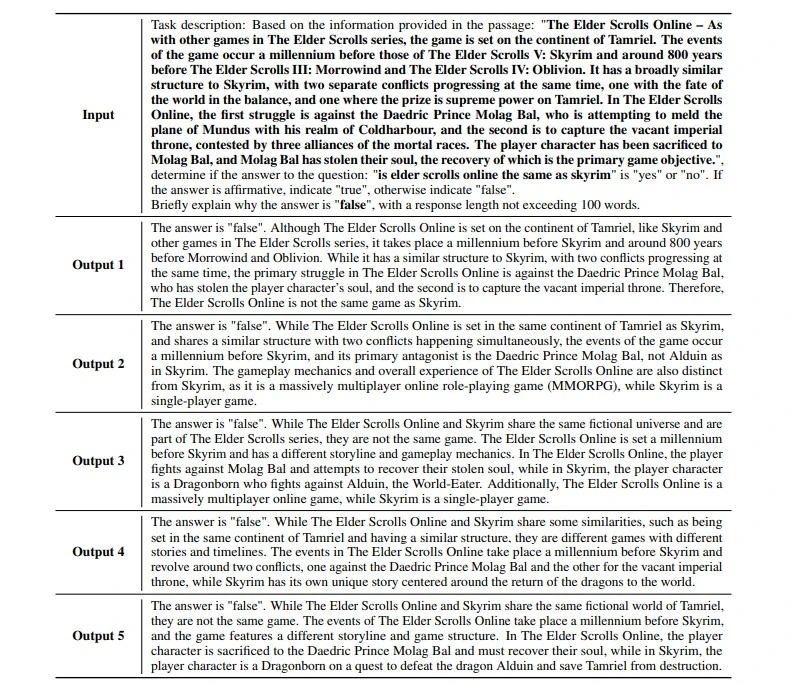
Table 8: Demonstration of LLM for generating BoolQ task explanations, with "Input" as the prompt and "Output" as the generated explanations.
How to Create Few-shot CoT Prompts
With explanations in hand, we construct few-shot CoT prompts. These prompts incorporate annotation guidance, category definitions, and the rationales generated by GPT-3.5. By following this approach, we ensure that each demonstrated example is not only annotated but also accompanied by meaningful explanations. This enriches the annotation guidelines, making them more informative and useful for downstream tasks.
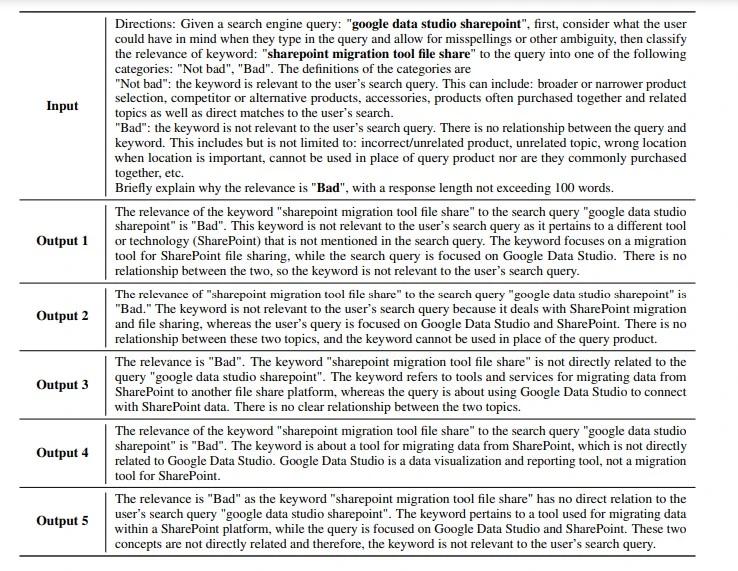
Table 9: Illustration of how to use a LLM to generate explanations for the user query and keyword relevance assessment task. "Input" and "Output" refer to the prompt provided to the LLM and the generated explanations, respectively.
Therefore, the utilization of GPT-3.5 as a data annotator, whether in a zero-shot or few-shot capacity, represents a groundbreaking advancement in data annotation methodologies. The integration of explanations into the annotation process promises to raise the quality and transparency of annotated data, unlocking new possibilities for improving the performance of NLP models across diverse applications. The following tables (Tables 10, 11, and 12) display the few-shot CoT prompts used for GPT-3.5 in the context of user query and keyword relevance assessment, WiC, and BoolQ tasks.

Table 10: Few-shot exemplars for full chain-of-thought prompt for the QK task. The bold text indicates the explanations generated with the prompt in Table 9.



Table 11: Few-shot exemplars for full chain-of-thought prompt for the WiC task. The bold text indicates the explanations generated with the prompt in Table 7


Table 12: Few-shot exemplars for the full chain-of-thought prompt for the BoolQ task. The bold text indicates the explanations generated with the prompt in Table 8
Exploring the Potential of Few-Shot CoT
AnnoLLM, leverages the power of few-shot CoT prompts to enhance models performance on various tasks. In this section, we will delve into the evaluation and results of AnnoLLM on three critical tasks: User Query and Keyword Relevance Assessment (QK), BoolQ (Boolean Questions), and Word-in-Context (WiC).
The Three Key Tasks
User Query and Keyword Relevance Assessment (QK): This task revolves around determining whether a user's query is relevant to given keywords.
BoolQ (Boolean Questions): BoolQ presents a question-answering challenge where each example consists of a passage and a yes/no question related to it. The questions are collected anonymously from Google search engine users and matched with relevant Wikipedia paragraphs containing the answers.
Word-in-Context (WiC): WiC focuses on disambiguating word senses through binary classification of sentence pairs. Participants must decide if a polysemous word has the same sense in both sentences.
All these tasks require binary classification, where the goal is to make a binary decision. The metric used for evaluation in all three tasks is accuracy.
Human Performances: Before diving into AnnoLLM's performance, it's crucial to establish a baseline by evaluating human performance on these tasks. In QK, human annotators on the UHRS3 platform were used, achieving a reliable label for each data instance. Human performance in BoolQ reached an impressive 89%, while WiC achieved 80%, highlighting the complexity of these tasks.
Experimental Results: Now, let's explore how AnnoLLM performs on these tasks
User Query and Keyword Relevance Assessment (QK): Surprisingly, GPT-3.5 performs worse under the few-shot setting compared to the zero-shot setting. However, with a 4-shot CoT prompt, GPT-3.5 outperforms both zero-shot and few-shot settings and even surpasses human annotators.
Word-in-Context (WiC): AnnoLLM, specifically GPT-3.5 with an 8-shot CoT, outperforms its few-shot counterpart significantly. However, there's still a gap between AnnoLLM and human annotators due to the task's inherent complexity.
Question Answering (BoolQ): AnnoLLM surpasses human annotators in BoolQ on both development and test sets. While it doesn't show significant improvement compared to the few-shot method, it demonstrates better stability across various prompts.
Analysis: Notably, using ground truth labels when generating explanations proves beneficial, as it provides guidance to the model, improving performance on the QK test set. Consistency and stability of generated explanations are crucial factors. AnnoLLM's consistency analysis indicates that the quality of explanations generated by the model is sufficiently consistent across different few-shot CoT prompts. Moreover, AnnoLLM with few-shot CoT prompts exhibits better stability compared to the few-shot method, particularly in tasks sensitive to templates.
What is the Future of Data Annotation
The introduction of 'explain-then-annotate' approach represent a significant leap forward in the field of data annotation. The reliance on costly and time-consuming crowdsourced annotators may soon become a thing of the past, as LLMs like GPT-3.5 demonstrate their ability to match or even surpass human performance in labeling data.
The implications of this shift are profound, as it opens doors to more extensive and cost-effective data annotation, ultimately advancing the capabilities of NLP models across various domains. The journey towards leveraging LLMs for data annotation is an exciting one, promising increased accessibility to labeled data and a brighter future for NLP.
Conclusion
AnnoLLM's inventive utilization of few-shot CoT prompts delivers substantial performance enhancements across a spectrum of language comprehension tasks. Notably, it not only surpasses human annotators in certain scenarios but also exhibits superior reliability and adaptability when faced with diverse prompts. This innovative approach ushers in exciting prospects for refining language models and amplifying their effectiveness across a broad array of applications.
Furthermore, a two-step strategy called 'explain-then-annotate' enhances the data annotation capabilities of Large Language Models (LLMs). This approach harnesses LLMs to generate few-shot chain-of-thought prompts, subsequently enabling the annotation of unlabeled data. Our empirical findings, based on three distinct datasets, underscore the feasibility of employing LLMs as a substitute for crowdsourced annotators. This underscores the potential to streamline the utilization of LLMs like GPT-3.5 in annotating data for diverse Natural Language Processing (NLP) tasks.
Frequently Asked Questions
- Can large language models be a crowdsourced annotator?
In recent times, models like GPT-3.5 have showcased impressive capabilities in both few-shot and zero-shot scenarios across a range of NLP tasks. Large language models (LLMs), like GPT-3.5, can effectively function as valuable crowdsourced annotators, provided they receive appropriate guidance and demonstrated examples.
2. Is data annotation a time consuming and expensive process?
The process of data annotation can be both time-consuming and costly, particularly when dealing with extensive datasets or tasks that demand expertise in specific domains. Recently, models from the GPT-3.5 series have showcased exceptional capabilities in handling various NLP tasks with impressive few-shot and zero-shot performance.
3. How can LLMs be better annotators?
In order to enhance the capabilities of LLMs as annotators, a two-step method known as 'explain-then-annotate’ is introduced. To clarify, we start by generating prompts for each demonstrated example. These prompts are then employed to instruct an LLM to furnish an explanation for the rationale behind selecting the precise ground truth answer or label for that specific example.
4. How does annotate work?
The process through which annotation operates is straightforward and efficient. It requires specifying both the target model for which the annotation is intended and the aggregate function that will be applied to the annotation. The "annotate" function serves as a container for encapsulating the aggregate method.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
