Automate Your Data Pipeline With Powerful Features
Build faster AI pipelines by combining automated data flows, instant SAM predictions, and full SDK support to get your annotations ready in record time.
Book a demo


Key Features
Prompt based labeling, model-assisted labeling and active learning based labeling automation that help to get super fast labeling.

Integrate Labellerr into your ML pipelines with our SDK. Programmatically sync data to automate workflows and scale production with minimal developer overhead.

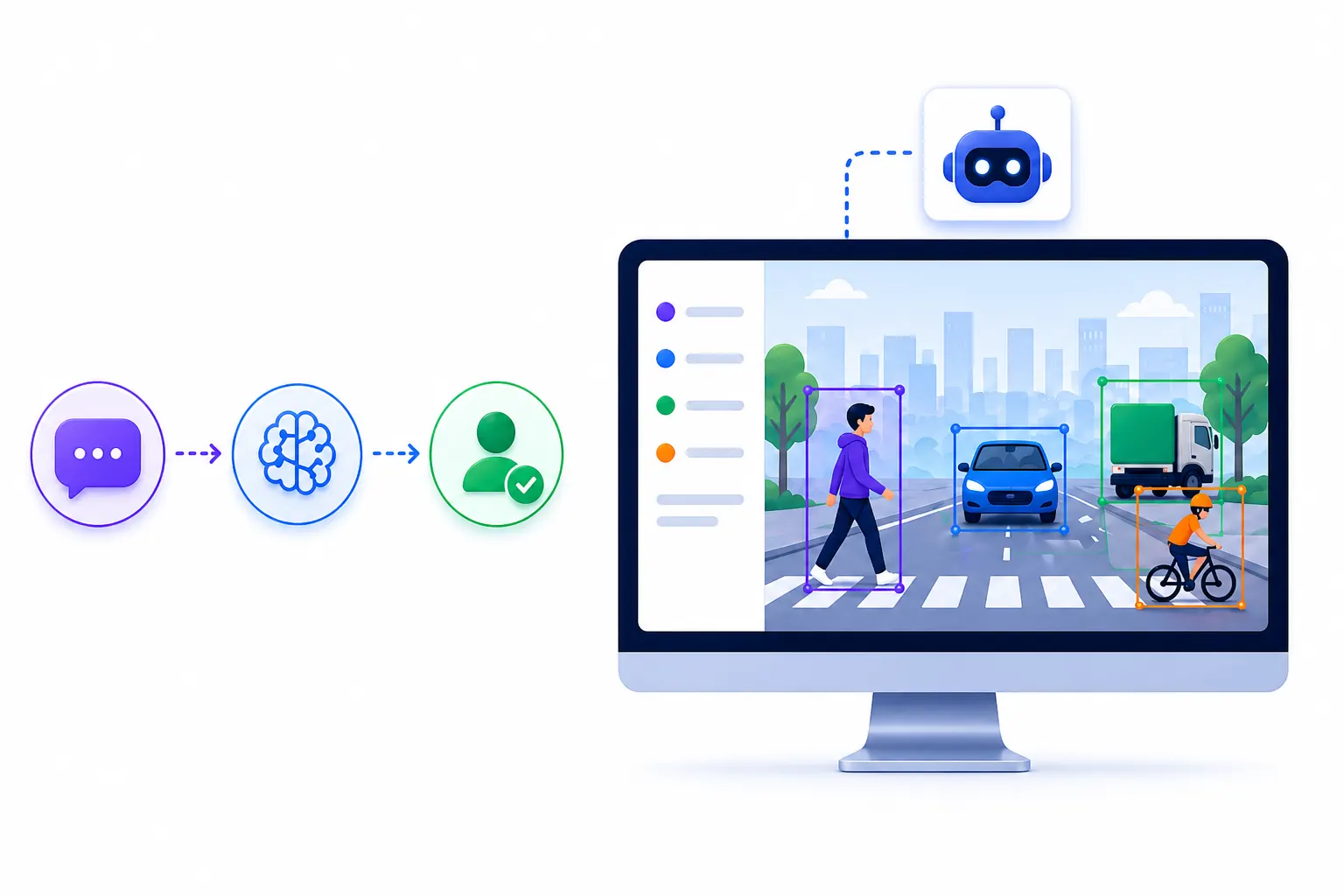
Labellerr natively supports Meta’s SAM, SAM 2, and SAM 3. Automate high-precision masking and drastically accelerate complex dataset annotation.
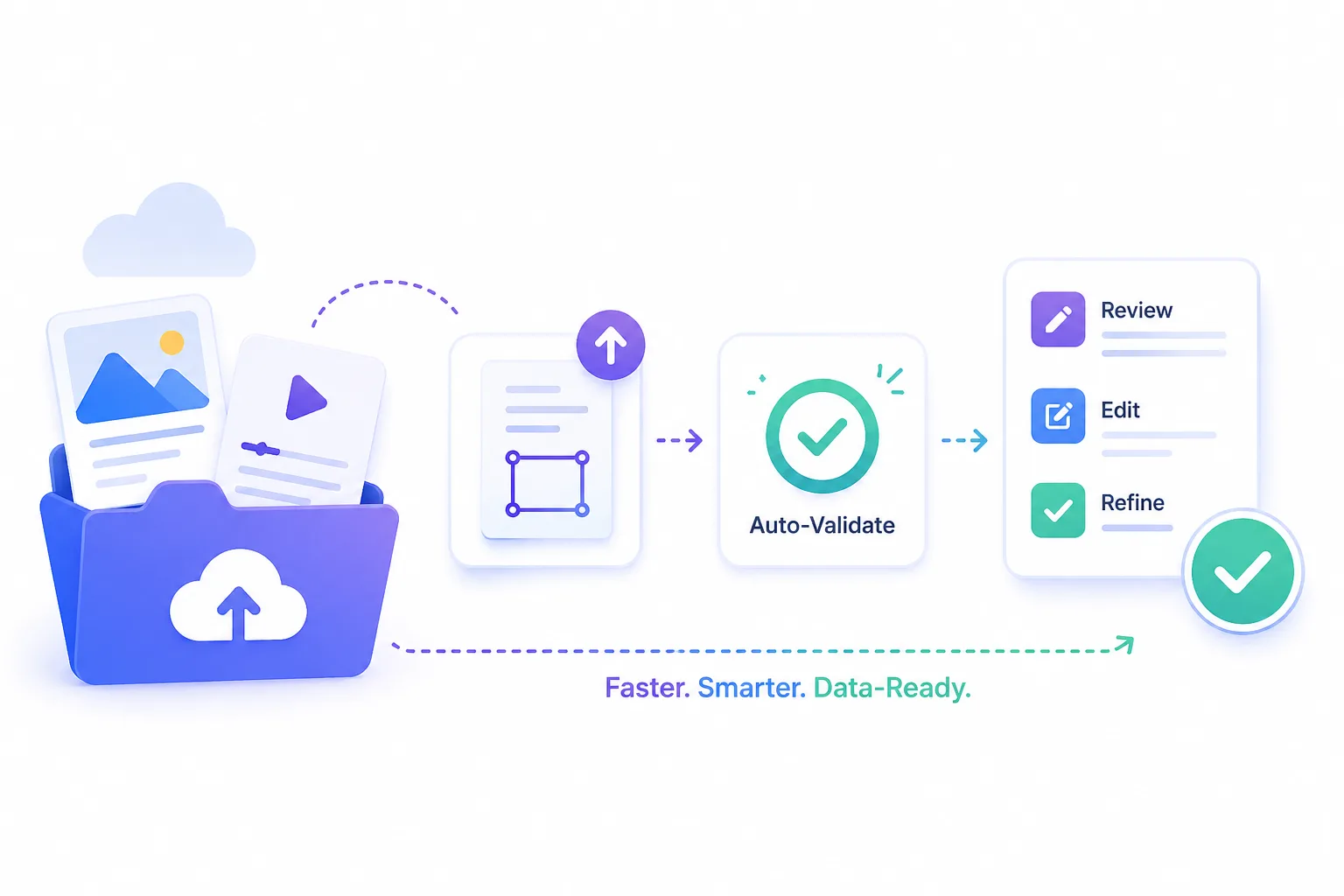
Upload your pre-annotations directly to Labellerr to review, edit, and refine. Skip the manual start and move straight to data validation.
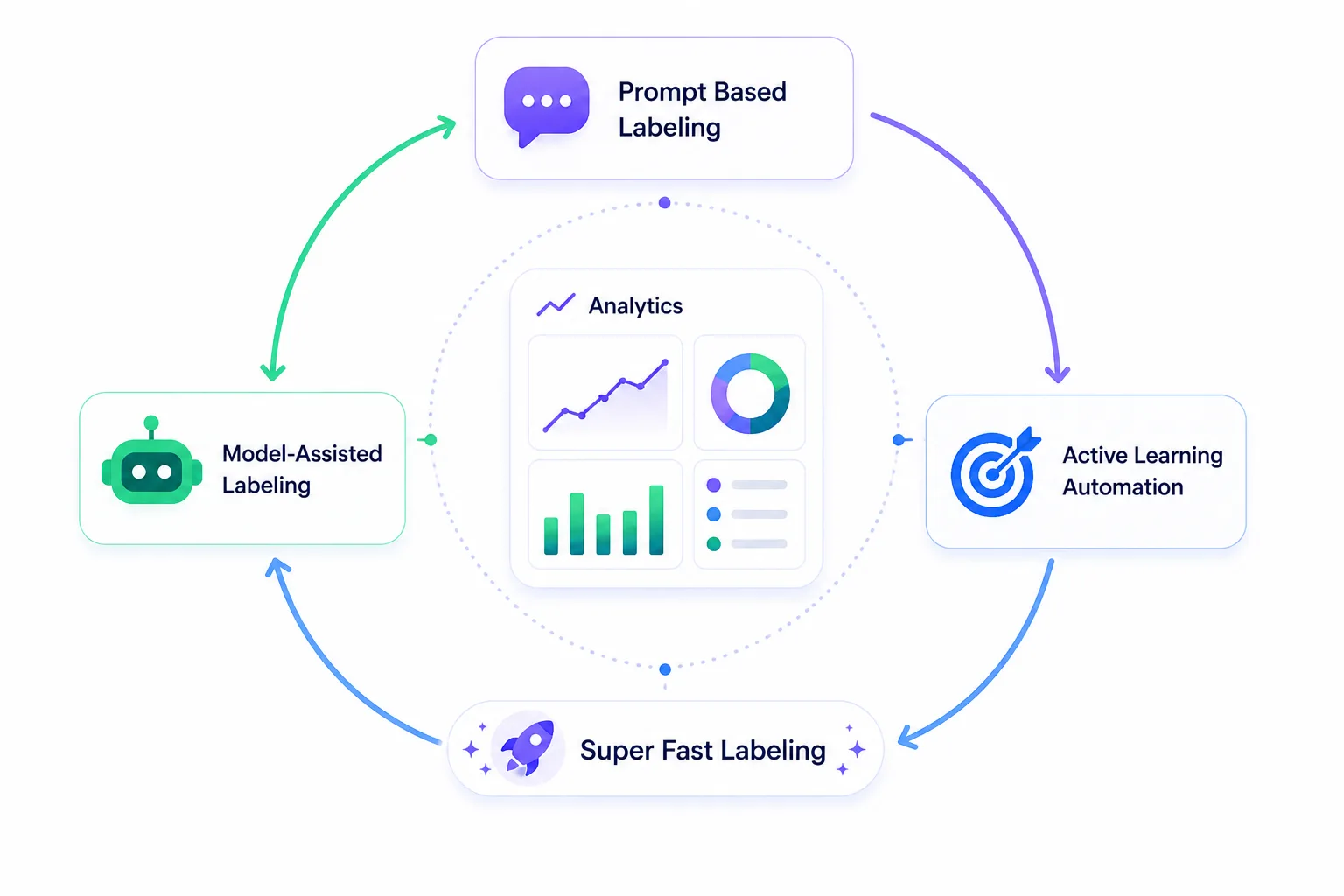
Prompt based labeling, model-assisted labeling and active learning based labeling automation that help to get super fast labeling.
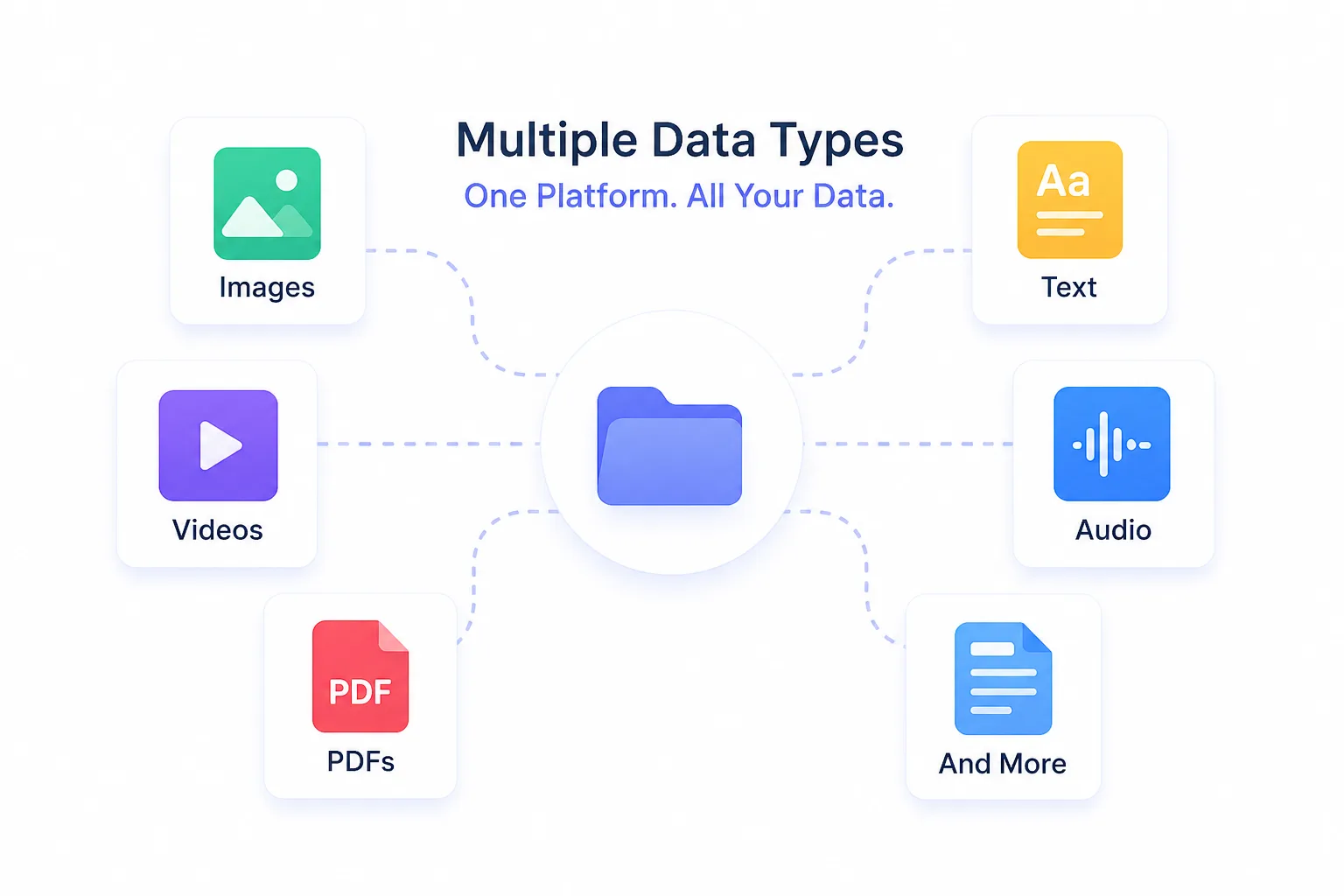
Connect images, videos, pdfs,text or audio to create your project. No need to switch multiple tool for your different project needs.
Power of Meta's SAM within Your Workflow
Labellerr natively integrates the entire Meta Segment Anything evolution from the zero-shot precision of SAM to the real-time video propagation of SAM 2 and the lightning-fast inference of SAM 3.
Meta's SAM is a foundational "zero-shot" model that segments any object without prior training. Using simple point or box prompts, it instantly generates high-fidelity masks, replacing manual pixel-tracing with automated, real-time boundary detection across any dataset.
SAM 2 upgrades the original by adding a "memory bank" for real-time video. Unlike SAM, which only handled static images, SAM 2 tracks and propagates masks across entire video sequences. This eliminates frame-by-frame effort by maintaining precise labels through movement and occlusions.
SAM 3 is the latest upgrade, optimized for extreme speed and efficiency. While SAM 2 mastered video tracking, SAM 3 introduces "iterative refinement" with a lighter architecture. It captures fine details like hair or mesh with higher precision and lower computational cost, making it the fastest version for real-time, high-accuracy production.
Easily apply semantic segmentation to your video data. Label every pixel in a frame, from key objects to background elements, and ensure your models capture every detail.




Free Data Annotation Workflow Plan
.webp)







Video Action Tagging
Tracking actions in a video second by second, showing exactly when each activity starts and ends.
It helps label:
- Small, precise tasks: Tracking exact moments tools are used.
- Continuous movements: Grouping actions on a timeline.
- Complex multi-step jobs: Labeling long tasks with multiple steps.
The AI can look at a live video and instantly name exactly what action a person is doing at that very second.
Keypoint Annotations
Labellerr natively integrates advanced MediaPipe models, combining automated coordinate tracking with custom keypoint attributes to deliver ML-ready datasets for robotics and spatial AI.
Hand Keypoint Annotation
- Track movements from wearable POV cameras
- Convert video pixels into steady coordinates
- Tag custom attributes to tracked keypoints
- Train egocentric models
- Supporting smart vision automation datasets
- Building fine-motor robot finger control
Pose Keypoint Annotation
- Track full-body skeletal joint movements.
- Map complex posture variations and gestures
- Tag attributes to body joint keypoints.
- Distinguishing body parts for spatial systems
- Developing sports analytics and tracking software.
- Building training datasets for industrial automation
Face Mesh & Landmark Annotation
- Track distinct facial mesh landmarks.
- Map micromovements around eyes and lips
- Tag custom attributes to facial keypoints
- Verifying identity with secure liveness models
- Real-time emotional and expression variations
- Creating animation assets for virtual avatars
Easily apply semantic segmentation to your video data. Label every pixel in a frame, from key objects to background elements, and ensure your models capture every detail.
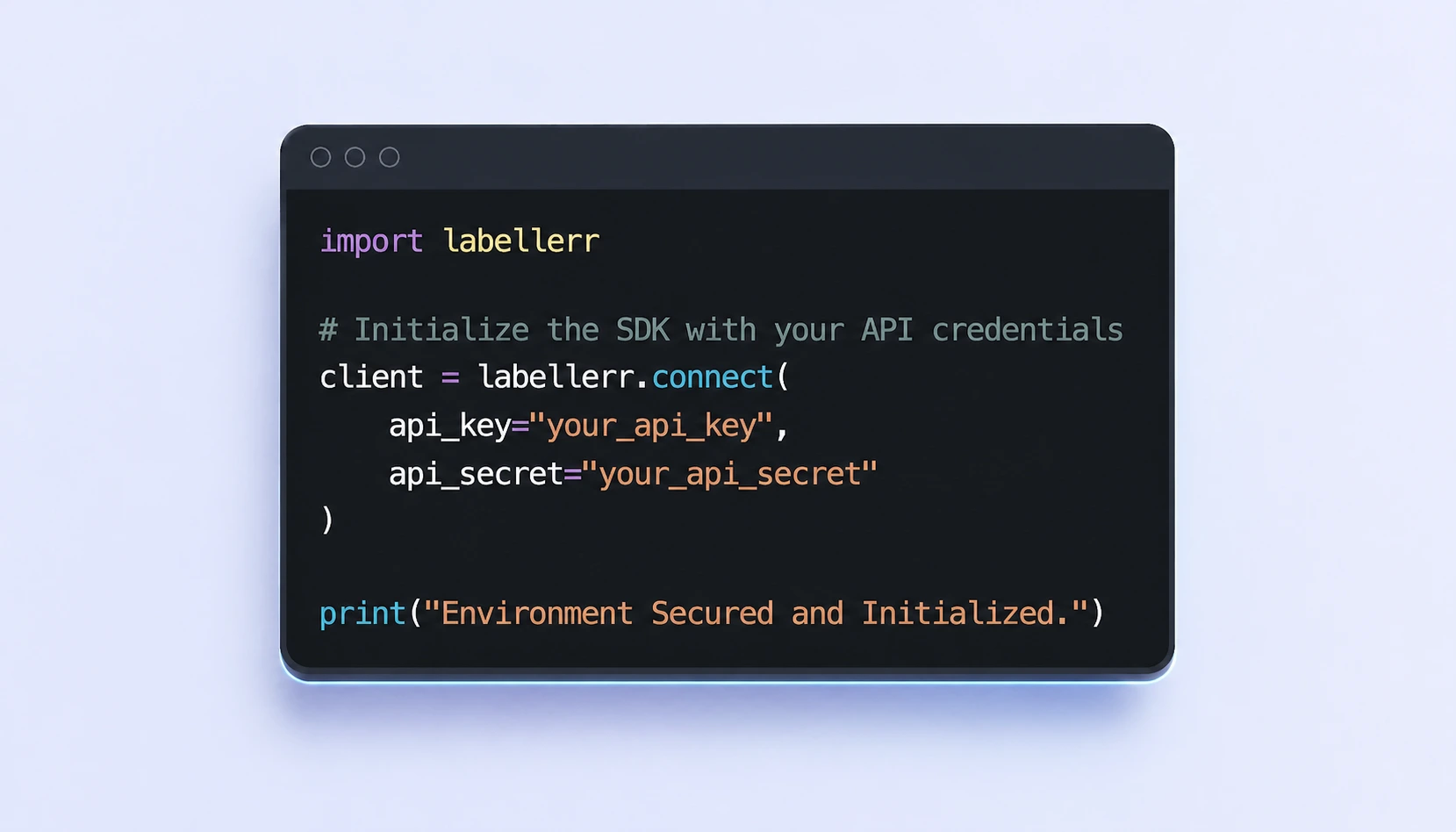
Install and Authenticate in Seconds
Get started by installing the Labellerr Python library. Securely connect your local environment or pipeline using your unique API Key and Secret to begin programmatically managing your datasets.
Project Creation via SDK
Launch and configure your labeling workflows with a single script. Our interface allows you to programmatically define project types and data sources, ensuring a repeatable, automated pipeline from the very first command.


Upload Pre-Annotations in your Project
Leverage your previous work by uploading pre-annotations directly through the SDK. Pair existing labels with raw cloud or local assets in a single command, eliminating manual rework and accelerating your pipeline.
Automate with Model-Assisted Labeling
Move beyond the UI. Call your custom models or leverage integrated foundation models like SAM 3 directly through the SDK to generate pre-annotations, verify labels, and manage task assignments at scale.

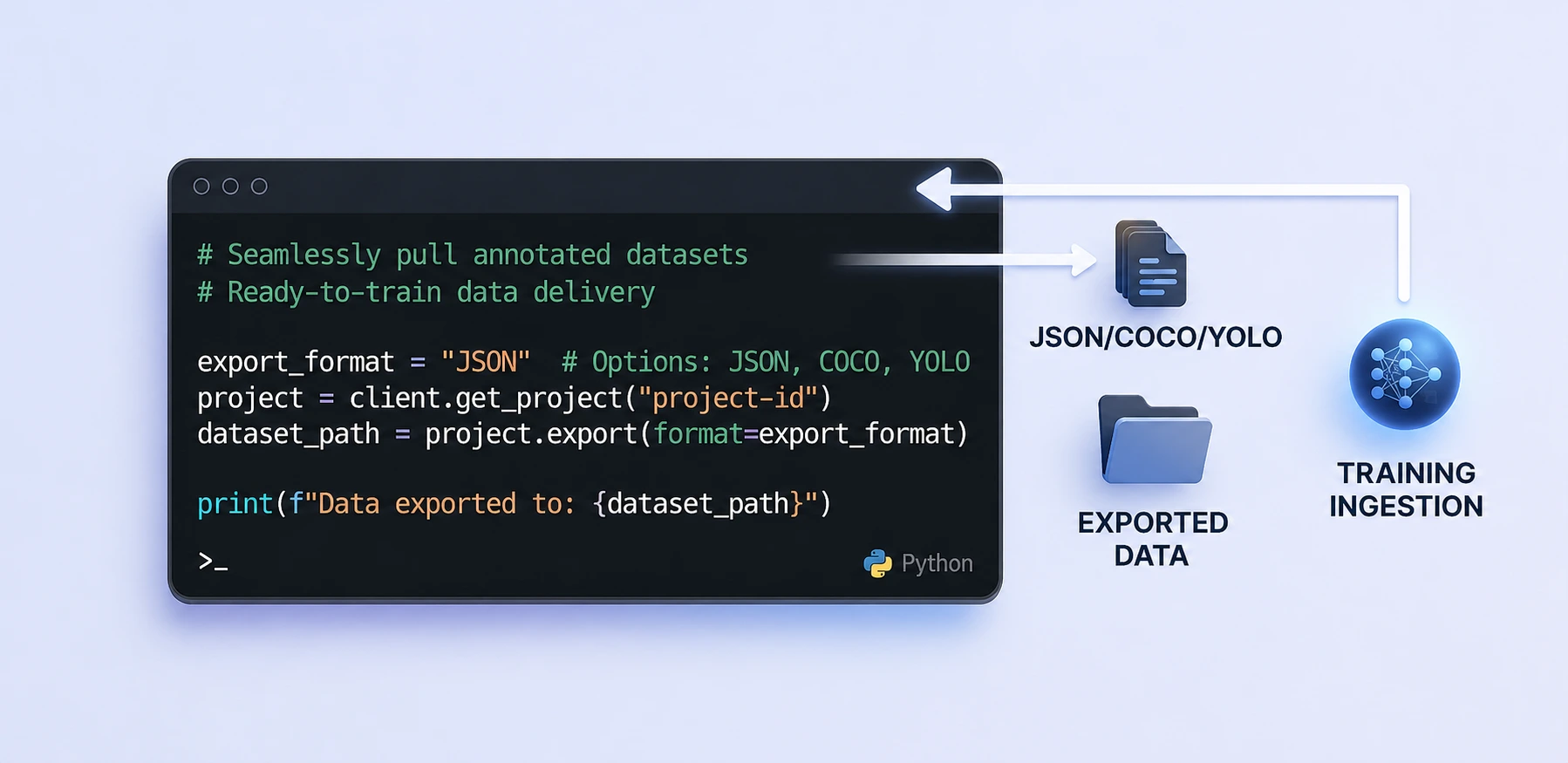
Export Output directly in your Pipeline
Seamlessly pull annotated datasets into your training environment. Export in standardized formats like JSON, COCO, or YOLO with one line of code, ensuring your models are always fueled by the latest ground-truth data.