

RoboSubtaskNet Turns Human Videos into Robot Skills
RoboSubtaskNet enables robots to learn tasks directly from human demonstrations by converting video observations into executable action sequences. With a 91.25% real-world success rate, it advances autonomous robotic learning for healthcare and industrial applications.


Imagine a nurse demonstrates how to hand a medicine bottle to a patient. A robot watches. Then it does the same thing, not by following a hard-coded script, but by understanding the sequence of micro-actions involved: reach, pick, move, give, retract. No teleoperation, No manual programming, Just observation and execution.
That is precisely what RoboSubtaskNet does. Published on arXiv in February 2026 by Sharma et al. from IIT Kanpur, this framework addresses one of the hardest open problems in robotics: how do you take an untrimmed human video and convert it into a reliable, robot-executable action sequence in real time?
This is not a demo in a controlled lab. It was validated on a real 7-DoF Kinova Gen3 manipulator, achieving a 91.25% overall task success rate across 80 physical trials.
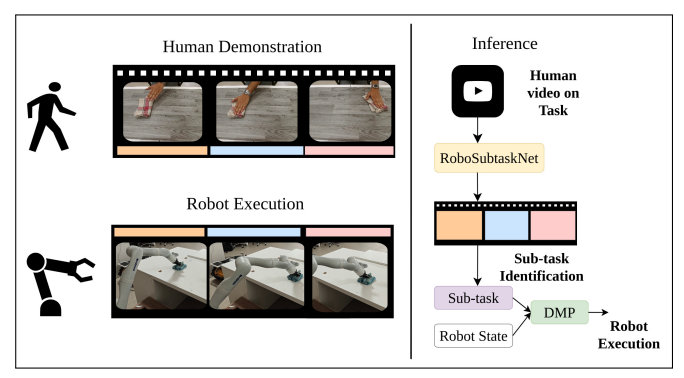
RoboSubtaskNet pipeline diagram showing Human Demonstration → RoboSubtaskNet → Sub-task Identification → DMP → Robot Execution
Paper: https://arxiv.org/pdf/2602.10015
The Core Problem: Generic Video Models Don't Work for Robots
Temporal action segmentation has made strong progress. Models like MS-TCN and MS-TCN++ can parse long videos into activity segments with good accuracy. But there is a critical mismatch.
Standard datasets like GTEA, Breakfast, and 50Salads annotate high-level activities, "make tea," "pour milk," "stir coffee." Robots don't execute "make tea." They execute reach → pick → pour → place → retract. These are primitive-level instructions, and no existing benchmark was designed to map directly to manipulator control.
RoboSubtaskNet solves this at two levels: it introduces a new dataset (RoboSubtask) aligned with robot primitives, and a new architecture optimized for the short-horizon transitions that manipulation demands.
The RoboSubtask Dataset

the four-task grid showing human demonstrations (top row) and robot execution sequences (bottom row) for pick & place, pick & pour, table cleaning, and pick & give
The authors created RoboSubtask with 4 manipulation tasks: pick & place, pick & pour, pick & give, and table cleaning. Each task was recorded with 200 videos per task using an RGB camera mounted on the Kinova Gen3 arm. Objects included bottles, cups, bowls, medicine syrup, mops, and boxes.
Every video is annotated frame-by-frame using a vocabulary of 7 primitives: Reach, Pick, Move, Pour, Give, Place, and Wipe. Each sub-task maps directly and deterministically to a manipulator primitive, no ambiguity, no semantic gap.
The dataset uses a 20% hold-out split per task, with horizontal flip and brightness adjustment as augmentations. This yields 1,920 training videos and 160 validation videos after augmentation. Data was collected across multiple users, objects, and environments to promote generalization.
The Architecture: Four Stages Working Together
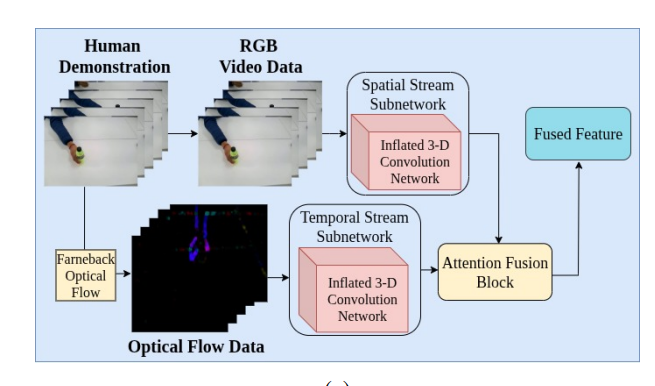
the I3D-based feature extractor diagram showing RGB and optical flow streams going into separate I3D networks
RoboSubtaskNet has four components that work in sequence. Each one solves a specific limitation of prior approaches.
Stage 1 : I3D Feature Extraction (RGB + Optical Flow)
The pipeline begins with a two-stream Inflated 3D ConvNet (I3D), pre-trained on the large-scale Kinetics dataset. One stream processes RGB frames. The other processes optical flow, computed frame-to-frame using the Farneback method.
For a video with F frames, both streams produce T ≈ ⌈F/8⌉ time-step embeddings, each of dimension D = 1024. The temporal stride of ~8 comes from I3D's internal strided convolutions and pooling. These embeddings are stored as feature matrices (T × 1024) for downstream use. Pre-training on Kinetics makes this efficient even with limited task-specific data.
Stage 2 : Attention-Based Modality Fusion
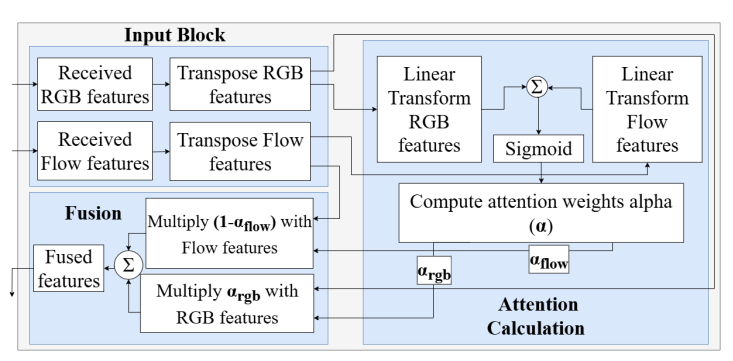
the attention fusion schematic showing the sigmoid-weighted combination of RGB and flow features
A naive approach would concatenate RGB and flow features into a 2048-dimensional vector. The authors argue this is suboptimal because different sub-tasks rely on different modalities at different times.
During reach and move, the hand is in motion, optical flow carries the meaningful signal. During pick and place, fine-grained visual appearance of the fingers and object surface matters more, RGB dominates.
To handle this, the framework uses a learnable attention coefficient α(t) ∈ [0,1]^D computed by a small fully-connected layer with sigmoid activation:
The fused feature is:
When α ≈ 1, the model leans on RGB. When α ≈ 0, it leans on flow. The output dimension stays at D = 1024, not 2048 reducing compute cost while improving task-specific discriminability.
Stage 3 : Fibonacci-Dilated MS-TCN
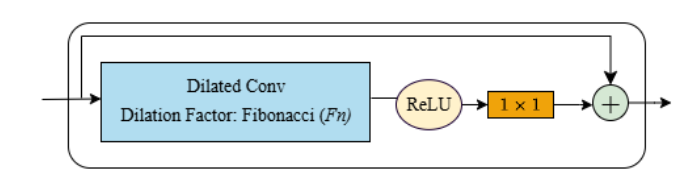
the dilated residual layer diagram showing the Fibonacci dilation factor (Fn) inside the conv block
Standard MS-TCN uses exponential dilation: 1, 2, 4, 8, 16 ... This skips over intermediate frames rapidly. That works for long cooking sequences where context spans minutes. For manipulation sub-tasks that last 1-3 seconds, this sparse sampling misses the subtle transitions between reach and pick, or place and retract.
RoboSubtaskNet replaces exponential dilation with a Fibonacci schedule: 1, 1, 2, 3, 5, 8, 13 ... The receptive field after L layers is:
This grows more gradually. It provides dense short-horizon coverage first, then expands. With 4 stages of 10 layers each and kernel size k = 3, the architecture progressively refines boundaries across stages, each stage takes the output probabilities of the previous stage as input, not raw features.
Stage 4 : Composite Loss Function
The model is trained with three loss terms combined:
Cross-entropy (L_CE) handles per-frame classification. Truncated MSE (L_T-MSE) penalizes abrupt changes in log-probabilities between adjacent frames, suppressing flicker and over-segmentation. The transition-aware term (L_Trans) penalizes label switches that are implausible, for example, jumping from "place" back to "reach" without a valid intermediate step.
The transition matrix M encodes which i→j label transitions are invalid. At each time step, the weight w_t = P_{t-1}^T · M · P_t measures how much probability mass is assigned to invalid transitions, and penalizes the total probability change proportionally.
Hyperparameters are set to λ = 0.15, γ = 0.25, τ = 4.0. Ablation studies confirm that adding L_Trans produces the largest single improvement: F1@50 jumps from 60.7 to 98.0 and Edit score from 64.2 to 98.5 on the RoboSubtask validation set.
Robot Execution: From Labels to Motion
Sub-task labels alone don't move a robot arm. RoboSubtaskNet connects predictions to execution through three components.
Object detection uses a YOLOv8-n model trained on custom objects. It outputs a 2D bounding box, whose center pixel (u, v) is paired with depth from an Intel RealSense D410 camera to compute 3D object position.
A proportional controller then drives the end-effector to the object using velocity commands proportional to position error, separately for x (depth axis) and y/z (lateral axes). The controller runs until positional error falls within tolerance.
Once aligned, the 3D coordinate is transformed into the robot base frame using ROS TF2. This target is passed as the goal g to a pre-trained Dynamic Movement Primitive (DMP) for the predicted sub-task. The DMP generates a smooth, human-like Cartesian trajectory from current end-effector pose to the goal, avoiding jerky motion without requiring manual waypoint programming.
Benchmark Results
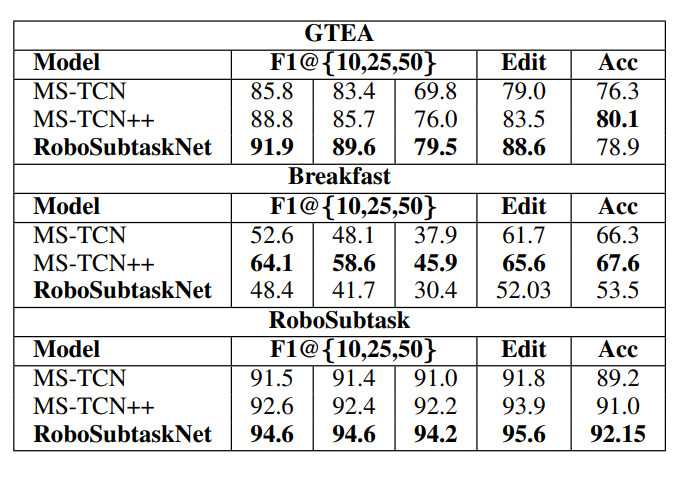
F1, Edit, and Accuracy scores across GTEA, Breakfast, and RoboSubtask for MS-TCN, MS-TCN++, and RoboSubtaskNet
On GTEA, RoboSubtaskNet achieves F1@50 = 79.5% and Edit = 88.6%, outperforming MS-TCN++ (F1@50 = 76.0%, Edit = 83.5%). Frame accuracy is comparable at 78.9% vs. 80.1%.
On the Breakfast dataset, a long-horizon benchmark with multi-minute cooking activities, the model trails MS-TCN++ (F1@50 = 30.4% vs. 45.9%). This is expected. Fibonacci dilation is designed for short-horizon transitions, not 20-minute activity sequences.
On RoboSubtask, RoboSubtaskNet leads on all metrics: F1@50 = 94.2%, Edit = 95.6%, Accuracy = 92.15%. These numbers confirm that the architecture choices, Fibonacci dilation, attention fusion, and transition-aware loss, are well-matched to manipulation-scale tasks.
In physical trials, the system achieved a 95% success rate on both pick & place and table cleaning, 90% on pick & pour, and 85% on pick & give. Across all 80 trials, the overall success rate was 91.25%.
Failure analysis across the 7 failures shows: 42.85% came from robot execution errors (object detection inaccuracy, grasp slip, motion singularities); 28.57% from incorrect sub-task sequence prediction; and 28.57% from system-level failures like software hangs.
What Makes This Work Stand Out
Three design decisions drive the results. First, the attention fusion module makes modality selection task-aware rather than fixed, the model learns that flow matters for reach and RGB matters for pick, rather than treating both as equally important at all times. Second, the Fibonacci dilation schedule fills the gap that exponential schedules leave: it covers short transitions densely without ignoring broader context.
Third, the transition-aware loss adds structural knowledge about valid sub-task progressions directly into the training objective, the model learns not just what each frame looks like, but what sequences are physically plausible.
Limitations and What Comes Next
RoboSubtaskNet relies on supervised frame-level annotations, which are expensive to create at scale. The label-to-skill mapping is deterministic and does not handle uncertainty at run time. The system uses monocular RGB and depth sensing, which can fail under occlusion or poor lighting. And the Breakfast results confirm that short-horizon design trades off against long-horizon generalization.
The authors identify three directions for future work: self-supervised annotation strategies to reduce labeling cost, tighter closed-loop coupling between perception and control with uncertainty-aware planning, and extension to longer-horizon task composition with built-in failure recovery.
Conclusion
RoboSubtaskNet is a carefully engineered system that connects fine-grained video understanding to physical robot execution. It is not built on scale or massive compute. It is built on precise design choices: the right feature fusion, the right dilation schedule, and the right loss structure for manipulation tasks.
The 91.25% physical success rate on a real manipulator, not a simulator, shows that this approach is deployable today. As robots move deeper into healthcare and industrial settings, frameworks that can learn directly from watching humans will be essential. RoboSubtaskNet is a strong step in that direction.
FAQs
Q1. What is RoboSubtaskNet and why is it important?
RoboSubtaskNet is a robotics framework that converts untrimmed human demonstration videos into robot-executable action sequences. It bridges the gap between human observation and autonomous robot execution without manual programming.
Q2. How does RoboSubtaskNet improve robot task understanding?
It uses attention-based feature fusion, Fibonacci-dilated temporal convolution networks, and a transition-aware loss function to accurately identify manipulation subtasks such as reach, pick, move, pour, and place.
Q3. What results did RoboSubtaskNet achieve in real-world testing?
The system achieved a 91.25% overall success rate across 80 physical trials on a Kinova Gen3 robotic arm, demonstrating reliable real-world task execution from human demonstrations.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
