

Claude Fable 5 vs Mythos 5: Review and Benchmark Analysis
Claude Fable 5 and Mythos 5 introduce Anthropic's new Mythos-class AI tier, combining breakthrough coding, reasoning, vision, and scientific capabilities with advanced safety controls designed for frontier-level AI deployment.


On June 9, 2026, Anthropic released two new models: Claude Fable 5 and Claude Mythos 5. Both share the same underlying architecture. Both sit above the Opus class, a new tier Anthropic calls "Mythos-class." And both represent the most capable AI models Anthropic has ever trained.
But they are not the same product. Fable 5 is for everyone. Mythos 5 is for a trusted few.
This distinction matters. Because for the first time, Anthropic chose to release a frontier model while openly acknowledging it is too powerful to ship without safety classifiers actively redirecting some of its responses. That is a significant admission , and an important design choice.
What Is the Mythos Class?
Anthropic introduced the Mythos class in April 2026 with Claude Mythos Preview, released through Project Glasswing to a limited set of cyberdefense and infrastructure organizations in collaboration with the U.S. government.
Fable 5 and Mythos 5 are the second generation of this class. Mythos-class models sit above Opus in both capability and risk profile. The naming is deliberate: fable comes from the Latin fabula, meaning "that which is told", akin to mythos in Greek. What separates Fable from Mythos is not the model itself, but the safeguards applied on top of it.
When safeguards trigger on Fable 5, the response is automatically handled by Claude Opus 4.8 instead. Users are told when this happens. In over 95% of sessions, no fallback occurs at all.
Architecture and Safety Classifier Design
Both models share one trained base. The architecture is not split, only the deployment configuration differs.
Fable 5 runs with three layers of safety classifiers on top of the base model:
1. Cybersecurity classifiers. Mythos-class models excel at exploit development, agentic hacking, lateral movement, reconnaissance, and defense evasion. The cybersecurity classifiers are designed to catch both narrow exploitation tasks and broad offensive cyber queries. Internal evaluations show the classifiers block Fable 5 from making any meaningful progress on cyber attack tasks. An external bug bounty program produced zero universal jailbreaks across more than 1,000 hours of testing.
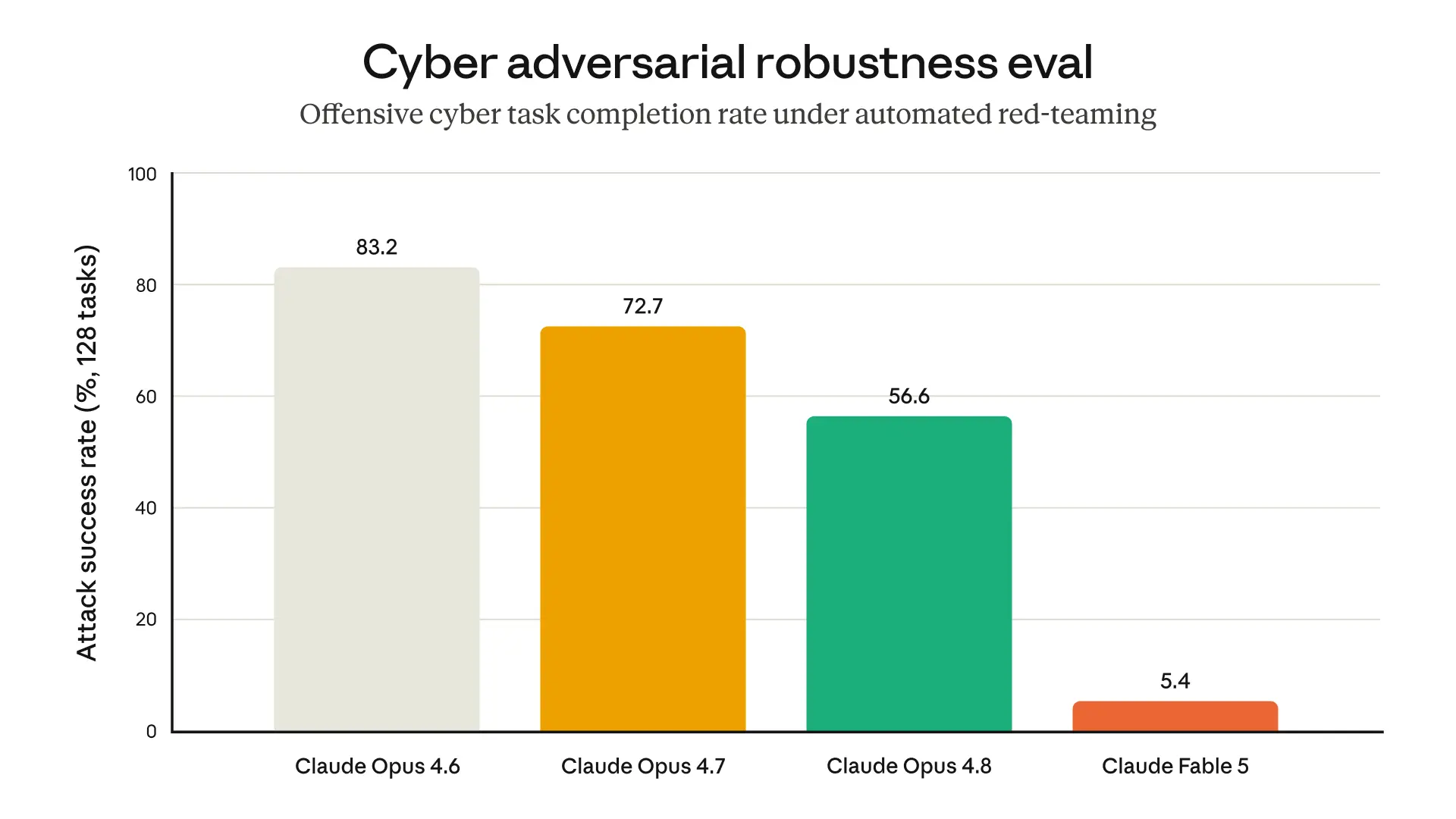
automated red-teamer results across 400 turns comparing Fable 5, Opus 4.8, and earlier models
2. Biology and chemistry classifiers. This is the most complex classifier layer. Mythos 5 outperforms dedicated protein language models at predicting AAV (adeno-associated virus) capsid packaging, a task directly relevant to gene therapy. That same capability, in the wrong hands, applies to dangerous viral design. For now, Fable 5 falls back to Opus 4.8 on most biology and chemistry queries. A trusted access program for biomedical researchers is planned in the coming weeks.
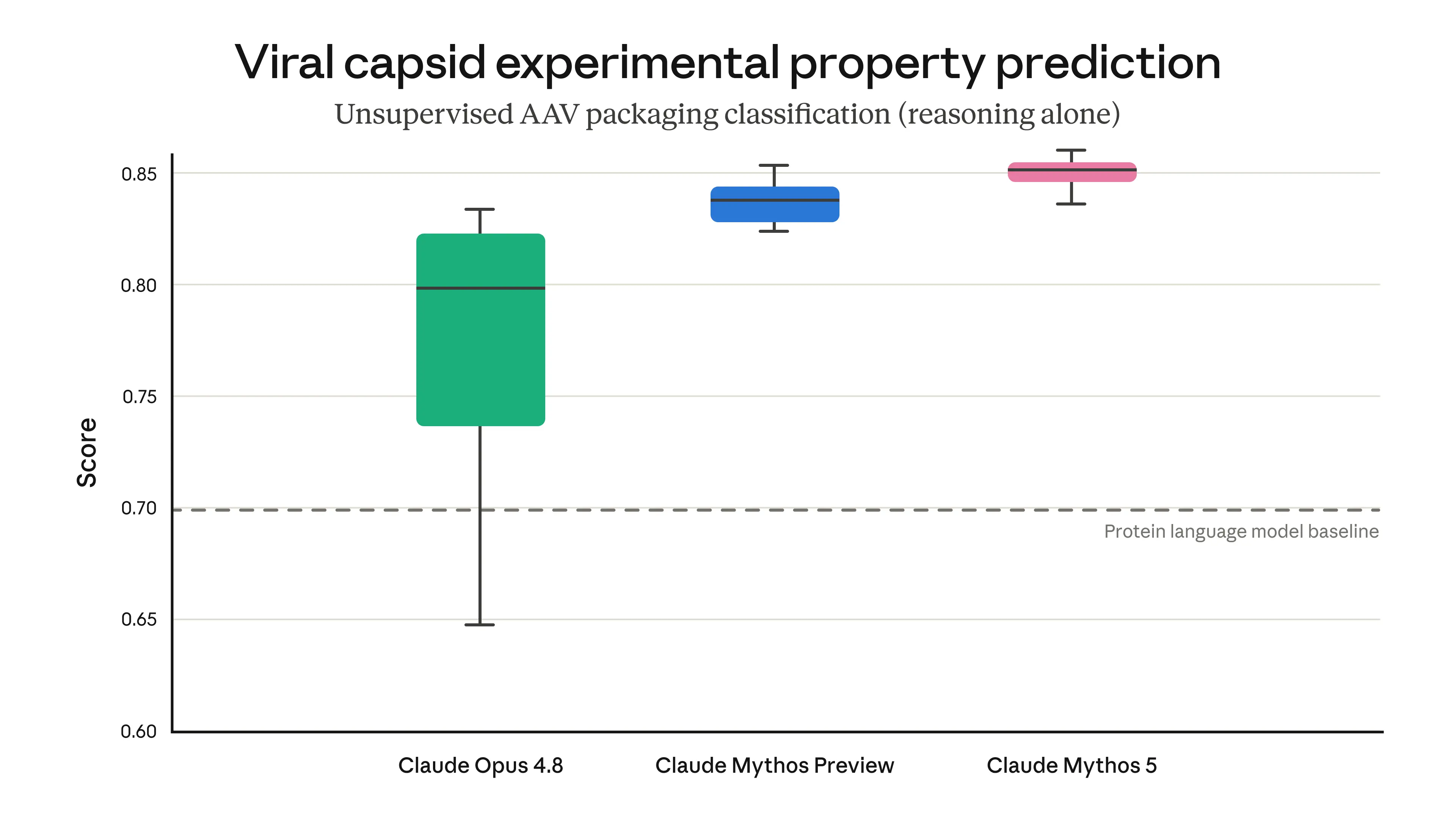
comparing Mythos 5 against protein language models on viral shell assembly
3. Distillation classifiers. Anthropic has previously documented large-scale attempts to extract Claude's capabilities for training competing models. Fable 5's classifiers detect and block these distillation attempts, falling back to Opus 4.8 when flagged.
Mythos 5 has the cyber classifiers lifted for Glasswing partners. Soon, a biology trusted access program will lift the biology classifiers for select research organizations, while keeping the cyber classifiers active.
Benchmark Performance at a Glance
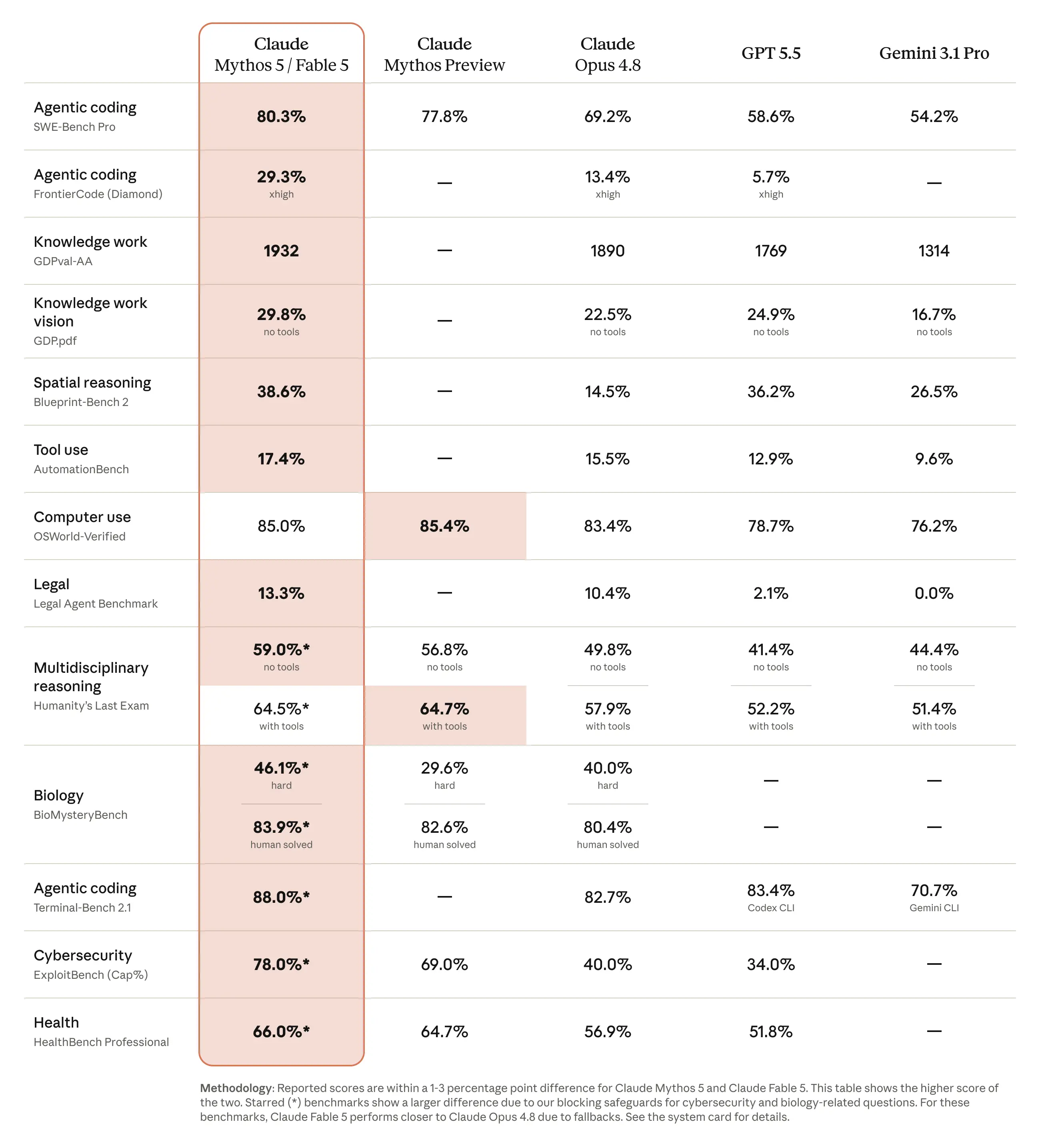
benchmark comparison table
The numbers from Anthropic's official benchmark table make the lead concrete.
Agentic Coding: On SWE-Bench Pro, Fable 5 / Mythos 5 scores 80.3%, versus 69.2% for Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. On FrontierCode (Diamond) at xhigh effort, it scores 29.3% against Opus 4.8's 13.4% and GPT-5.5's 5.7%. On Terminal-Bench 2.1, it hits 88.0% versus Opus 4.8's 82.7%.
Knowledge Work: On GDPval-AA, Fable 5 scores 1932 versus 1890 for Opus 4.8, 1769 for GPT-5.5, and 1314 for Gemini 3.1 Pro. On GDP.pdf (vision), it scores 29.8% with no tools, ahead of GPT-5.5 at 24.9% and Gemini at 16.7%.
Reasoning: On Humanity's Last Exam without tools, it scores 59.0% versus 49.8% for Opus 4.8 and 41.4% for GPT-5.5. With tools, it scores 64.5%, just below Mythos Preview's 64.7%.
Vision and Spatial: Blueprint-Bench 2 shows 38.6% versus 14.5% for Opus 4.8 and 36.2% for GPT-5.5, a clear lead on spatial reasoning. On OSWorld-Verified (computer use), it scores 85.0%, with Mythos Preview slightly ahead at 85.4%.
Tool Use and Legal: AutomationBench shows 17.4% versus 15.5% for Opus 4.8 and 12.9% for GPT-5.5. On Legal Agent Benchmark, it scores 13.3% versus 10.4% for Opus 4.8 and just 2.1% for GPT-5.5.
Biology: On BioMysteryBench (hard), it scores 46.1% versus 40.0% for Opus 4.8 and 29.6% for Mythos Preview. On the human-solved tier, it reaches 83.9%.
Cybersecurity: ExploitBench shows 78.0% for Mythos 5 versus 69.0% for Mythos Preview and 40.0% for Opus 4.8. Note: Fable 5 scores closer to Opus 4.8 here due to its active cybersecurity classifier fallback.
Health: HealthBench Professional scores 66.0% versus 64.7% for Mythos Preview and 56.9% for Opus 4.8.
Software Engineering Performance
Fable 5's performance on long-horizon coding tasks is the most documented area of its capability advantage.
Stripe reported that during early testing, Fable 5 compressed months of engineering work into days. In a 50-million-line Ruby codebase, it performed a full codebase-wide migration in a single day, a task that would have taken an entire team over two months to complete by hand.
On Cognition's FrontierCode benchmark, which tests whether models can pass difficult coding tasks while meeting production-quality standards, Fable 5 scores highest among all frontier models, even at medium effort levels.
Cursor's CEO reported that Fable 5 is state-of-the-art on CursorBench and opens long-horizon problems that were previously out of reach. GitHub's Chief Product Officer noted exceptional autonomy and reliability on complex, multi-step coding tasks.
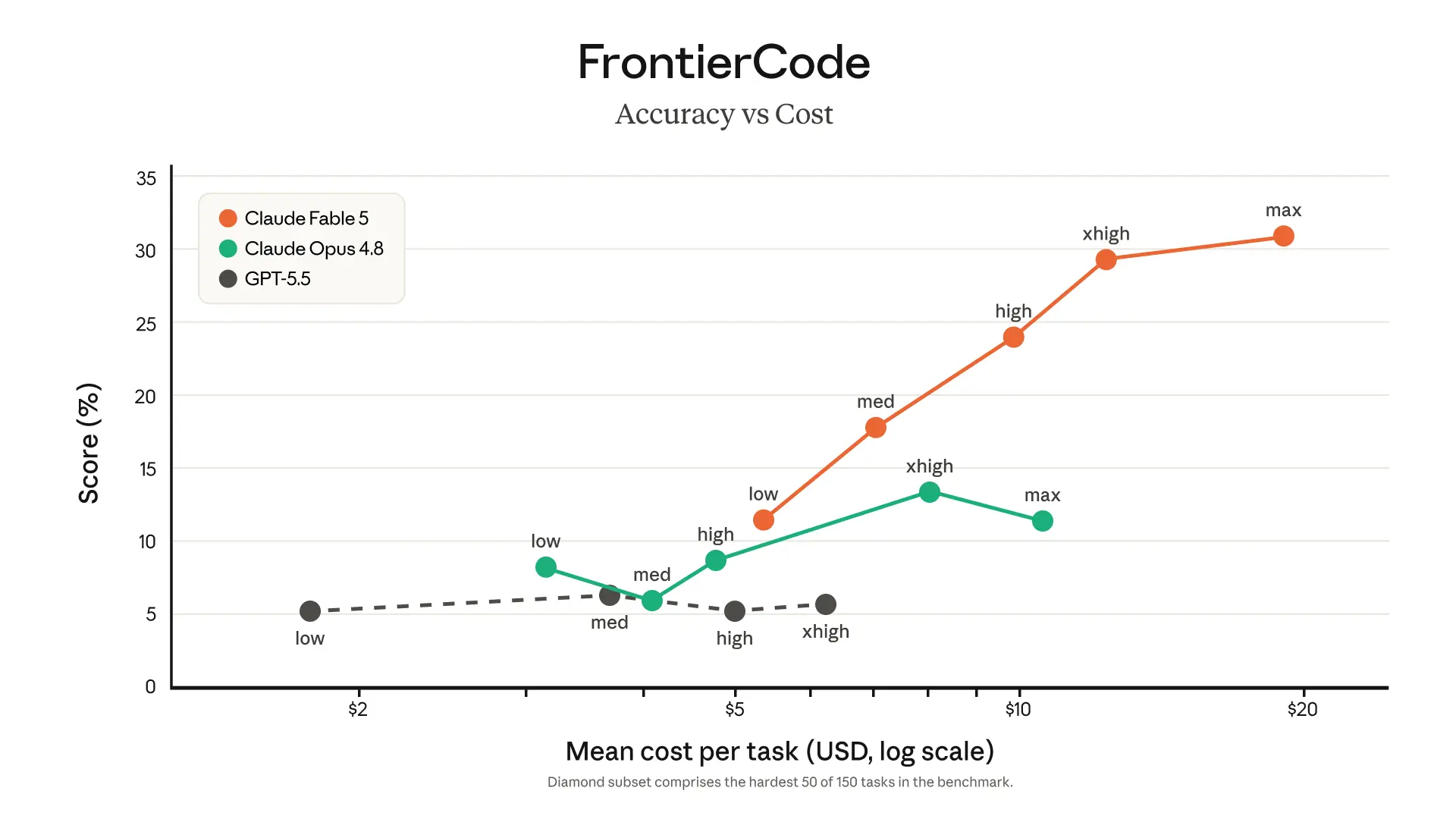
FrontierCode benchmark
Knowledge Work and Finance
On Hebbia's Finance Benchmark for senior-level reasoning, Fable 5 scores highest among all models tested. IMC, a trading firm, reported that Fable 5 aced their trading-analysis evaluations across factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis.
Fable 5 was also the first model to break 90% on one company's core analytics benchmark of complex, long-running analytical tasks, a 10-point jump over Opus 4.8. A legal AI company tested it in blind review and found its legal redlines matched or beat their current model every single time.
Vision Capabilities
Fable 5 is now the top-performing model on vision tasks. It can extract precise data from dense scientific figures. It can rebuild a web application's source code from screenshots alone.
Earlier Claude models needed a helper harness with maps, navigation aids, and additional game-state data to make progress in Pokémon FireRed. Fable 5 completed the full game using only raw game screenshots, no harness, no auxiliary tools, vision only.
video source
Memory and Long-Context Reasoning
Fable 5 maintains focus across millions of tokens in long-running agentic tasks. It improves its own outputs using persistent file-based notes.
Anthropic tested this by having the model play Slay the Spire, the deck-building game. Access to persistent file-based memory improved Fable 5's performance three times more than it improved Opus 4.8. Fable 5 also reached the game's final act three times more often than Opus 4.8 under the same conditions.
video source
Life Sciences: Drug Design and Novel Hypotheses
This is where Mythos 5 separates itself most clearly from anything before it.
Using Mythos 5 with protein design and bioinformatics tools and no human assistance Anthropic's internal team accelerated aspects of the drug design process by around ten times. In a head-to-head evaluation, Mythos 5 matched or beat skilled human operators across all tasks a scientist would normally complete: choosing binding sites, selecting tools, running protein design pipelines, and recovering from failures.
Of 14 protein targets in the study, nine produced strong drug design candidates that are now under investigation.
Mythos 5-designed protein complexes across immune checkpoints, growth-factor signaling, neurodegeneration, and muscle disease targets
On novel hypothesis generation, Mythos 5 is Anthropic's first model to consistently produce original, compelling scientific hypotheses. In blinded comparisons against Opus-class models, scientists preferred Mythos 5's molecular biology hypotheses roughly 80% of the time.
One hypothesis, a novel mechanism for an E. coli protein was independently corroborated by a separate lab's published study.
In genomics, Mythos 5 conducted more than a week of largely autonomous research. It assembled single-cell data for millions of cells across 138 animal species.
It then designed and trained a custom machine learning model to identify cells performing the same biological role across distantly related organisms. That model outperformed a recently published model from the journal Science, while being 100 times smaller.
Alignment Assessment
Anthropic ran an automated alignment assessment on Mythos 5. The overall level of misaligned behavior, including deception and cooperation with misuse, was low and comparable to Opus 4.8.
The model sometimes still takes reckless or destructive actions in service of a user's goal. Interpretability analyses show it is internally aware these actions are transgressive while it performs them. That gap between internal awareness and external behavior is an active area of investigation.
On prompt injection resistance, Mythos 5 achieved the lowest (best) score ever seen on Gray Swan's external benchmark for agentic tool use.
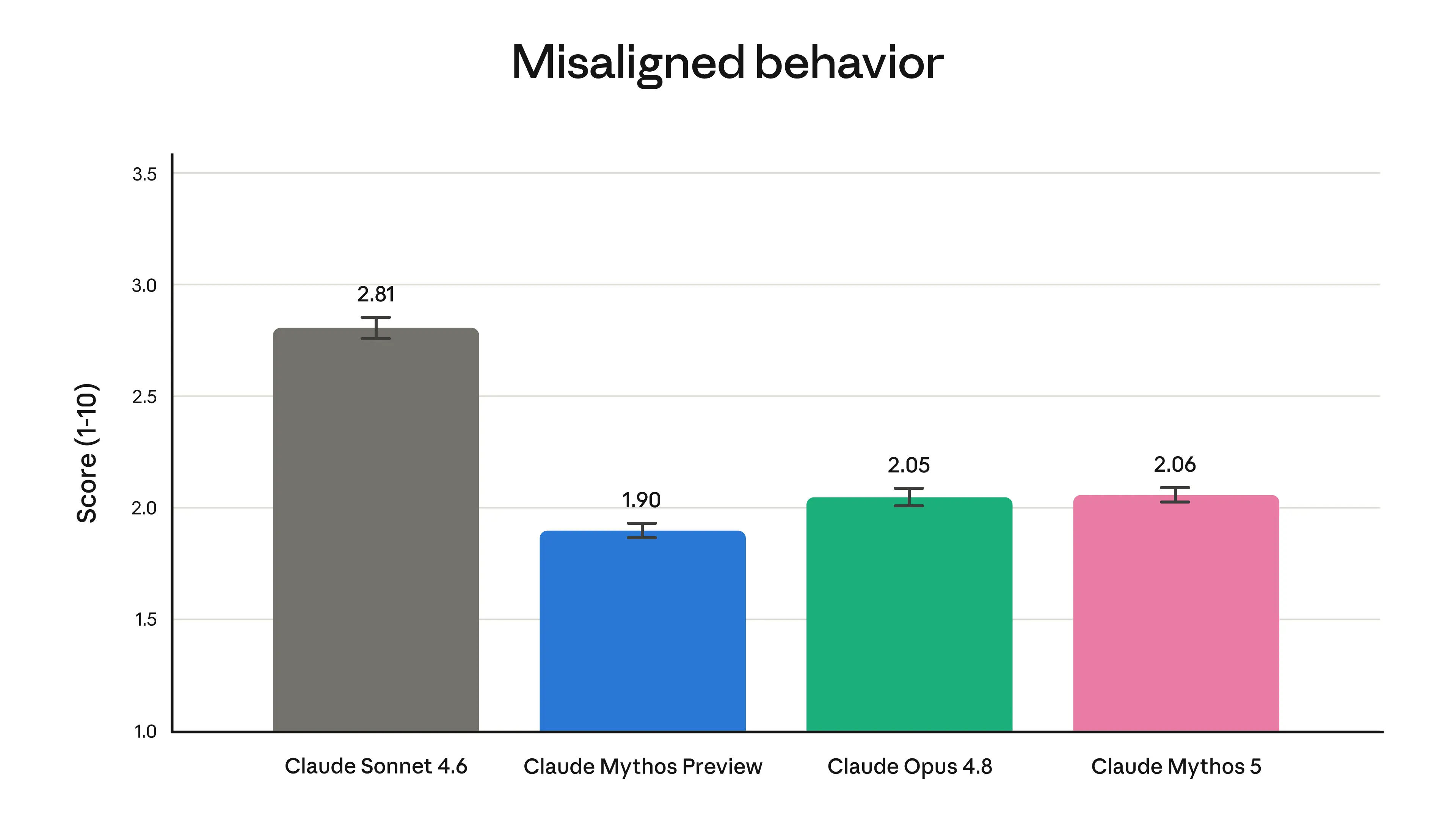
overall misaligned behavior rates across model generations
API Pricing and Access
Both Claude Fable 5 and Claude Mythos 5 are priced at:
- $10 per million input tokens
- $50 per million output tokens
This is less than half the price of Claude Mythos Preview.
Developers can access Fable 5 via the Claude API using the model string claude-fable-5. The API and consumption-based Enterprise plans have full access starting today.
For subscription plans (Pro, Max, Team, seat-based Enterprise), Anthropic is rolling out access in stages due to anticipated high demand:
- Through June 22, 2026: Fable 5 is included at no extra cost.
- June 23, 2026 onward: Usage will require usage credits until capacity expands enough to restore standard access.
Claude Mythos 5 remains restricted to Project Glasswing partners (with cyber safeguards lifted) and will soon be available to select biology researchers (with biology and chemistry safeguards lifted). A broader trusted access program is in development.
A new 30-day data retention policy applies to all Mythos-class model traffic. Anthropic will not use this data for model training, but will use it to detect novel jailbreaks and reduce false positive rates in the classifiers over time.
conclusion
Fable 5 is the first Mythos-class model available to the public. Getting there required building classifiers that are deliberately over-broad, they will occasionally catch benign requests. Anthropic is transparent about this tradeoff. The goal is to narrow false positives quickly while keeping the safeguards strong enough to matter.
Mythos 5, meanwhile, is already being used by cyberdefenders to secure critical infrastructure and by internal protein design teams to find drug candidates at ten times the previous speed.
The gap between what these models can do and what they are currently allowed to do for general users will close over time. But the architecture for doing so, tiered access, classifier-based fallback, trusted programs for high-risk domains, is now live.
FAQs
What is the difference between Claude Fable 5 and Claude Mythos 5?
Both models share the same underlying architecture, but Fable 5 includes safety classifiers that redirect certain high-risk requests to Opus 4.8. Mythos 5 is available only through trusted access programs with some safeguards selectively lifted.
Why does Claude Fable 5 use safety classifier fallbacks?
Safety classifiers help prevent misuse in areas such as cybersecurity, biology, chemistry, and model distillation. When triggered, requests are automatically handled by Opus 4.8 instead of Fable 5.
What makes Claude Fable 5 a significant advancement over Opus 4.8?
Fable 5 delivers major improvements in coding, reasoning, vision, scientific research, and long-context tasks, achieving state-of-the-art results across multiple frontier AI benchmarks.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
