computer vision Top Foundation Models Powering Modern Computer Vision 2026 An in-depth look at how foundation models like ViT, SAM, CLIP, Stable Diffusion, and DINO transformed computer vision from task-specific pipelines into general-purpose visual intelligence systems.
CLIP Tutorial To Leverage Open AI's CLIP Model For Fashion Industry Discover how fine-tuning CLIP model can revolutionize fashion image recognition. Learn to optimize OpenAI's CLIP with domain-specific data for the fashion industry.
CLIP's Performance On Food Dataset: Here Are The Findings The CLIP (Contrastive Language–Image Pre-training) model represents a groundbreaking convergence of natural language understanding and computer vision, allowing it to excel in various tasks involving images and text. Its foundation is rooted in zero-shot transfer learning, which empowers the model to make accurate predictions on entirely new classes or
Results Of CLIP's Zero-Shot Performance Over OCR Dataset CLIP demonstrates potential in zero-shot learning for OCR by classifying text sentiment images with 50% accuracy. Its ability to associate images with text enables it to adapt to unseen concepts, though precision (40%) reveals room for improvement through fine-tuning
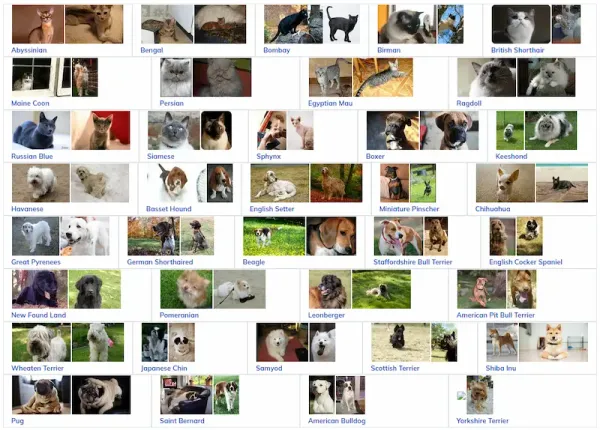
Zero-Shot Performance Of CLIP Over Animal Breed Dataset: Here're The Findings Table of Contents 1. Introduction 2. About Datasets 3. Hands-on With Code 4. Conclusion 5. Frequently Asked Questions (FAQ) Introduction The CLIP (Contrastive Language–Image Pre-training) model represents a groundbreaking convergence of natural language understanding and computer vision, allowing it to excel in various tasks involving images and text. Its
cvpr 23 CVPR 2023: Key Takeaways & Future Trends The atmosphere was charged with excitement at CVPR 2023 in Vancouver, the renowned conference for computer vision. Researchers and practitioners gathered to exchange ideas about the significant advancements in the field over the past year and discuss the future of computer vision and AI as a whole. The predominant subjects
computer vision Foundation Models for Image Search: Enhancing Efficiency and Accuracy Foundation models like CLIP and GLIP are transforming the way businesses use AI for visual search. These advanced systems leverage multimodal capabilities to enhance image search model accuracy by linking text and visuals, making searches faster, more precise, and highly adaptable.