

Foundation Models for Image Search: Enhancing Efficiency and Accuracy
Foundation models like CLIP and GLIP are transforming the way businesses use AI for visual search. These advanced systems leverage multimodal capabilities to enhance image search model accuracy by linking text and visuals, making searches faster, more precise, and highly adaptable.


Introduction
In the rapidly advancing field of artificial intelligence, foundation models like CLIP (Contrastive Language-Image Pre-Training) and GLIP (Grounded Language-Image Pre-Training) are redefining how we approach visual search.
By seamlessly integrating textual and visual understanding, these innovative systems deliver faster, more accurate, and highly adaptable solutions for image retrieval.
Traditional image search engines rely on sophisticated algorithms to match user queries with stored images.
These algorithms analyze explicit features such as descriptions, colors, patterns, shapes, and accompanying textual metadata from webpages.
However, developing such systems demands substantial engineering effort and time, and their adaptability to new or private photo collections is limited.
This is where foundation models excel. Like how ChatGPT and GPT-4 showcased extraordinary versatility in language tasks, multimodal models such as CLIP and GLIP push the boundaries of image search.
By integrating CLIP and GLIP into image search systems, businesses and developers can achieve unparalleled performance and scalability. These models not only enhance the relevance and accuracy of search results but also adapt seamlessly to diverse and evolving datasets.
In this article, you will explore the intricacies of CLIP and GLIP, their transformative use cases, and how they are reshaping the landscape of image search with AI-driven innovation.
Table of Contents
- Introduction
- CLIP (Contrastive Language-Image Pre-Training)
- GLIP (Grounded Language-Image Pre-Training)
- Potential Use Cases
- Conclusion
- Frequently Asked Questions (FAQ)
What are Foundation Models
Foundation models refer to pre-trained models that form the basis for various tasks in machine learning, including image understanding and retrieval.
In our context, i.e., for making two specific foundation models are mentioned: CLIP (Contrastive Language-Image Pre-Training) and GLIP (Grounded Language-Image Pre-Training).
By using language-image pre-training, they capture abstract concepts and intricate image details, enabling advanced comparisons far beyond simple feature matching.
These models utilize vast vocabularies and exhibit remarkable generalizability, making them ideal for tackling complex image retrieval challenges.
Understanding CLIP: A Game-Changer in Multimodal Learning
The CLIP (Contrastive Language-Image Pre-training) model has emerged as a groundbreaking development in computer vision, leveraging decades of research in zero-shot transfer, natural language supervision, and multimodal learning.
But what makes CLIP truly revolutionary?
Let’s dive into its origins, innovations, and how it’s reshaping the field.
The Journey of Zero-Shot Learning: From Concept to Reality
For over a decade, researchers in computer vision have explored zero-shot learning—the ability of models to generalize to object categories they’ve never encountered before. Early breakthroughs laid the groundwork for this ambitious goal.
In 2013, researchers at Stanford, including Richard Socher, showcased a proof-of-concept model trained on CIFAR-10. This model didn’t just predict known classes; it ventured into new territory, successfully identifying two previously unseen classes using a word vector embedding space.
Around the same time, the DeVISE approach scaled up this idea, demonstrating that an ImageNet model could generalize beyond its original 1,000-class dataset.
These pioneering efforts introduced the concept of natural language as a prediction space, opening doors for broader generalization and seamless transfer of knowledge across domains.
CLIP’s Breakthrough: Redefining Vision-Language Integration
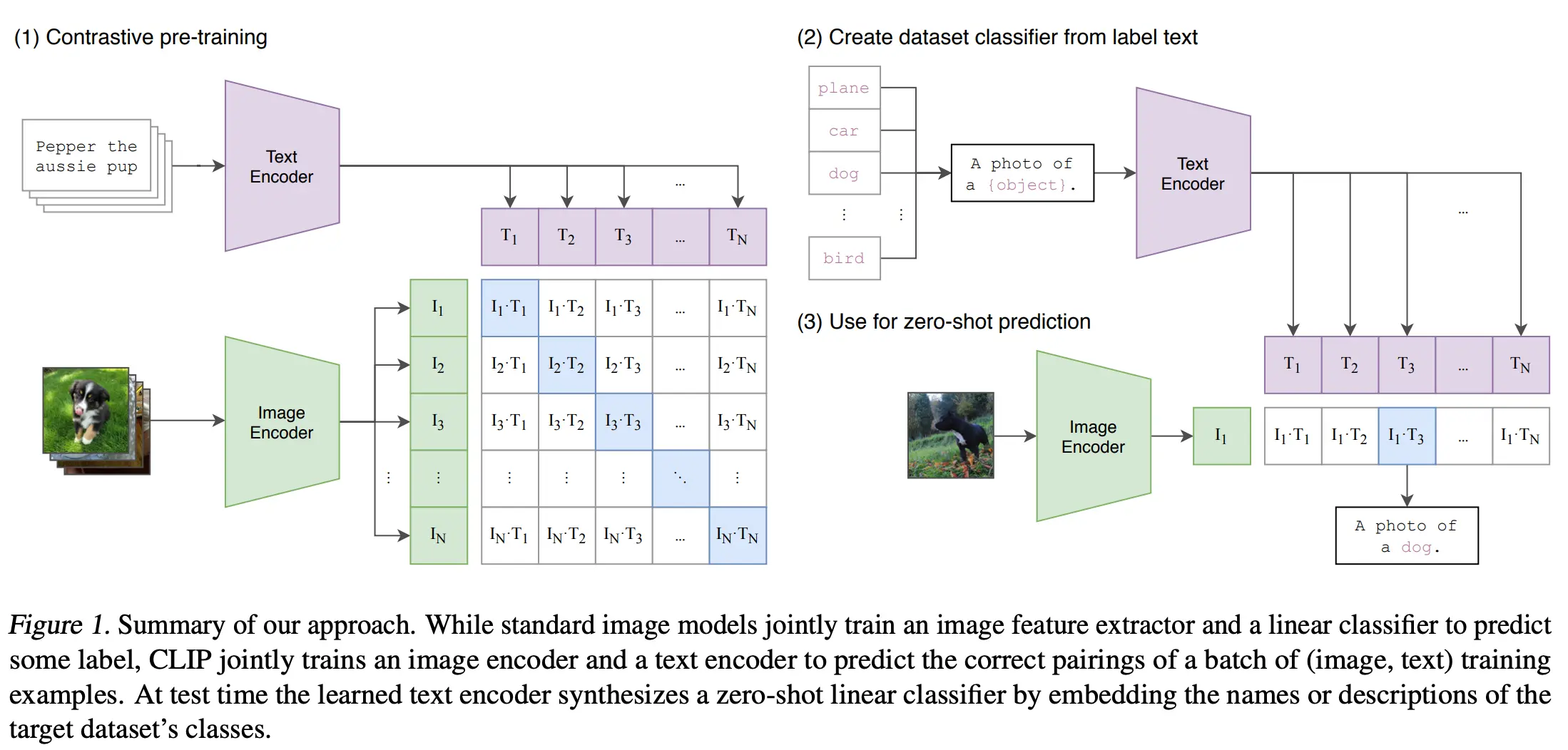
Figure: CLIP Foundational Model working
CLIP is part of a new wave of research focusing on learning visual representations through natural language supervision. What sets CLIP apart is its use of modern architectures, like the Transformer, to bridge the gap between textual and visual understanding.
This model builds on and surpasses previous methods, drawing inspiration from projects like:
- VirTex: Leveraging autoregressive language modeling.
- ICMLM: Utilizing masked language modeling.
- ConVIRT: Applying a similar contrastive objective as CLIP, but specifically for medical imaging.
By integrating these advancements, CLIP excels in linking textual descriptions with images, enabling nuanced and context-aware predictions.
Its unique approach harnesses the power of zero-shot transfer, natural language supervision, and multimodal learning to create a versatile model capable of understanding and relating words and visuals seamlessly.
Why CLIP Matters
CLIP’s ability to generalize across domains isn’t just a technical marvel—it’s a practical revolution.
Whether it's identifying previously unseen objects or contextualizing textual descriptions with visual data, CLIP sets a new standard in AI-powered applications.
This model’s foundation in zero-shot learning and natural language supervision makes it a vital tool for industries ranging from content creation to medical imaging. It doesn't just build on prior research—it redefines what’s possible in the intersection of vision and language.
Understanding GLIP: Revolutionizing Visual Representation
GLIP (Grounded Language-Image Pre-training) is redefining how we teach machines to understand the relationship between text and visuals. By focusing on object-level, language-aware, and semantically rich visual representations, GLIP stands out as a powerful foundation model with transformative capabilities.
What Makes GLIP Unique?
Unlike traditional models that separate tasks like object detection and phrase grounding, GLIP combines these processes during pre-training, resulting in a more integrated and versatile learning approach.
Let’s explore how this synergy drives its innovation:
1. Harnessing Image-Text Pairs at Scale
GLIP can leverage vast amounts of image-text pairs through self-training, where it generates its own grounding boxes. These self-generated boxes allow the model to refine its visual understanding, resulting in richer, more semantically meaningful representations.
2. Dual Learning Advantage
GLIP uses both detection and grounding data to enhance its capabilities. This dual training approach improves the performance of both object detection and phrase grounding tasks, creating a robust grounding model that excels at linking text to visual elements.
Why GLIP Matters
By combining object detection with phrase grounding, GLIP achieves a deeper understanding of visual data. Its ability to connect textual descriptions with specific visual elements makes it invaluable for applications requiring precision and context.
From powering advanced search engines to aiding augmented reality, GLIP sets the stage for the next generation of vision-language integration.
The Big Picture
GLIP’s innovative approach to grounding language and visuals isn’t just about creating better models—it’s about reimagining what’s possible in AI. By enhancing the semantic richness of visual representations, GLIP is opening up new avenues for industries to harness the full potential of multimodal AI.
In short, GLIP doesn’t just learn from data—it understands it on a deeper, more human-like level, paving the way for groundbreaking applications in image and language processing.
Let’s explore how this synergy drives its innovation:
Harnessing Image-Text Pairs at ScaleGLIP can leverage vast amounts of image-text pairs through self-training, where it generates its own grounding boxes. These self-generated boxes allow the model to refine its visual understanding, resulting in richer, more semantically meaningful representations.
Dual Learning AdvantageGLIP uses both detection and grounding data to enhance its capabilities. This dual training approach improves the performance of both object detection and phrase grounding tasks, creating a robust grounding model that excels at linking text to visual elements.
Why GLIP Matters
By combining object detection with phrase grounding, GLIP achieves a deeper understanding of visual data. Its ability to connect textual descriptions with specific visual elements makes it invaluable for applications requiring precision and context.
From powering advanced search engines to aiding augmented reality, GLIP sets the stage for the next generation of vision-language integration.
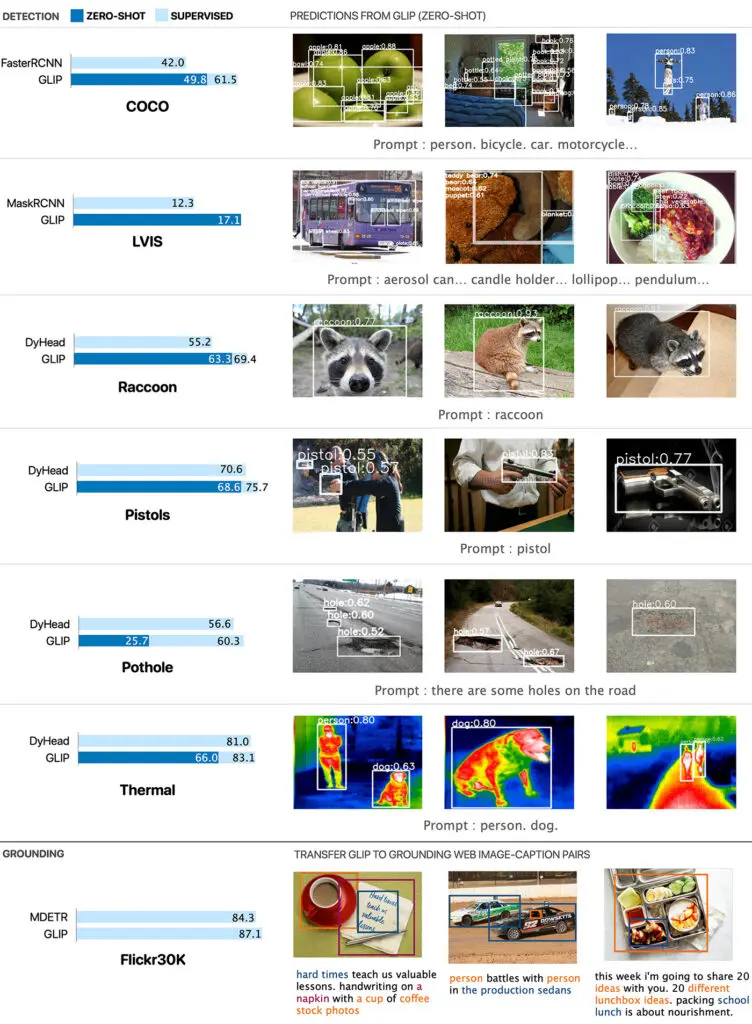
Figure: GLIP (Grounded Language-Image Pretraining)
The Big Picture
GLIP’s innovative approach to grounding language and visuals isn’t just about creating better models—it’s about reimagining what’s possible in AI. By enhancing the semantic richness of visual representations, GLIP is opening up new avenues for industries to harness the full potential of multimodal AI.
In short, GLIP doesn’t just learn from data—it understands it on a deeper, more human-like level, paving the way for groundbreaking applications in image and language processing.
Potential Use Cases
Foundation models like CLIP and GLIP are advanced machine learning models that combine language and image processing capabilities.
They can understand and retrieve images based on textual queries and vice versa, capturing fine-grained visual features and demonstrating semantic understanding.
Their adaptability and transfer learning enable them to excel in various image-related tasks, making them valuable for applications like image search and recommendation systems.
1. E-commerce Platforms
Users often rely on image-based searches to find specific products on e-commerce platforms.
By utilizing foundation models, users can upload images of desired products or provide textual descriptions, and the system can retrieve visually similar items from the inventory. This enhances the shopping experience by offering accurate and visually relevant product recommendations.
Figure: Image Recommendations using Foundational Models
For example, suppose you upload an image of a floral maxi dress with a specific color palette and pattern. In that case, the image-based search system powered by foundation models can retrieve dresses that share similar floral patterns, color combinations, and overall design aesthetic.
This ensures that the recommended products align closely with your preferences and expectations.
By enabling image-based searches and leveraging foundation models, e-commerce platforms can enhance users shopping experience.
The accuracy of the product recommendations increases as they are based on visual similarities rather than solely relying on textual descriptions.
This saves users time and effort finding the desired products and provides a visually satisfying and personalized shopping experience.
2. Visual Content Management
For organizations or individuals dealing with extensive collections of visual content, such as photographers, media agencies, or stock photo platforms, image queries using foundation models can streamline content management.
Users can search for specific images based on their visual characteristics, saving time and effort manually categorizing and tagging images.
For instance, A photographer has a vast collection of landscape photographs, including images of mountains, beaches, forests, and cityscapes. Instead of manually organizing these images into different folders or tagging them individually, the photographer can utilize the power of foundation models.
Figure: Collection of similar images
The photographer can upload an image representing the desired visual characteristic using the image query functionality.
For example, they might upload a stunning landscape photo featuring snow-capped mountains. The foundation model then analyzes the visual features of the uploaded image, capturing details like the snowy peaks, blue sky, and overall composition.
3. Art and Design
Image queries can be valuable for inspiration and reference purposes in art and design. Artists, designers, and creative professionals can use foundation models to search for specific visual styles, color palettes, or composition elements.
This allows them to discover relevant artworks, designs, or photographs that align with their creative vision.
For example, the artist may have a concept for a vibrant and abstract painting with bold, geometric shapes. Using the image query feature, they can input relevant keywords or upload an image representing the desired visual style, such as a painting with similar characteristics or a photograph featuring vibrant geometric patterns.
The foundation model then analyzes the visual elements of the query image, identifying key features like vibrant colors, bold shapes, and abstract composition. Based on this analysis, the model retrieves a curated selection of artworks, designs, or photographs that exhibit similar visual styles.
The artist can explore these search results and discover relevant pieces that resonate with their creative vision.
They may find paintings by renowned artists known for using vibrant colors and geometric shapes, or they may come across contemporary designs incorporating similar elements.
4. Visual Similarity Search
Image query using foundation models can facilitate visual similarity search, where users can search for images that closely resemble a given query image. This can be useful in fashion, interior design, or product design, where users may seek images with similar styles, patterns, or aesthetics.
For example, let's consider a user looking for a new outfit with a specific dress in mind.
They might have a photo of a celebrity or a fashion model wearing a dress they find appealing. Using the image query feature with a foundation model, the user can upload or provide the query image as a reference.
The foundation model then analyzes the visual features in the query image, such as the dress's style, color, pattern, and silhouette.
Based on this analysis, the model retrieves a curated selection of visually similar images from a database or inventory.
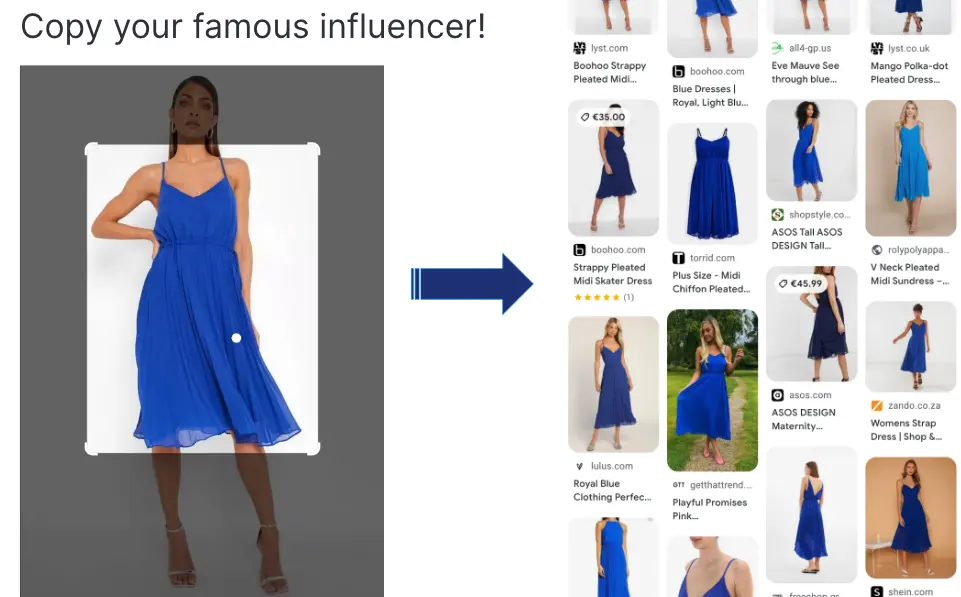
Figure: Visual Similarity Search for Fashion Purpose
In the context of fashion, the user can explore the search results and find dresses that closely resemble the one in the query image.
They may discover similar styles, patterns, or aesthetics, allowing them to explore a broader range of options and find dresses that align with their preferences.
5. Visual Storytelling and Journalism
Journalists and storytellers often rely on visuals to convey narratives and evoke emotions. Image query using foundation models can assist in finding relevant and impactful images that align with the story or article's theme. This enables journalists to enhance their storytelling with powerful visual elements.
For example, imagine a journalist working on a news article about environmental issues and the impact of deforestation.
They want to include images that vividly depict forests' destruction and the ecosystem's consequences. Using an image query with a foundation model, the journalist can input relevant keywords or upload an image representing their story's essence, such as a photo of a clear-cut forest.
The foundation model then analyzes the visual features and context of the query image, identifying key elements like trees, deforestation, and environmental degradation.
Based on this analysis, the model retrieves a curated selection of images that capture the essence of deforestation and its environmental impact.
Conclusion
Foundation models like CLIP and GLIP are reshaping the landscape of image search by offering enhanced efficiency, accuracy, and adaptability.
These multimodal models bridge the gap between visual and textual data, enabling more precise and context-aware image retrieval.
By integrating the power of natural language and object-level understanding, CLIP and GLIP offer transformative potential across industries, from e-commerce and visual content management to art, design, and journalism.
As AI continues to evolve, these models represent a significant leap forward, empowering businesses and users with smarter, faster, and more intuitive image search capabilities.
Frequently Asked Questions (FAQ)
What is a foundation model in AI?
A foundation model, also known as a base model, is a substantial machine learning (ML) model that undergoes extensive training on a comprehensive dataset, typically through self-supervised or semi-supervised learning.
This training process enables the model to be flexible and applicable to a diverse set of following tasks.
What are the risks of foundational models?
Foundation models share certain risks with other AI models, such as the potential for bias. However, they can also introduce new risks and magnify existing ones, including the ability to generate misleading content that appears plausible, a phenomenon known as hallucination.
What are the 4 types of AI models?
There are four primary categories of AI models: reactive machines, limited memory models, theory-of-mind models, and self-aware models. These categories represent different levels of AI capabilities and functionalities.
What are the various categories of foundation models?
Foundation models can be classified into three main types: language models, computer vision models, and generative models. Each of these types serves distinct purposes and tackles specific challenges within the field of artificial intelligence.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
