

CVPR 2023: Key Takeaways & Future Trends


The atmosphere was charged with excitement at CVPR 2023 in Vancouver, the renowned conference for computer vision.
Researchers and practitioners gathered to exchange ideas about the significant advancements in the field over the past year and discuss the future of computer vision and AI as a whole.
The predominant subjects covered in the papers presented at this year's conference encompassed a range of areas, including 3D reconstruction from multiple views and sensors, image and video generation with a focus on diffusion models, face/body/pose estimations, continual learning, multi-modality combining vision and language, as well as efficient modeling techniques.
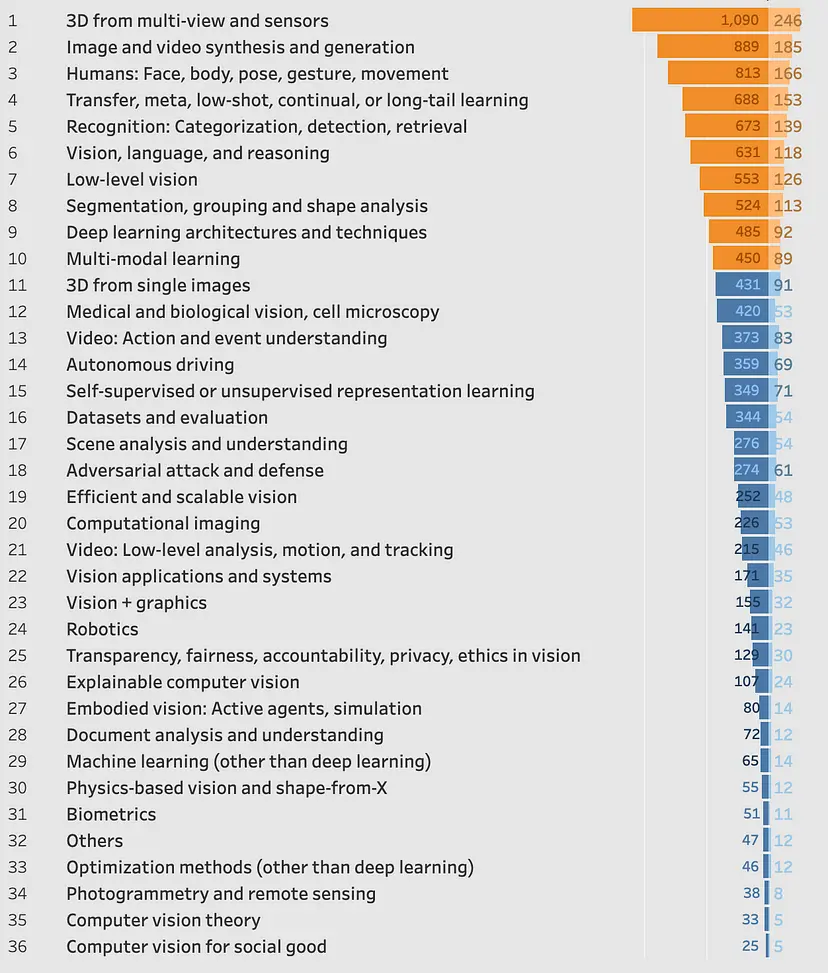
Figure: Distribution of Papers Published and Number of Authors
In this post, we will delve into the key themes and highlights of CVPR 2023, providing insights into the conference and predicting the major trends that will shape the computer vision landscape in the upcoming year.
Table of Contents
- A Survey of CVPR Conference
- Major Highlights of The Conference
- Labellers Recommendations
- Conclusion
- Frequently Asked Questions (FAQ)
A Survey of CVPR Conference
After analyzing the data till the present CVPR, the interaction from in-person CVPR attendees provided the following profile:
1. Attendee Distribution by Category
We looked at the distribution of participants based on their current career profiles. These include:
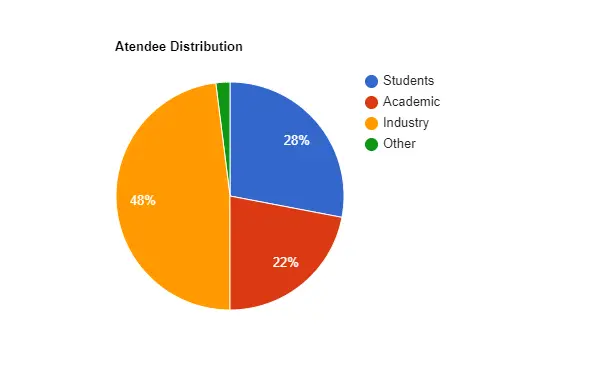
Figure: Pie Chart for Atendee Distribution
2. Industry / Job Sectors
The attendees of CVPR encompass a diverse range of professionals from various job functions. The survey revealed that 4% of attendees identified themselves in management roles, indicating their involvement in overseeing strategic decisions and guiding teams within the field of computer vision.
The majority of attendees, comprising 63%, were engaged in research and education, highlighting the significant presence of academic professionals and scholars who contribute to the advancement of computer vision knowledge.
Furthermore, 29% of attendees were involved in engineering and development, underscoring the crucial role played by practitioners in translating research into practical applications. The remaining 4% represented other job functions, representing diverse roles within the computer vision community.
.webp)
Figure: Pie Chart for Industry Distribution
3. Business / Organizations Attended
CVPR attracts attendees from a wide range of business sectors and organizations, each contributing to the advancements in computer vision.
The survey results indicate that 15% of attendees are affiliated with the manufacturing industry, highlighting the application of computer vision in production processes and industrial settings.
Additionally, 20% of attendees represent the services sector, demonstrating the relevance of computer vision in areas such as healthcare, finance, and retail.
Research and development organizations make up 12% of the attendees, emphasizing the critical role of innovation and technological advancements in shaping the field.
Education constitutes a significant portion, with 34% of attendees coming from academic institutions, underlining the importance of educational institutions in driving research and training future computer vision professionals.
Government entities represent 4% of attendees, reflecting the involvement of public institutions in leveraging computer vision for public services and security.
Lastly, 15% of attendees belong to other sectors, showcasing the diversity of organizations with an interest in computer vision, including startups, non-profit organizations, and more.
.webp)
Figure: Pie Chart for Different Business Domains
4. Organization Size
CVPR attracts attendees from organizations of various sizes, reflecting the broad spectrum of involvement in the field of computer vision.
The survey results reveal that a significant portion, comprising 32% of attendees, hail from organizations with over 10,000 employees. These large-scale enterprises demonstrate a substantial investment in computer vision research and implementation, highlighting their capacity for extensive resources and infrastructures.
Additionally, 9% of attendees belong to organizations with 5,001 to 10,000 employees, signifying their significant presence and commitment to the field. Organizations with 1,001 to 5,000 employees make up 16% of the attendees, emphasizing the considerable representation of medium-sized entities with substantial capabilities.
Furthermore, 20% of attendees come from organizations with 101 to 1,000 employees, showcasing the participation of small to medium-sized enterprises in the computer vision landscape.
Finally, 23% of attendees represent organizations with 1 to 100 employees, underscoring the involvement of startups, research labs, and entrepreneurial ventures, which play a crucial role in driving innovation and pushing the boundaries of computer vision technology.
.webp)
Figure: Pie Chart for Organization sizes
This systematically designed survey offers insights into the demographics and profiles of CVPR attendees, including their affiliations, roles, industries, organization sizes, and age distributions.
Major Highlights of The Conference
In this section, we will go through various important aspects considered in the CVPR 23 Conference.
1. The Rise of AI in the Commercial Landscape
The integration of AI into the commercial sector has gained significant momentum, reflecting the current climate's appetite for AI innovation. According to a study conducted by Accenture, an overwhelming 73% of companies prioritize AI investments above all other digital initiatives in 2023.
Moreover, 90% of business leaders are leveraging AI to enhance operational resilience. Notably, enterprise businesses are at the forefront of AI adoption, with 68% of large companies embracing at least one AI technology in 2022.
The profound impact of this paradigm shift is difficult to overstate. AI implementation is projected to contribute to a 7% increase in global GDP, as estimated by Goldman Sachs.
Further, research by PWC suggests that 40% of these economic gains will stem from AI-driven advancements, underscoring the transformative potential of AI in various sectors of the economy.
2. The Vision Transformer Emergence
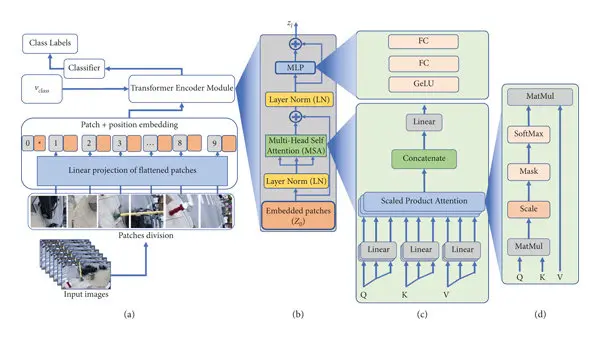
Figure: Vision Transformer Architecture
Transformer architecture has made remarkable progress in the field of AI research. Recently, the vision transformer has made its mark in the domain of computer vision.
Leveraging the transformer architecture, the vision transformer treats a patch of pixels as a text sequence, enabling the same architecture to be employed for vision-related tasks.
CVPR 2023 witnessed a surge of new techniques focused on the vision transformer. Researchers dedicated their efforts to analyzing biases, pruning, pretraining, distilling, reverse distilling, and applying the vision transformer to novel tasks.
Here are some noteworthy papers in this domain:
- OneFormer: One Transformer To Rule Universal Image Segmentation
- Q-DETR: An Efficient Low-Bit Quantized Detection Transformer
- SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer
3. Need for foundation models in Computer Vision
Computer vision is in search of a foundational model that can serve as a basis for a wide range of tasks. Like language models in NLP, which have proven effective across various tasks, computer vision lacks a universal model and loss objective that can be scaled with model size.
In the academic research community, there is a recognition that competing with industrial research labs in terms of computational resources is challenging. Therefore, the focus is on achieving more with limited resources, as emphasized in the keynotes at CVPR.
During CVPR, several research labs presented their work on general pre-trained computer vision models, particularly at the intersection of language and images. These models aimed to tackle various tasks and modalities, such as zero-shot object detection, segmentation, and multi-modal learning.
Notable discussions included:
- Grounding DINO: Zero-shot object detection with a multi-modal approach
- SAM: Zero-shot segmentation using image-only input
- Multi-modal GPT-4 (although its presence was not as expected)
- Florence: A general-purpose model for multi-modal tasks
- OWL-VIT: Zero-shot object detection with a multi-modal approach
CLIP, a strong research lineage model, also received attention at CVPR. Exciting research on foundational embedding models for computer vision was presented, including topics like language-guided sampling, distributed contrastive loss, retrieval augmented pre-training, and masked self-distillation for contrastive language-image pre-training.
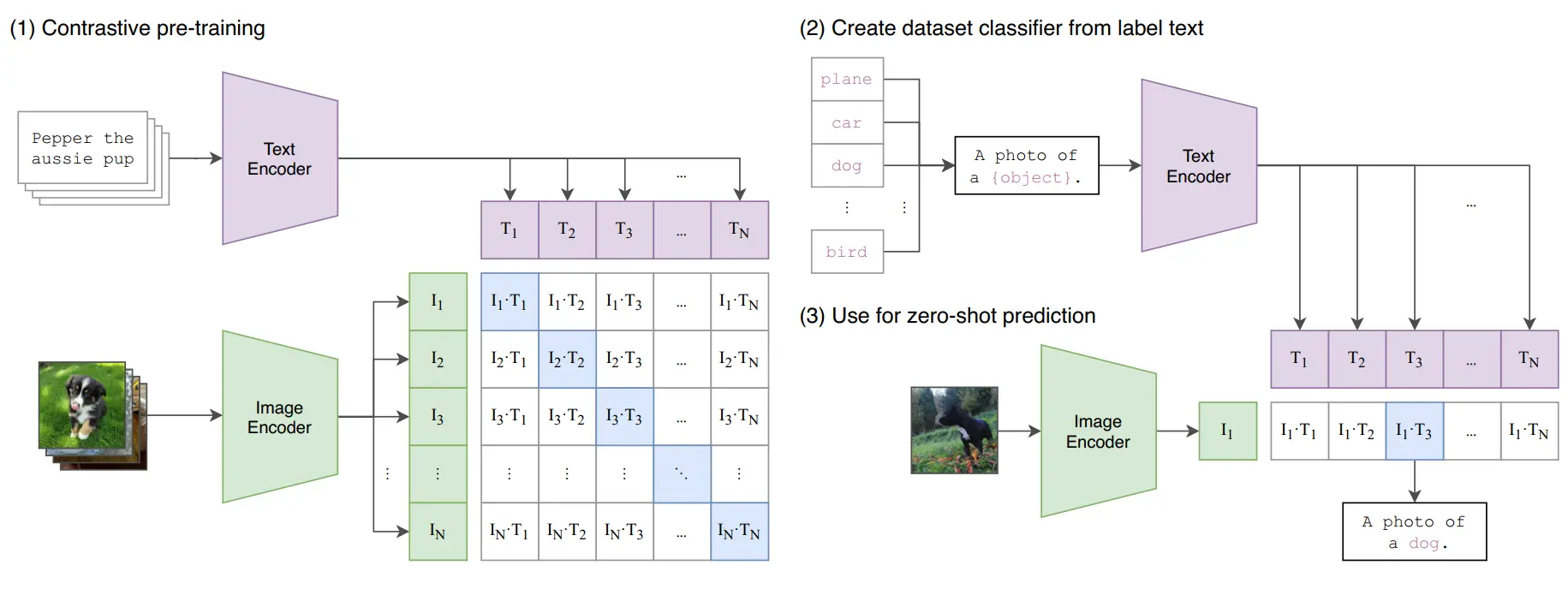
Figure: CLIP Architecture and Working
Looking ahead, significant progress and focus are anticipated in the development of foundational computer vision models. The coming year will likely bring the release of innovative and promising models in this field.
4. Introduction of Novel Datasets
A series of informative workshops took place at CVPR 2023, with a central theme focused on real-world datasets.
In the realm of visual perception, open-world data exhibits a long-tailed distribution, emphasizing rare and underrepresented examples that traditional models struggle to handle.
This can lead to ethical issues, such as misclassifying underrepresented minorities. Additionally, the open world introduces unknown examples that pose significant challenges, as models must be able to detect and adapt to these unfamiliar instances.
Furthermore, the ever-changing nature of the open world requires models to continuously learn and adjust to evolving data distributions and semantic meanings. Addressing distribution shifts and concept drifts becomes paramount in effectively navigating the complexities of the open world.
A notable "Visual Perception via Learning in an Open World" workshop perfectly encapsulated this emphasis. The workshop provided valuable insights into the distinctive characteristics of open-world data, including its open-vocabulary nature, object class ontology/taxonomy, and evolving class definitions.
The datasets showcased in this workshop spanned diverse categories, encompassing mixed reality, autonomous driving, real-life safety and security, agriculture, data captured from Unmanned Aerial Vehicles (UAVs) or satellites, animal behavior, and open dataset object categories.
These datasets shared similar traits with raw data, featuring long-tailed distributions, open-set scenarios, unknowns, streaming data, biased data, unlabeled data, anomalies, and multi-modality attributes.
In the current conference, various different datasets were further introduced to aid the development of machine learning/computer vision in different domains. These include:
i) FLAG3D: A 3D Fitness Activity Dataset with Language Instructions
In this paper, the authors address the need for high-quality data resources in the field of fitness activity analytics in computer vision.
They introduce FLAG3D, a large-scale 3D fitness activity dataset that contains 180,000 sequences across 60 categories.
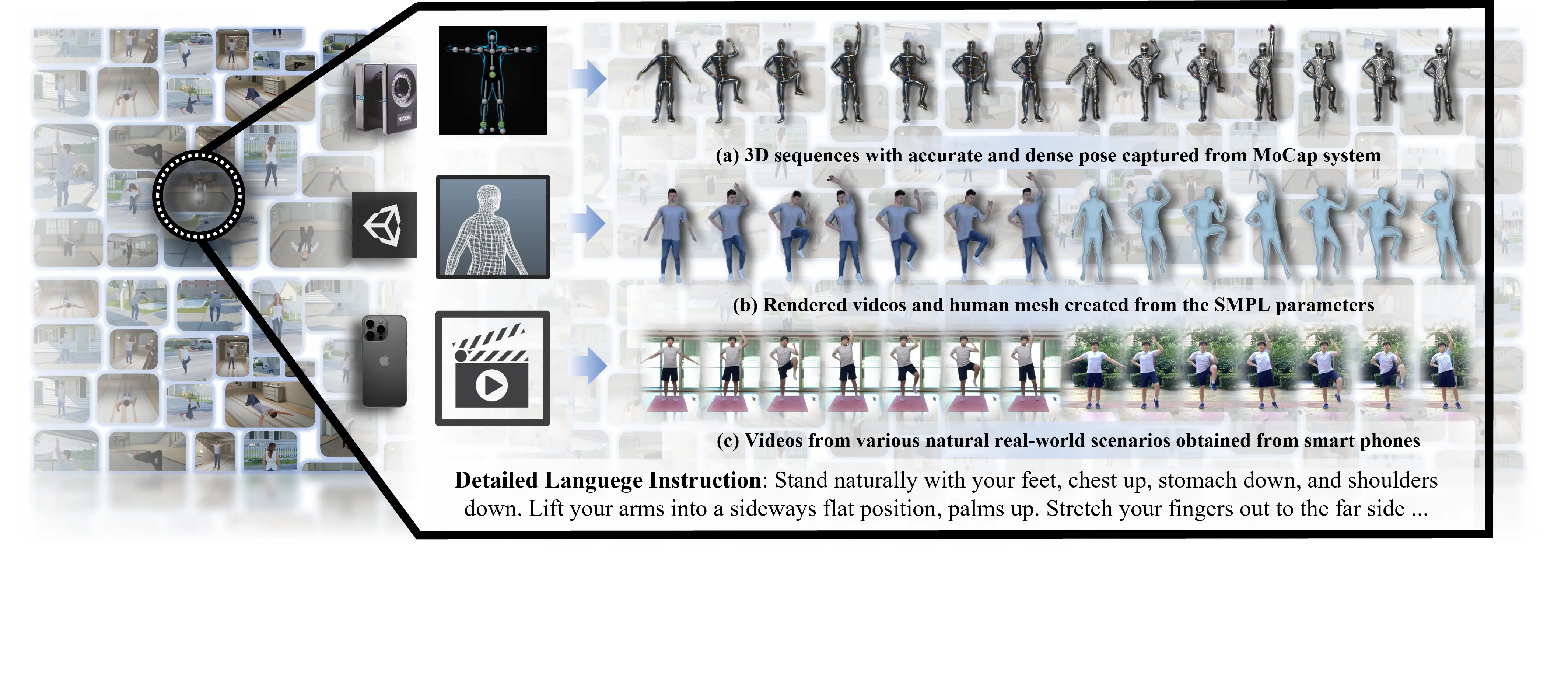
Figure: Sample for Flag3D Dataset
The dataset offers three key aspects:
- Accurate and dense 3D human pose captured using an advanced motion capture (MoCap) system to handle complex activities and large movements.
- Detailed and professional language instructions that describe how to perform specific activities.
- Versatile video resources are obtained from a combination of high-tech MoCap systems, rendering software, and cost-effective smartphones in natural environments.
Through extensive experiments and in-depth analysis, the authors demonstrate the research value of FLAG3D in various challenges, including cross-domain human action recognition, dynamic human mesh recovery, and language-guided human action generation.
ii) LOGO: A Long-Form Video Dataset for Group Action Quality Assessment
In summary, this work addresses the limitations of existing methods and datasets in action quality assessment (AQA) by introducing a new dataset called LOGO, specifically designed for assessing action quality in multi-person long-form videos.
The LOGO dataset consists of 200 videos from 26 artistic swimming events, each featuring 8 athletes and having an average duration of 204.2 seconds.
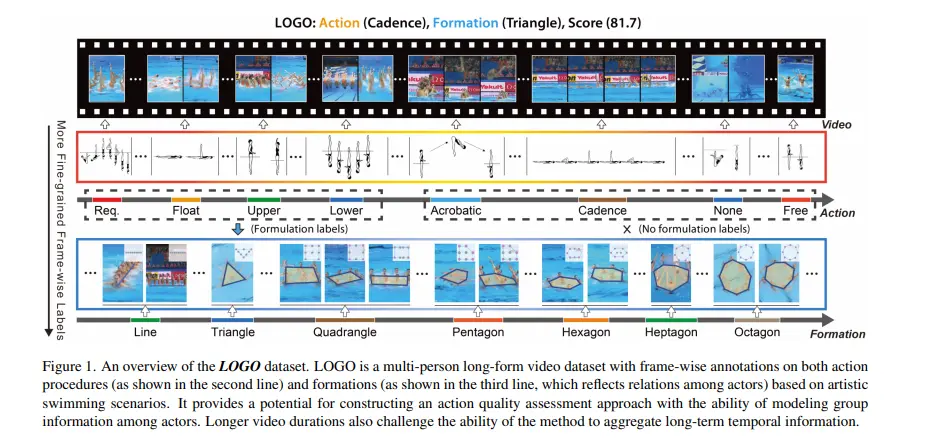
Figure: Sample LOGO Dataset
The dataset includes rich annotations, such as formation labels depicting group information and detailed annotations on action procedures. The authors also propose a simple yet effective method that models relations among athletes and reasoning about potential temporal logic in long-form videos.
They design a group-aware attention module that can be incorporated into existing AQA methods to enhance clip-wise representations based on contextual group information.
Through comprehensive experiments and benchmarking, the authors demonstrate the challenges the LOGO dataset poses and show that their approach achieves state-of-the-art results.
5. Machine Learning Approaches, Strategies, and Objectives
While discussions about general models were prevalent at the conference, CVPR 2023 primarily focused on more traditional research in the techniques and tasks of computer vision.
Significant advancements were made in various tasks, including NERFs (Neural Radiance Fields), pose estimation and tracking, and the introduction of novel approaches and routines.
Researchers also made progress in general machine learning techniques by exploring theoretical foundations and empirical findings to enhance training procedures.
Some notable practical machine learning research that caught our attention includes:
- Soft Augmentation for Image Classification: Introducing techniques to improve image classification performance through soft augmentation methods.
- FFCV: Accelerating Training by Removing Data Bottlenecks: Proposing strategies to enhance training speed by addressing data-related limitations.
- The Role of Pre-training Data in Transfer Learning: Investigating the impact of pre-training data on transfer learning, with implications for model performance in new domains.
CVPR 2023 showcased significant developments in machine learning techniques, tactics, and specific tasks, reflecting computer vision research's continuous evolution and advancement.
6. Industry versus Research: A Prominent Dichotomy
A tangible distinction between the research poster sessions and company booths highlighted the contrasting perspectives on the future of the field and the practical applications in the present.
The research-oriented posters and workshop sessions predominantly centered around vision transformers, showcasing cutting-edge advancements in the academic realm.
On the other hand, the industry booths prominently featured Python code snippets integrating YOLO models, highlighting practical implementations.
 Figure: YOLO Overview
Figure: YOLO Overview
Figure: YOLO Overview
We were particularly thrilled to witness substantial advancements made by industry companies focused on data annotation services, cloud computing, and model acceleration. These developments signify the growing progress in industry-driven applications of computer vision.
6. Advancements in Large Language Models and Multi-Modality of LLM
The emergence of large language models, exemplified by GPT-4, has brought about a transformative impact on computer vision by bridging the gap between visual data analysis and linguistic understanding.
This paradigm shift has enabled models to generate comprehensive descriptions for images, generate text based on visual input, and even produce images in response to textual prompts.
The integration of these powerful language models has opened up new avenues for interpreting and manipulating visual data by leveraging their extensive linguistic capabilities and contextual comprehension.
Figure: Question - Answering via a Multi-Model AI Network
Simultaneously, there has been a significant surge in the adoption of multi-modality, which involves combining computer vision with other domains such as natural language processing, sound, and speech.
By incorporating data from diverse sources, multi-modal models can achieve a holistic understanding and analysis of information.
These models excel in tasks like image captioning and visual question answering (VQA), where they process visual and textual data to generate accurate responses. This cross-modal proficiency drives advancements in image recognition, visual reasoning, and image synthesis.
Moreover, it facilitates multidisciplinary applications that integrate computer vision with NLP, speech recognition, or audio analysis to tackle complex problems requiring multiple modalities' fusion.
7. The Potential of Generative AI
The demonstration of Google's DreamBooth served as a remarkable testament to the immense potential of Generative AI in the field of Computer Vision.
The capabilities of this technology can be further enhanced when applied to prompts and utilized for editing specific sections of an image or generating personalized images and videos.

Figure: Output Produced By fine-tuning model using DraemBooth Methodology
Video content generation, in particular, holds significant promise for industries such as advertising. Platforms specializing in short-form videos, like YouTube Shorts or TikTok, could greatly benefit from the application of Generative AI, and its potential applications could extend to the broader entertainment industry.
The industry's focus on generative AI becomes evident when observing the substantial number of research papers on Generative AI published by tech giants like Google, NVIDIA, and Qualcomm.
This emphasis underscores the vast potential and ever-growing interest in this field, signaling that the domain of Generative AI offers abundant opportunities for further research and exploration.
8. Bridging the Gap with MLOps in Computer Vision and Beyond
Once the model weights have been fine-tuned for tasks such as detection, segmentation, and video analysis, the next exciting phase for academic researchers involves seamlessly integrating these models into real-world pipelines that can effectively interact with the complexities of our surroundings.
This transition from theoretical advancements to practical applications breathes life into the true impact of these models. Researchers can witness their innovations making a tangible difference in various industries and domains by establishing a connection between academia and real-world implementation.
MLOps, also known as Machine Learning Operations, plays a crucial role in shaping the future of computer vision, NLP, sound, speech, and numerous other industries.
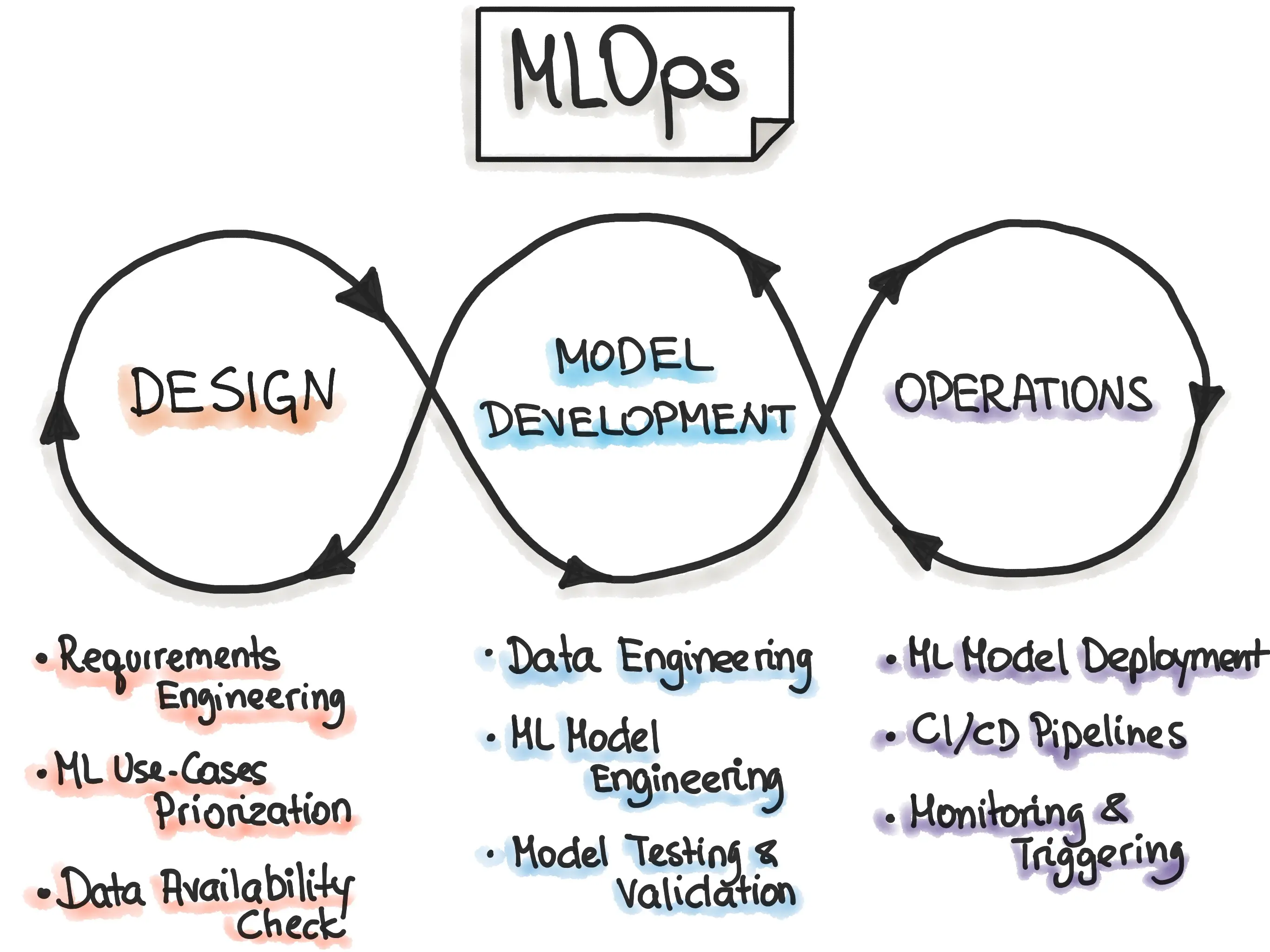
Figure: MLOps Cycle
By offering a framework for efficient deployment, continuous monitoring, scalability, collaboration, governance, cost optimization, and agility, MLOps empowers researchers to harness the potential of machine learning effectively.
It enables them to drive innovation, unlock the full capabilities of these technologies, and achieve significant advancements across diverse domains.
Best Papers Introduced
1. Visual Programming: Compositional visual reasoning without training
VISPROG is presented as a neuro-symbolic approach that tackles complex and compositional visual tasks by leveraging natural language instructions.
It stands out by avoiding the need for task-specific training and instead harnesses the contextual learning abilities of large language models. VISPROG generates modular programs in a Python-like format, which are then executed to obtain both the solution and a comprehensive rationale that can be easily interpreted.
Each line of the generated program can invoke various off-the-shelf computer vision models, image processing subroutines, or Python functions to produce intermediate outputs that subsequent parts of the program can utilize.
The flexibility of VISPROG is demonstrated across four diverse tasks, including compositional visual question answering, zero-shot reasoning on image pairs, factual knowledge object tagging, and language-guided image editing.
Neuro-symbolic approaches like VISPROG are seen as an exciting avenue for expanding the capabilities of AI systems, allowing them to effectively address complex tasks that span a wide range of applications.
2. Planning-oriented Autonomous Driving
The modern autonomous driving system operates through a modular framework where tasks such as perception, prediction, and planning are performed sequentially.
To achieve advanced-level intelligence and handle diverse tasks, existing approaches either employ separate models for each task or utilize a multi-task paradigm with distinct heads.
However, these approaches can suffer from accumulated errors or a lack of effective task coordination. Instead, we propose the development of a framework that optimizes the ultimate goal: planning for self-driving cars.
With this objective in mind, we reevaluate the key components of perception and prediction and prioritize tasks that contribute to planning.
We introduce Unified Autonomous Driving (UniAD), a comprehensive framework that integrates all driving tasks into a single network.
UniAD is meticulously designed to leverage the strengths of each module and provide complementary feature abstractions, enabling agent interaction from a global perspective. Tasks within UniAD are interconnected through unified query interfaces to facilitate mutual support toward planning.
We demonstrate the effectiveness of this approach by instantiating UniAD on the challenging nuScenes benchmark and conducting extensive evaluations. The results confirm the superiority of our philosophy, as UniAD significantly outperforms previous state-of-the-art methods in all aspects.
Identified Trends in Computer Vision Research from CVPR 2023
Based on the selection of papers considered as award candidates at CVPR 2023, several notable trends emerged in the field of computer vision research:
1. Neuro-symbolic approaches
The paper "Visual Programming: Compositional Visual Reasoning Without Training" introduces the neuro-symbolic approach VISPROG, which utilizes large language models to generate modular programs for solving complex visual tasks. This trend explores the integration of neural networks and symbolic reasoning to enhance visual reasoning capabilities.

Figure: Visual Perception with Reasoning
2. Data-driven methods
The paper "Data-Driven Feature Tracking for Event Cameras" presents a data-driven approach for feature tracking in event cameras, leveraging low-latency events and knowledge transfer from synthetic to real data. This trend focuses on leveraging and learning from large datasets to improve performance and generalization.
3. Efficient generation models
Two papers, "On Distillation of Guided Diffusion Models" and "MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures," address the efficiency of image generation models.
They propose distillation methods and alternative representations to speed up the sampling process, making these models more practical and accessible.
4. Context-aware rendering and synthesis
The papers "DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation" and "DynIBaR: Neural Dynamic Image-Based Rendering" focus on improving image synthesis from text prompts and generating novel views from videos.
These papers emphasize the importance of considering contextual information and dynamic scene understanding in image synthesis and rendering tasks.

Figure: Output For DynIBaR For synthesizing novel dynamic views from videos
5. Holistic frameworks
The paper "Planning-Oriented Autonomous Driving" introduces UniAD, a comprehensive framework integrating perception, prediction, and planning tasks into a single network.
This trend highlights the development of unified frameworks that optimize for the ultimate goal, improving coordination and performance across different tasks in autonomous driving.
6. Datasets and benchmarks
The papers "OmniObject3D: Large-Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and Generation" and "3D Registration With Maximal Cliques" focus on creating large-scale datasets and benchmarks for 3D object understanding and point cloud registration.
These efforts aim to provide resources for advancing research in realistic 3D vision and improving algorithm performance evaluation.
Labellers Recommendations
Well, a lot of papers have been accepted in this current CVPR 2023. Some of the most interesting papers, which is labeller recommended:
1. Turning a CLIP Model into a Scene Text Detector
In this paper, the authors propose a novel method called TCM (Turning the CLIP Model) for scene text detection without the need for pretraining. They leverage the recent large-scale Contrastive Language-Image Pretraining (CLIP) model, which combines vision and language knowledge, and demonstrate its potential for text detection.
The advantages of TCM are highlighted as follows:
- It can improve existing scene text detectors by applying the underlying principles of the framework.
- TCM enables few-shot training, achieving significant performance improvements with only 10% of labeled data compared to the baseline method, with an average F-measure improvement of 22% on four benchmarks.
- By integrating the CLIP model into existing scene text detection methods, TCM exhibits promising domain adaptation capabilities.
2. GFPose: Learning 3D Human Pose Prior With Gradient Fields
In the context of human-centered AI, the ability to learn 3D human pose prior is crucial. A versatile framework called GFPose is introduced, which aims to model plausible 3D human poses for various applications.
At the core of GFPose is a time-dependent score network that estimates the gradient on each body joint and progressively denoises the perturbed 3D human pose to align with a given task specification.
During the denoising process, GFPose incorporates pose priors in gradients, allowing it to unify different discriminative and generative tasks within a unified framework. Despite its simplicity, GFPose exhibits promising potential in several downstream tasks.
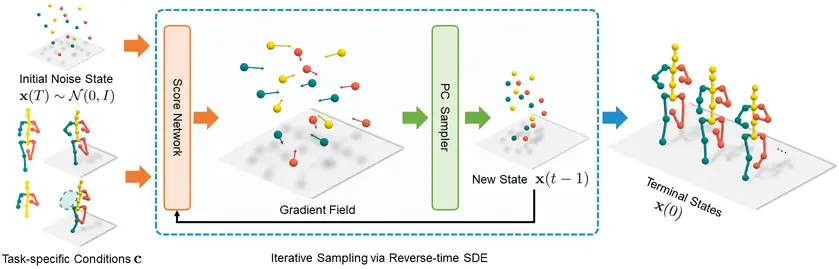
Figure: GFPose Human Pose Generation from Gradient Fields
Experimental results demonstrate that GFPose outperforms existing state-of-the-art methods by 20% on the Human3.6M dataset as a multi-hypothesis pose estimator. As a single-hypothesis pose estimator, GFPose achieves comparable results to deterministic state-of-the-art methods, even with a vanilla backbone.
Additionally, GFPose is capable of producing diverse and realistic samples in pose denoising, completion, and generation tasks.
The contributions of this work can be summarized as follows:
- The introduction of GFPose, a new generative framework based on scores, enables the modeling of plausible 3D human poses.
- The design of a hierarchical condition masking strategy enhances the versatility of GFPose, allowing it to be directly applied to various downstream tasks.
- Demonstrating the superior performance of GFPose compared to state-of-the-art methods across multiple tasks within a unified and straightforward framework.
3. MSeg3D: Multi-Modal 3D Semantic Segmentation for Autonomous Driving
In the context of autonomous driving, LiDAR (Light Detection and Ranging) and camera are two sensor modalities used for 3D semantic segmentation. However, relying solely on LiDAR data for segmentation often results in poor performance on small and distant objects due to limited laser points.
To address this, a multi-modal approach is proposed to overcome challenges related to modality heterogeneity, limited sensor field of view intersection, and multi-modal data augmentation.
The proposed model, MSeg3D, combines the strengths of LiDAR and the camera by extracting features within each modality and fusing them together.
The fusion process includes geometry-based feature fusion, cross-modal feature completion, and semantic-based feature fusion. Additionally, multi-modal data augmentation is enhanced by applying asymmetric transformations to LiDAR point cloud and camera images separately, enabling diversified augmentation during model training.
.webp)
Figure: Segmentation of Images During Autonomous Driving
MSeg3D achieves state-of-the-art results on various datasets and demonstrates robustness even under malfunctioning camera input or multi-frame point clouds, improving upon the LiDAR-only baseline.
Conclusion
CVPR 2023, the renowned computer vision conference held in Vancouver, was charged with excitement as researchers and practitioners gathered to share groundbreaking advancements and discuss the future of computer vision and AI as a whole. The papers presented at the conference covered a wide range of topics, reflecting the diverse and dynamic nature of computer vision research.
One of the predominant subjects covered in the papers was 3D reconstruction from multiple views and sensors. Researchers explored implicit representations and Neural Radiance Fields (NERFs), pushing the boundaries of 3D reconstruction techniques.
Image and video generation also took center stage, focusing on diffusion models that generate realistic, high-quality visual content. Additionally, face, body, and pose estimations, as well as continual learning and multi-modality approaches combining vision and language, showcased the multifaceted nature of computer vision research.
Efficient modeling techniques were also a key focus, aiming to optimize the generation process and make it more accessible for practical applications.
A notable aspect of CVPR 2023 was the survey conducted among attendees, providing valuable insights into the demographics and profiles of the conference participants. The majority of attendees (48%) represented the industry sector, underlining the growing integration of AI in commercial applications.
Academic professionals (22%) and students (28%) also had a significant presence, showcasing the active involvement of the research community. The attendees spanned various job sectors, with a strong representation from research/education (63%) and engineering/development (29%).
The conference highlighted the emergence of the vision transformer in computer vision, where the transformer architecture traditionally used in natural language processing was successfully applied to vision-related tasks.
The vision transformer treats a patch of pixels as a text sequence, enabling the use of the same architecture for both vision and language tasks.
Another significant trend observed at CVPR 2023 was the quest for foundational models in computer vision. Similar to language models in natural language processing, computer vision aims to develop a universal model and loss objective that can be scaled with model size.
The academic research community focused on achieving more with limited resources and explored various approaches to generalize and transfer learning.
CVPR 2023 also emphasized the importance of novel datasets and benchmarks for advancing computer vision research. Workshops and papers showcased the creation of large-scale datasets covering diverse domains such as mixed reality, autonomous driving, agriculture, and more.
These datasets exhibit characteristics similar to raw data, with features like long-tailed distributions, open-set scenarios, and multi-modality attributes.
Looking ahead, the conference provided valuable insights into the major trends that will shape the computer vision landscape in the upcoming year. The integration of AI in the commercial sector, the rise of the vision transformer, the search for foundational models, the introduction of novel datasets, and the advancements in machine learning approaches all indicate a vibrant and rapidly evolving field.
CVPR 2023 served as a platform for knowledge exchange, collaboration, and inspiration, paving the way for continued innovation and breakthroughs in computer vision research.
Frequently Asked Questions (FAQ)
1. What is the acceptance rate for CVPR 2023?
CVPR 2023 had an acceptance rate of 25.78%, meaning that out of the 9,155 submissions received, 2,360 were accepted for presentation at the conference.
2. What is the topic of CVPR 2023?
CVPR 2023 covers a wide range of topics in computer vision and pattern recognition, encompassing areas such as 3D reconstruction from multiple views and sensors, 3D reconstruction from single images, as well as adversarial attack and defense techniques. These topics represent just a subset of the diverse subjects explored at the conference.
3. What is the best paper at CVPR 2023?
CVPR 2023 recognized several outstanding papers for their excellence. The Best Paper award was given to "Visual Programming: Compositional visual reasoning without Training" for its innovative approach to compositional visual reasoning. Another notable paper, "Planning-oriented Autonomous Driving," received the Best Paper award for its contributions to advancing autonomous driving systems.
Additionally, "DynIBaR: Neural Dynamic Image-Based Rendering" received an Honorable Mention for its significant contributions to image-based rendering.
Finally, the Best Student Paper award was granted to "3D Registration with Maximal Cliques" for its exceptional work in the field of 3D registration. These papers represent the top contributions acknowledged by CVPR 2023.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
