

Beginner's Guide: Using Foundation Models in ML Projects
Foundation models, like GPT-3 and BERT, simplify ML projects by providing pre-trained models that can be fine-tuned for specific tasks, reducing development time. This guide covers setup, fine-tuning, and deployment to help you get started effectively.

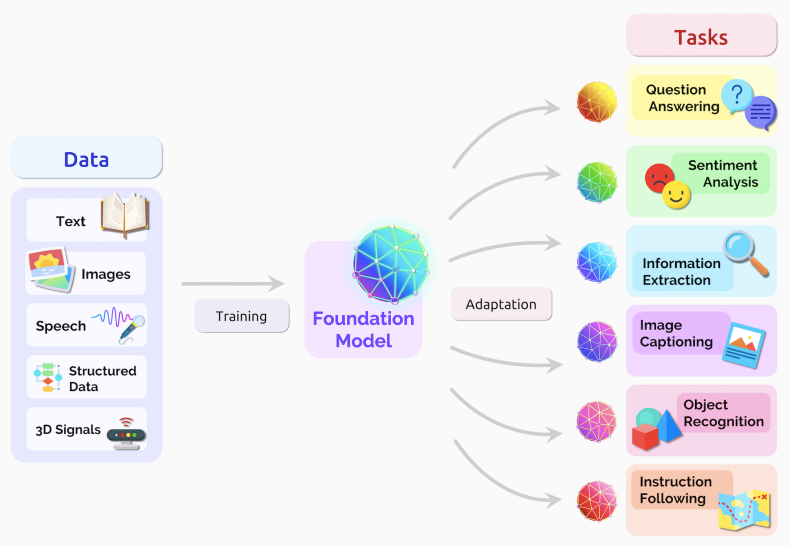
Machine learning has become a popular tool for solving complex problems across various industries, from healthcare to finance to retail. One of the most exciting developments in the field has been the rise of foundation models, which are pre-trained models that can be fine-tuned for specific tasks.
Foundation models have significantly reduced the time and effort required to develop effective machine-learning models, making it easier for beginners to get started in the field.
In this beginner's guide, we will explore what foundation models are, how they work, and how to use them in your own machine-learning projects.
We will also discuss some popular foundation models available today, including OpenAI's GPT-3 and Google's BERT. By the end of this guide, you will have a solid understanding of how foundation models can improve the accuracy and efficiency of your machine-learning projects, and how to get started using them in your own work.
What are Foundation Models?
Foundation models are pre-trained machine learning models that have been trained on vast amounts of data and can be fine-tuned for specific tasks. These models are trained on huge datasets using deep learning algorithms, making them highly accurate at recognizing patterns and making predictions.
By fine-tuning a foundation model, developers can customize it for their specific use case, saving time and resources compared to building a machine learning model from scratch.
How Foundation Models Work?
Here's how foundation models work:
Pre-training: A foundation model is trained on a large dataset to learn general patterns and features from the data. This pre-training process often requires vast amounts of computational resources and can take weeks or even months.
Fine-tuning: Once a foundation model is pre-trained, it can be fine-tuned for a specific task. Fine-tuning involves training the model on a smaller dataset that is specific to the task at hand. By doing so, the model can learn to make predictions or classify data with high accuracy.
Deployment: Once a foundation model has been fine-tuned, it can be deployed to make predictions on new data. This is done by feeding new data into the model, which then generates a prediction based on the patterns it learned during pre-training and fine-tuning.
Some Popular Foundation Models
There are several popular foundation models available today, including:
- GPT-3 (Generative Pre-trained Transformer 3) by OpenAI: It is a language model that uses deep learning techniques to generate natural language text, with a capacity of up to 175 billion parameters.
- BERT (Bidirectional Encoder Representations from Transformers) by Google: It is a pre-trained language model that uses a bidirectional transformer architecture to understand the context of words in a sentence, with a capacity of up to 340 million parameters.
- RoBERTa (Robustly Optimized BERT Pretraining Approach) by Facebook: It is a refined version of BERT that uses improved pre-training techniques and larger datasets, with a capacity of up to 355 million parameters.
- XLNet by Google and Carnegie Mellon University: It is a language model that uses a permutation-based approach to capture both global and local dependencies in a sentence, with a capacity of up to 340 million parameters.
- T5 (Text-to-Text Transfer Transformer) by Google: It is a language model that uses a unified text-to-text format to perform a variety of natural language tasks, with a capacity of up to 11 billion parameters.
These models have been widely used in various natural languages processing tasks, such as language translation, sentiment analysis, question answering, and text summarization, among others.
How do Foundation Models differ from other AI models?
Foundation models differ from other AI models in several ways. Here are some key differences:
Training data: Foundation models are trained on enormous quantities of unlabeled data, usually through self-supervised learning, while other AI models can be trained on smaller labeled datasets.
Adaptability: Foundation models are designed to be a common basis from which many task-specific models are built via adaptation, while other AI models can be built specifically for a single task.
Transfer learning: Foundation models are built on conventional deep learning and transfer learning algorithms, which allow them to transfer knowledge from one task to another, while other AI models may not have this capability.
Efficiency: Foundation models give rise to new capabilities for efficiently implementing tasks, which can make AI projects easier and cheaper for large enterprise companies to execute.
Scope: Foundation models are massive AI-trained models that use huge amounts of data and computational resources to generate anything from text to images, while other AI models may be designed for more specific tasks.
Overall, foundation models are a new trend in AI that is designed to be more adaptable, efficient, and powerful than other AI models.
How to Use Foundation Models in Your Own Machine-Learning Projects?
Now, let's look at how to use foundation models in your own machine-learning projects:
Foundation models are large, pre-trained deep learning models that have been trained on massive amounts of data and are capable of performing a wide range of natural language processing (NLP) tasks. These models include BERT, GPT, RoBERTa, and others. Using foundation models can save time and resources in developing NLP models from scratch.
Here are the steps to follow to use foundation models in your own machine learning projects:
Step 1: Choose a Foundation Model
Choose a foundation model that is best suited for your project requirements. Each foundation model is trained on a different set of data and has its own unique strengths and weaknesses. For example, BERT is good for tasks that require a deep understanding of context, while GPT-3 is better suited for tasks that require language generation.
Step 2: Install the Necessary Dependencies
Install the necessary packages and dependencies required to use the foundation model in your project. This includes the deep learning framework you're using, such as TensorFlow or PyTorch, and the specific library for the chosen foundation model, such as Hugging Face Transformers or TensorFlow Hub.
Step 3: Load the Pre-Trained Model
Load the pre-trained model into your project. This can be done using the specific library for the chosen foundation model. The pre-trained model should be downloaded and stored on your local machine or server.
Step 4: Fine-tune The Model
Fine-tune the model on your specific dataset to adapt it to your particular task. This involves training the model on your specific data using transfer learning. For example, if you want to use a foundation model for sentiment analysis on customer reviews, you can fine-tune the model by training it on a large corpus of customer reviews.
Step 5: Test the Model
Test the model on a validation dataset to evaluate its performance. This step involves comparing the predicted outputs of the model with the ground truth labels for the data. You can use various evaluation metrics, such as accuracy, precision, recall, and F1 score, to assess the performance of the model.
Step 6: Deploy the Model
Deploy the model in a production environment. This involves creating an API or a web application that can accept user input and generate output using the model. You may also need to optimize the model for performance and scalability in a production environment.
Conclusion
In summary, to use foundation models in your own machine learning projects, you need to choose a model that best suits your requirements, install the necessary dependencies, load the pre-trained model, fine-tune the model on your dataset, test the model's performance, and deploy the model in a production environment.
Check out here to explore more such related blogs!
FAQs
- What are foundation models?
Foundation models are large, pre-trained deep learning models that have been trained on massive amounts of data and are capable of performing a wide range of natural language processing (NLP) tasks.
2. How can foundation models be used in machine learning projects?
Foundation models can be used to save time and resources in developing NLP models from scratch. They can be adapted and fine-tuned for specific project requirements.
3. How to choose a foundation model for my project?
When choosing a foundation model, consider the specific requirements of your project. Each foundation model is trained on a different set of data and has its own unique strengths and weaknesses. For example, BERT is good for tasks that require a deep understanding of context, while GPT-3 is better suited for tasks that require language generation.
4. What are some popular examples of foundation models?
Some popular examples of foundation models include BERT, GPT, RoBERTa, GANs, LLMs, VAEs, and Multimodal. These models have been used to power well-known tools such as ChatGPT, DALLE-2, Segment Anything, and BERT.
5. What are the benefits of using foundation models?
Using foundation models can save time and resources in developing AI models, as they are already pre-trained on massive amounts of data. They also have the potential to make AI projects easier and cheaper for large enterprise companies to execute.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
