

Results Of CLIP's Zero-Shot Performance Over OCR Dataset
CLIP demonstrates potential in zero-shot learning for OCR by classifying text sentiment images with 50% accuracy. Its ability to associate images with text enables it to adapt to unseen concepts, though precision (40%) reveals room for improvement through fine-tuning


Table of Contents
Introduction
The CLIP (Contrastive Language–Image Pre-training) model represents a groundbreaking convergence of natural language understanding and computer vision, allowing it to excel in various tasks involving images and text.
Its foundation is rooted in zero-shot transfer learning, which empowers the model to make accurate predictions on entirely new classes or concepts it has never encountered in its training data.
This innovative approach builds upon earlier explorations in computer vision, where the utilization of natural language as a flexible prediction space facilitated the generalization and transfer of knowledge.
CLIP derives inspiration from pioneering research that harnessed natural language supervision to achieve zero-shot transfer to various computer vision classification datasets. One pivotal element of CLIP's success lies in the scaling of its pre-training task, which taps into the vast reservoir of text-image pairs found on the internet.
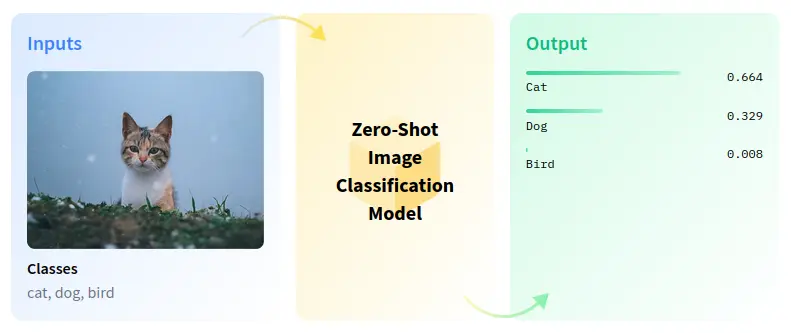
Figure: Zero-shot Classification
By training the model to predict which textual descriptions are associated with given images, CLIP effectively learns to recognize a broad spectrum of visual concepts and associate them with their corresponding textual representations.
This proficiency in zero-shot learning enables CLIP to tackle an extensive range of tasks, from image classification to object detection. Furthermore, CLIP adopts modern deep learning architectures, particularly Transformers, to intricately model the intricate relationships between images and text.
As part of a broader movement revisiting the learning of visual representations through natural language supervision, CLIP stands out as a remarkable achievement, effectively bridging the chasm between natural language and computer vision.
Its ability to associate images with textual descriptions during pre-training empowers it to excel in tasks requiring generalization to unseen classes or concepts, positioning it as a pivotal advancement in the realm of multimodal AI.
In this blog, we aim to analyze the zero-shot abilities of the CLIP Model over both kinds of datasets, which include:
- Open-source
- Custom Made
In this work, we use the Rendered SS2 Dataset (OCR Semantic Classification) image dataset, which includes images of text, over a white background. The aim here is to classify whether the text is positive or negative.
About Datasets
Before moving on to the CLIP Model analysis, we look at the datasets used.
Rendered SST2 OCR Dataset
The Rendered SST2 dataset, publicly disclosed by OpenAI, evaluates visual models' optical character recognition performance. It transforms sentences sourced from the Stanford Sentiment Treebank dataset into images, presenting them in a 448×448 resolution format with black text on a white background.

Figure: OCR Dataset Used in Tutorial
The dataset comprises two categories, namely positive and negative, and has been partitioned into three subsets.
The training subset consists of 6920 images, with 3610 falling under the positive category and 3310 under the negative category.
The validation subset contains 872 images, with 444 categorized as positive and 428 as negative. Lastly, the test subset encompasses 1821 images, with 909 labeled as positive and 912 as negative.
Hands-on With Code
For trying out the code below for analyzing the zero-shot capability of the CLIP Model, below are some prerequisites you should be familiar with.
Pre-Requisites
To proceed further, one should be familiar with:
- Python: All the below code will be written using Python.
- Pytorch: PyTorch, founded on the Torch library, is a machine learning framework utilized for tasks like computer vision and natural language processing.
- Google Colaboratory: Colab is a cost-free Jupyter Notebook environment that operates exclusively within the cloud.
Tutorial
The template for running inference would be similar in all the 3 dataset cases, just the dataset would change.
We begin by loading the required libraries.
import os
import clip
import torch
import matplotlib.pyplot as pltLoading the Model, in GPU or CPU
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)Download the required Dataset.
from torchvision.datasets import RenderedSST2
data = RenderedSST2(root=os.path.expanduser("~/.cache"), download=True)Next, we prepare the input data.
# Prepare the inputs. Evaluating on 2500th example.
image, class_id = data[250]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in data.classes]).to(device)Next we calculate the input features, i.e. encode these via CLIP Model.
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)So, now we compute the similarity between the image features and text features and pick the top 5 labels that match the input images.
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(2)Finally, we print our results and plot them for visualization.
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{data.classes[index]:>16s}: {100 * value.item():.2f}%")
plt.imshow(image)
plt.title(f"Image for class: {data.classes[class_id]}")
plt.axis('off')
plt.show()Output
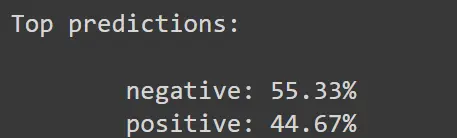
Figure: Model Probability Prediction

Figure: Image with True Class Negative
Above, we see that CLIP correctly classifies the provided image as input. However, the probability for both classes is approximately the same. This can be tuned by fine-tuning CLIP mode, which we aim to to in the next blog.
We run the above inference over multiple images and below, we can see:
Figure: Inference Images on Dataset using CLIP
From the above figure, the accuracy of CLIP on the OCR Dataset is about 50%, as it classified 3/6 instances correctly.
Further analysis shows that the precision in the above case is ⅖, which is about 40%.
Precision tells us how good the results are, while recall tells us how many of the relevant results were found. If precision is high, it means most of the results are correct, and if recall is high, it means we found most of the relevant results
Conclusion
In this analysis, we explored the zero-shot capabilities of the CLIP (Contrastive Language–-image pre-training) model using the Rendered SST2 dataset, which evaluates optical character recognition (OCR) performance for visual models.
The dataset consists of sentences transformed into images, categorized as positive or negative sentiment.
CLIP's foundation in zero-shot transfer learning allows it to make accurate predictions on entirely new classes or concepts it hasn't encountered during training.
It bridges the gap between natural language understanding and computer vision by associating images with textual descriptions during pre-training.
Using CLIP, we aimed to classify images of texts from the Rendered SST2 dataset. The model demonstrated a 50% accuracy on this dataset, correctly classifying 3 out of 6 instances.
Further analysis revealed a precision of 40%, indicating that 2 out of the 5 predictions were correct. Precision measures result in quality, while recall assesses how many relevant results were found.
In conclusion, CLIP showed promise in this zero-shot task, but there is room for improvement, particularly in terms of precision. This analysis highlights the versatility of CLIP and its potential for various multimodal AI applications, showcasing its adaptability to new datasets and tasks.
Further refinements and fine-tuning may lead to even better results in OCR and other visual recognition tasks. In the next blog, we aim to fine-tune the clip using this dataset and will try to increase the precision of the model.
Frequently Asked Questions (FAQ)
1. What is OpenAI's CLIP?
Well CLIP, which stands for Contrastive Language-Image Pre-training, is a system that acquires visual knowledge through guidance from natural language. In traditional supervised computer vision setups, models are trained or fine-tuned using a predefined set of labels.
However, this approach imposes a constraint on the model because it needs to be retrained whenever it encounters new labels, limiting its adaptability and scalability.
2. Which CLIP model stands out as the top performer?
The H/14 variant has achieved an impressive 78.0% zero-shot top-1 accuracy on the ImageNet dataset and an impressive 73.4% on zero-shot image retrieval at Recall@5 on MS COCO. As of September 2022, it holds the distinction of being the finest open-source CLIP model available.
These CLIP models undergo self-supervised training on an extensive dataset of hundreds of millions or billions of (image, text) pairs.
3. What is OCR?
OCR stands for Optical Character Recognition. It is a technology that is used to convert printed or handwritten text and images into machine-readable text.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
