

Best approaches for data labeling work in computer vision projects

A machine learning project's quality ultimately depends on how you handle three crucial aspects: data collection, data preparation, and data labeling work.
Labeling, commonly referred to as data annotation, is frequently labor-intensive and complicated. For instance, bounding boxes surrounding certain objects are frequently needed for picture identification systems, and sophisticated cultural knowledge may be needed for sentiment analysis and product recommendation systems. Additionally, keep in mind that a data set may include a large number of samples that require labeling, if not more.
Given this, choosing the best strategy for machine learning projects requires taking the task's complexity, project size, and timetable into account. We've included a few typical techniques of data labeling along with advantages and disadvantages for each in light of these criteria. But before getting into that, you first need to know about what data labeling work is.
What is Data labeling work?
Data labeling in machines is the method of classifying unlabeled data (such as images, text files, videos, etc.) and giving one or more insightful labels to give the data structure so that a machine-learning model may learn from it. For example with the help of a Label, we can identify if a photograph shows a bird or an automobile, or in any audio which words were used/ spoken, or whether a tumor is visible on an x-ray. For several use cases, such as natural language processing, computer vision, and audio processing, data labeling is necessary.
Types of data labeling
There are types of data labeling. Here are some instances of the most typical types since every data form has a distinct labeling process:
1. Text annotation
The technique of categorizing phrases or paragraphs in a document according to the topic is known as text annotation. This material can be anything, from customer reviews to product feedback on e-commerce sites, from social network mention to email messages. Text annotation offers several opportunities to extract relevant information from texts because they clearly express intents. Because machines don't understand concepts and feelings like humor, sarcasm, rage, and other abstract concepts, text annotation is a complicated process with many steps.
2. Image annotation
Annotating an image makes sure that a machine will recognize the annotated region as a different object. These models receive captions, IDs, and keywords as attributes when they are trained. The algorithms then recognize and comprehend these factors and develop their internal knowledge. To be employed in a variety of AI-based technologies like face detection, computer vision, robotics vision, and autonomous vehicles, among others, it typically includes the usage of bounding boxes or semantic segmentation.
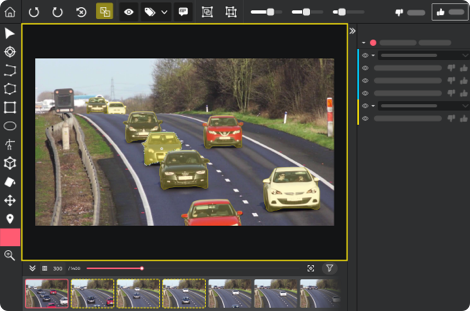
3. Video annotation
Similar to image annotation, video annotation makes use of tools like bounding boxes to identify motion frame-by-frame. For computer vision algorithms that carry out object location and tracking, the information gathered through video annotation is crucial. The systems can easily incorporate ideas like location, image noise, and detection and tracking thanks to video annotation.
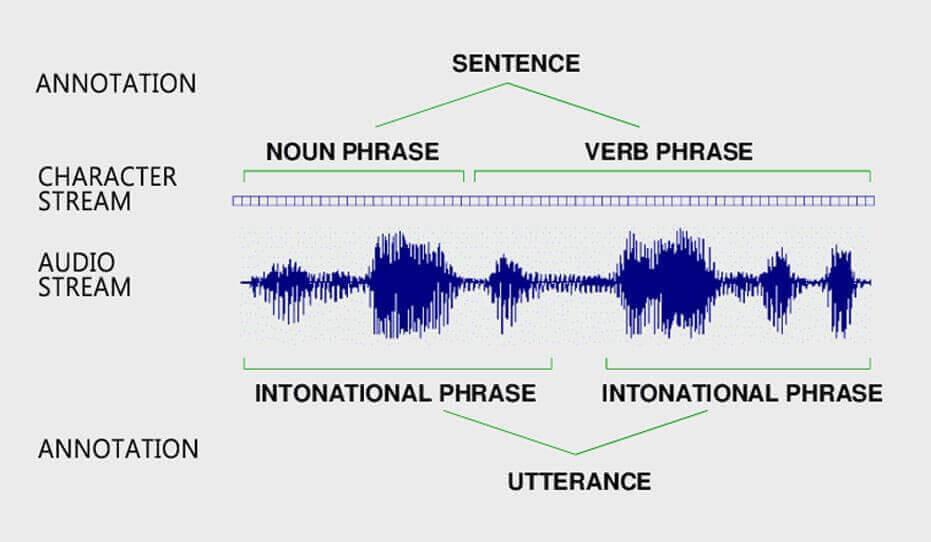
4. Audio Annotation
All types of sounds, including speech, animal noises (growls, whistling, or chirps), and construction noises (breaking glass, scanners, or alarms), are transformed into structured formats during audio processing so they can be employed in machine learning. It is frequently necessary to manually convert audio files into text before processing them. The audio can then be tagged and categorized to reveal more details about it. Your training dataset is this audio that has been categorized.
5. Key-point Annotation
With key-point annotation, dots are added to the image and connected by edges. You receive the x and y-axis coordinates of important locations that are labeled in a specific order at the output. The method finds little objects and forms variations that share the same composition (e.g., facial expressions and features, parts of the human body and poses).

Approaches to data labeling
There are numerous approaches to accomplishing data labeling work. A company's ability to dedicate the necessary time and money for a project relies on the difficulty of the issue and training data set, the size of the data science team and the choice of approach.
1. In-house
Within an organization, specialists perform in-house data labeling work, which guarantees the best possible level of labeling.
When you have sufficient time, human, and financial resources, it's the best option because it offers the highest level of labeling accuracy. On the other hand, it moves slowly.
For sectors like finance or healthcare, high-quality labeling is essential, and it frequently necessitates meetings with specialists in related professions.
The strategy's benefits
Good results that can be predicted and process control. You're not getting a pig in a poke if you depend on the community. Because they will be dealing with a labeled data set, data scientists and other inside experts are motivated to perform well. To ensure that your team adheres to a project's deadline, you can also monitor its performance.
Negative aspects of this strategy
It takes a while. The labeling process requires more time the higher the labeling quality. To categorize data correctly, the data experts will require more time, and time is typically a scarce resource.
2. Outsourcing
For building a team to manage a project beyond a predetermined time frame, outsourcing is a smart choice. You can direct candidates to your project by promoting it on job boards or your business's social media pages. Following that, the testing and interviewing procedure will guarantee that only people with the required skill set join your labeling team. This is a fantastic approach to assembling a temporary workforce, but it also necessitates some planning and coordination because your new employees might need the training to be proficient at their new roles and carry them out according to your specifications.
The strategy's benefits
You are the one who hires. Tests can be used to determine whether applicants have the necessary abilities for the position. Since employing a small or moderate staff is required for outsourcing, you will have the chance to oversee their work.
Negative aspects of the strategy
You must create a workflow. A task template needs to be made, and it needs to be user-friendly. For example, you might use a tool, which offers an interface for labeling tasks, if you have any visual data. When several labels are necessary, this service enables the construction of tasks. To guarantee data security within a local network, developers advise utilizing a tool.
Provide an outsourced professional with a labeling tool of your choice if you don't want to design your own task interface.
Writing thorough and understandable directions is another duty of yours if you want outsourced workers to follow them and annotate appropriately. In addition, you'll need more time to complete and review the finished jobs.

3. Crowdsourcing
The method of gathering annotated data with the aid of a sizable number of independent contractors enrolled at the crowdsourcing platform is known as crowdsourcing.
The datasets that have been annotated are primarily made up of unimportant information like pictures of flora, animals, and the surroundings. Therefore, platforms with a large number of enrolled data annotators are frequently used to crowdsource the work of annotating a basic data set.
The strategy's benefits
-Provides rapid outcomes- For tasks requiring the use of robust labeling technologies and big, simple datasets with short deadlines, crowdsourcing is a viable choice. For example, categorizing photographs of vehicles for computer vision tasks won't take long and can be completed by personnel with common knowledge, not specialized knowledge. Efficiency can also be gained by breaking down projects into smaller jobs that independent contractors can complete at once.
-Affordability-You won't spend a fortune assigning labeling assignments on these sites. Employers have a variety of options thanks to services like Amazon Mechanical Turk, which permits setting up rewards for each assignment. For instance, you could identify 2,000 photographs for $100 by offering a $0.05 bonus for every HIT and just requiring one submission per item. Given a 20% price for HITs with a maximum of nine assignments, the total cost for a small data set would be $120.
Negative aspects of this strategy
Crowdsourcing has various drawbacks, the biggest one being the possibility of receiving a data set of poor quality, even while it might help you save time and money by asking others to label the data.
Inconsistent labeling of data of poor quality- People who depend on the number of tasks they do each day for their daily pay may disregard task recommendations in an effort to finish as much work as feasible. A linguistic barrier or a division of labor can occasionally cause errors in annotations.
Platforms for crowdsourcing employ quality control procedures to address this issue and ensure that their employees will deliver the highest quality work. Online marketplaces do this by verifying skills through training and testing, keeping track of reputation ratings, offering statistics, peer evaluations, audits, and in advance outlining the desired results. Additionally, clients can ask several individuals to work on a particular project and then review it before paying.
As an employer, it is your responsibility to ensure everything is in order. The platform reps advise using brief queries and bullet points, showing samples of well- and poorly-done activities, and providing clear and concise work instructions. You can include examples for each of the criteria you establish if your labeling activity involves drawing boundary boxes.
4. Synthetic data generation
The synthesis or generation of fresh data with the properties required for your project is known as synthetic labeling. Generative adversarial networks are one technique for synthetic labeling (GANs). A GAN integrates various neural networks (a discriminator and a generator) that compete to discriminate between real and false data and produce fake data, respectively. As a result, the new facts are very realistic. You can generate brand-new data from already existing datasets using GANs and other synthetic labeling techniques. They are hence good at creating high-quality data and are time-effective. Synthetic labeling techniques, however, currently demand a lot of computational power, which can render them quite expensive.
Confused on Synthetic data vs real data: which is a better option?: Read here
The strategy's benefits
-Cost and time savings-This method speeds up and reduces the cost of labeling. It is simple to create unique synthetic data that is tailored for a particular purpose and may be altered to enhance both model training and the model itself.
-Utilizing non-sensitive data-To use such data, data scientists are not required to obtain authorization.
Negative aspects of the strategy
The demand for powerful computing. For graphics and additional model training, this method needs powerful computing. Renting cloud servers from platforms like Amazon Web Services (AWS), Google's Cloud Platform, Microsoft Azure, IBM Cloud, Oracle, or others is one of the choices. On decentralized platforms like SONM, you can take a different route and obtain more computational resources.
data integrity problems. Real historical data could not exactly resemble synthetic data. A model developed using these data may therefore need to be improved further by being trained using actual data as it becomes available.
How Labellerr can help you?
Labellerr offers a smart feedback loop that automates the processes that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities. By choosing us, you can reduce the dependency on industry experts as we provide advanced technology that helps to fasten processes with accurate results.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers if any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from advertisements—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
If you want to know more such related information, then connect with labellerr.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
