

ImageBind by Meta - A Single Embedding Space by Binding Content With Images


It's no longer sufficient to merely observe an image in a world where visual content predominates. What if we told you that there is a technology that could let you actually convert one form of data into another?
Then there is ImageBind by Meta, a ground-breaking advancement in sensory binding that combines the tactile and visual, revolutionizing how we engage with images.
Imagebind has demonstrated that now you do not need combinations of paired data to train such a joint embedding, instead only image-paired data is sufficient to link the modalities together.
With this, meta is giving you a completely new kind of immersive visual or tactile experience. ImageBind by Meta will help you elevate your visual experiences.
What is ImageBind by Meta?
{kind=link}
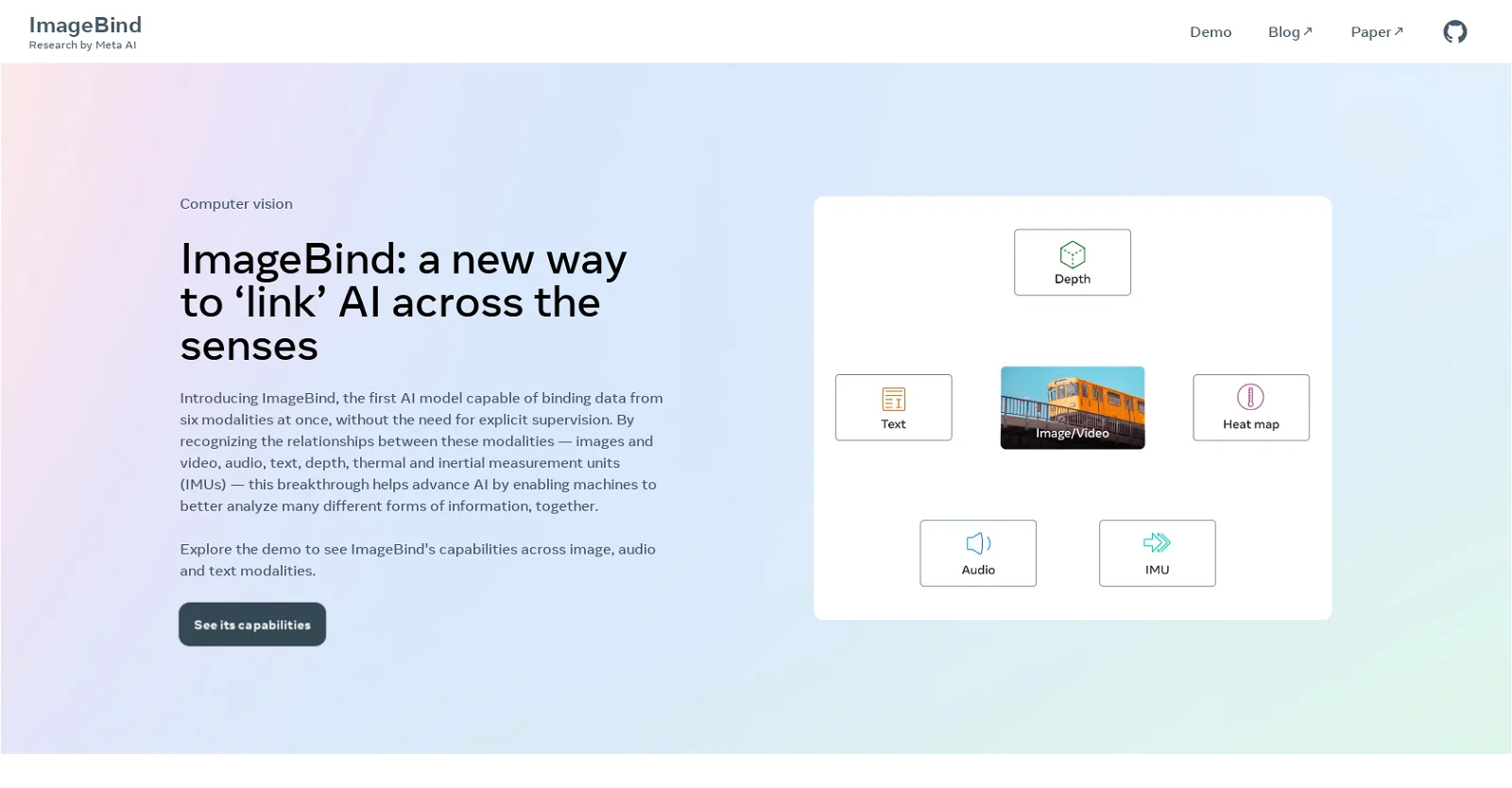
Developed by Meta, ImageBind is an AI tool that can forecast relationships between data from six distinct modalities, including text, images/videos, audio, 3D measurements, temperature data, and motion data. It is the first AI model to learn a single embedding space that connects various sensory inputs without explicit supervision, and it is capable of binding data from six modalities simultaneously.
People with vision or hearing impairments can better understand their immediate environs with the aid of ImageBind, an early version of a framework that provides real-time multimedia descriptions. Although ImageBind is only a research project, it has the potential to be used in a variety of fields in the future.
How does ImageBind differ from other AI models?
In contrast to existing AI models, ImageBind is the first AI model to be able to bind data from six different modalities simultaneously, including text, images/videos, audio, 3D measurements, temperature data, and motion data.
It can outperform earlier specialized models trained separately for each sensory modality since it learns a single embedding space that unifies many inputs without explicit supervision.
Machines are given a holistic knowledge by ImageBind that relates the sound that an object will make, its 3D shape, its temperature, and its motion. Using ImageBind, other models can "understand" new modalities without needing a lot of time and effort to train them.
When applied for few-shot audio and depth classification tasks, ImageBind features can perform better than earlier techniques designed specifically for those modalities.
With improvements of almost 40% in top-1 accuracy on "few-shot classification," ImageBind, for instance, greatly beats Meta's self-supervised AudioMAE model trained on Audioset and a supervised AudioMAE model fine-tuned on audio classification.
Additionally, ImageBind outperformed recent models that were taught to recognize ideas for that modality in emergent zero-shot identification tests across modalities, setting new benchmarks for performance.
The technology behind Meta’s ImageBind
People can advance new ideas from a couple of models. Typically, we can identify an animal in real life after reading its description. From a picture of the vehicle, we can also imagine the engine noise of a new model. This is partially due to the fact that a single image has the ability to "bind" an entire sensory experience.
In the field of AI, however, as the number of modalities increases, the lack of multiple sensory data can limit standard multimodal learning, which relies on paired data. Ideally, a model could learn visual features in addition to those from other modalities using a single joint embedding space, which is where many different types of data are distributed.
In the past, collecting all possible paired data combinations to learn such a joint embedding space for all modalities was impossible.
By using recent large-scale vision-language models and extending their zero-shot capabilities to new modalities simply by using their natural pairing with images, like video-audio and image-depth data, to learn a single joint embedding space, ImageBind was able to circumvent this obstacle.
We make use of naturally paired self-supervised data for the four additional modalities—IMU readings, depth readings, thermal readings, and audio.
With the abundance of images and related text on the internet, extensive research has been conducted on training image-text models. ImageBind makes use of images' binding properties, which means that they co-occur with a variety of modalities and can act as a bridge to connect them.
For instance, it can link text to the image using data from the web or motion to video using video data from IMU-equipped wearable cameras.
The visual portrayals gained from the enormous scope of web information can be utilized as focuses to learn highlights for various modalities. ImageBind is able to naturally align any modalities that co-occur with images thanks to this feature.
Aligning modalities like thermal and depth that have a strong connection to images is easier. Modalities that are not visual, like sound and IMU, have a more vulnerable relationship. Take into consideration that certain sounds, such as a baby's cries, may accompany any number of visual contexts.
ImageBind demonstrates that these six modalities can be linked together with just image-paired data. The model can decipher content more comprehensively, permitting the various modalities to "talk" to one another and track down joins without noticing them together.
ImageBind, for instance, can connect audio and text without seeing them together. This empowers different models to "figure out" new modalities with practically no asset serious preparation.
Due to ImageBind's strong scaling behavior, the model can use other modalities to replace or improve numerous AI models. For example, while a text-to-image tool can produce images by utilizing text prompts, ImageBind could redesign it to create images utilizing sound sounds, like chuckling or downpour.
Explore PaLM: 540B Parameter Language Model Breakthrough
Features of ImageBind
An open-source AI model called ImageBind was created by Meta and has the ability to interact with six various sources of data, including text, audio, video, 3D, thermal, and motion.
It can align any other modality that regularly coexists with images by learning a single shared representation space using various types of image-pair data.
ImageBind does this without the use of explicit supervision by learning a single embedding space that connects various sensory inputs.
By allowing the various modalities to "talk" to one another and make connections without direct observation, it can offer a more comprehensive interpretation of the data. The visual capabilities of DINOv2 could be used by ImageBind in the future to enhance its functionality.
How does ImageBind handle data modalities that are not included in the six supported types?
ImageBind develops a common language for various data kinds without the need for examples that include every data type, which would be expensive or impossible to acquire. It builds associations between them and recognizes the information that is there in the data.
By learning from the organic relationships between different data types without the use of explicit markers, ImageBind can integrate four more modalities (audio, depth, thermal, and IMU) by using picture data as a bridge between them. ImageBind is intended to function with six various types of data, including text, audio, video, 3D, thermal, and motion.
However, it may be able to accommodate additional data modalities by identifying the information present in the data and creating connections between it.
How Image Sensory Binding is going to change the Computer Vision Industry?
Image Sensory Binding, as determined by ImageBind, is a revolutionary advancement in the fields of artificial intelligence and computer vision.
In addition to learning a single shared representation space for six different modalities, including text, audio, video, 3D, thermal, and motion, it enables machines to learn from many modalities at once. ImageBind gives machines a complete understanding of items in a photo by connecting them to their 3D shape, sound, temperature, and movement.
With this innovation, machines are one step closer to matching human ability to combine data from numerous senses. Future versions of ImageBind might make use of the visual aspects of other AI tools to enhance their functionality. Applications for ImageBind include enhancing search functionality for images, videos, audio files, and text messages by combining text, audio, and images.
Summing it Up
To sum up, ImageBind by Meta is a ground-breaking innovation that expands the possibilities of conventional visual information by combining tactile feedback to produce a more immersive and compelling experience. Image Sensory Binding has the ability to transform how we connect with images and improve their emotional impact and all-around engagement by fusing the visual and tactile senses.
Users can actually experience images in three dimensions with ImageBind, fusing the real and virtual worlds together. We may anticipate that Image Sensory Binding will have a substantial impact on a number of industries and alter how we perceive visual content as technology progresses.
Read more such informative content here and gain some more insights!
FAQs
- What is ImageBind by Meta?
ImageBind by Meta is an AI product that can predict connections between data from six different modalities, including text, images, audio, depth, temperature, and IMU data.
2. What function does ImageBind by Meta serve?
By integrating tactile feedback, ImageBind by Meta aims to increase the potential of traditional visual information and provide a more engaging and immersive experience.
3. What is the operation of ImageBind by Meta?
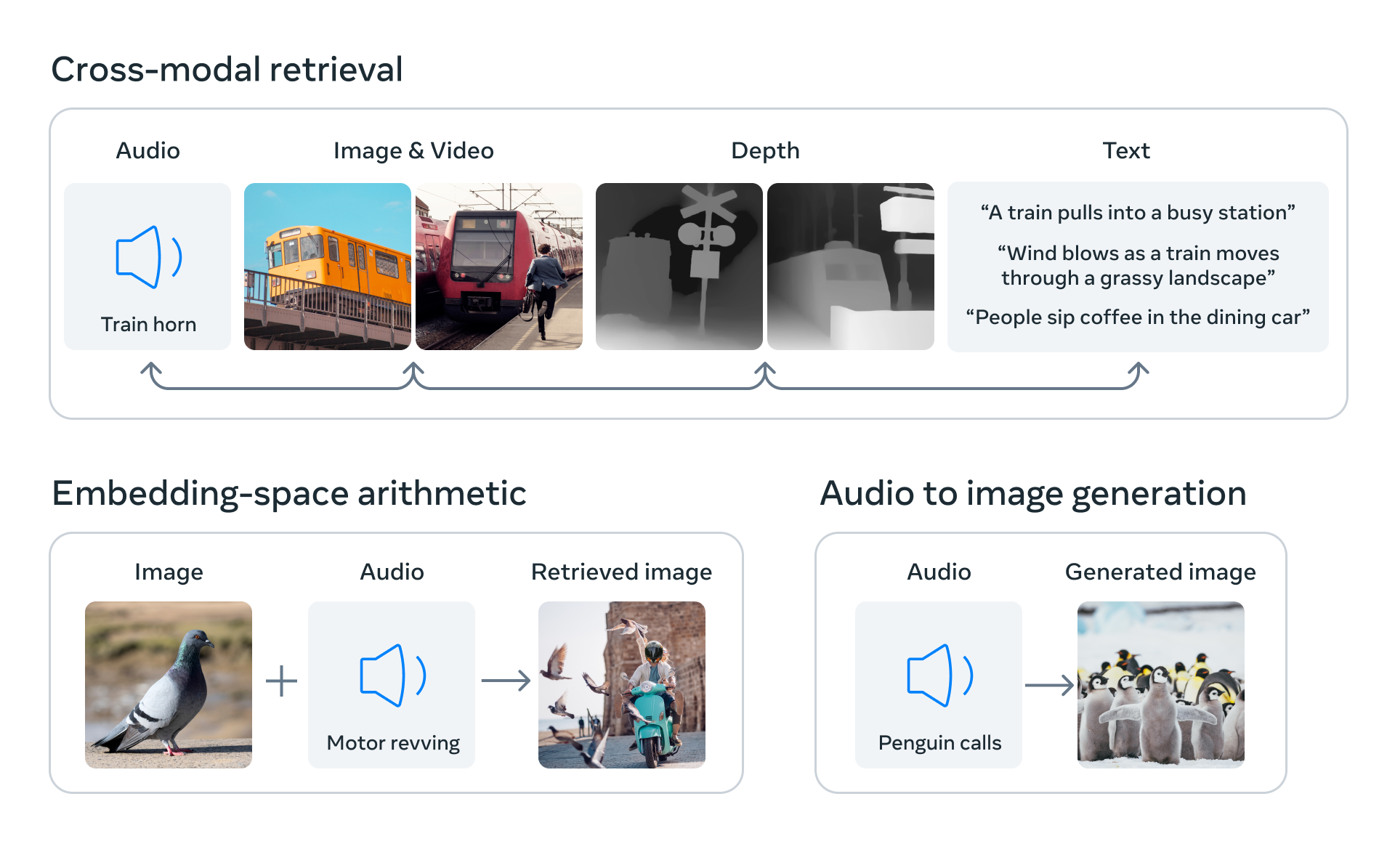
To enable unique emergent applications including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and cross-modal production, ImageBind by Meta learns a joint embedding across six different modalities.
4. What are the advantages of using ImageBind by Meta?
With ImageBind by Meta, you can transform one type of data into another to create a new sort of immersive visual or tactile experience. Additionally, just image-paired data is required to connect the modalities; combinations of paired data are no longer necessary to train a joint embedding.
5. What are a few possible uses for ImageBind by Meta?
Cross-modal retrieval, combining modalities with math, cross-modal detection, and cross-modal production are all possible with ImageBind by Meta. It can also be utilized to create brand-new AI applications that need to incorporate a variety of modalities.
6. Is Meta's ImageBind open source?
Yes, ImageBind by Meta is a Meta AI Research's open-source project.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
