

Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance

Natural language processing has been revolutionized by language models, which enable machines to comprehend and produce human-like prose on a previously unheard-of scale. The Pathways Language Model (PaLM), which has scaled up to an astounding 540 billion parameters, represents the most recent innovation in this sector.
PaLM is now one of the most potent language models ever made thanks to this amazing achievement, which has elevated it to new levels of performance. We'll go into PaLM's amazing capabilities in this blog and examine how this innovation is revolutionizing the study of natural language processing.
What is Pathways Language Model (PaLM)?
Pathways Language Model (PaLM) is a language model created by Google that has been trained using the Pathways method. It is extremely effective and can generalize tasks across a variety of domains and tasks.
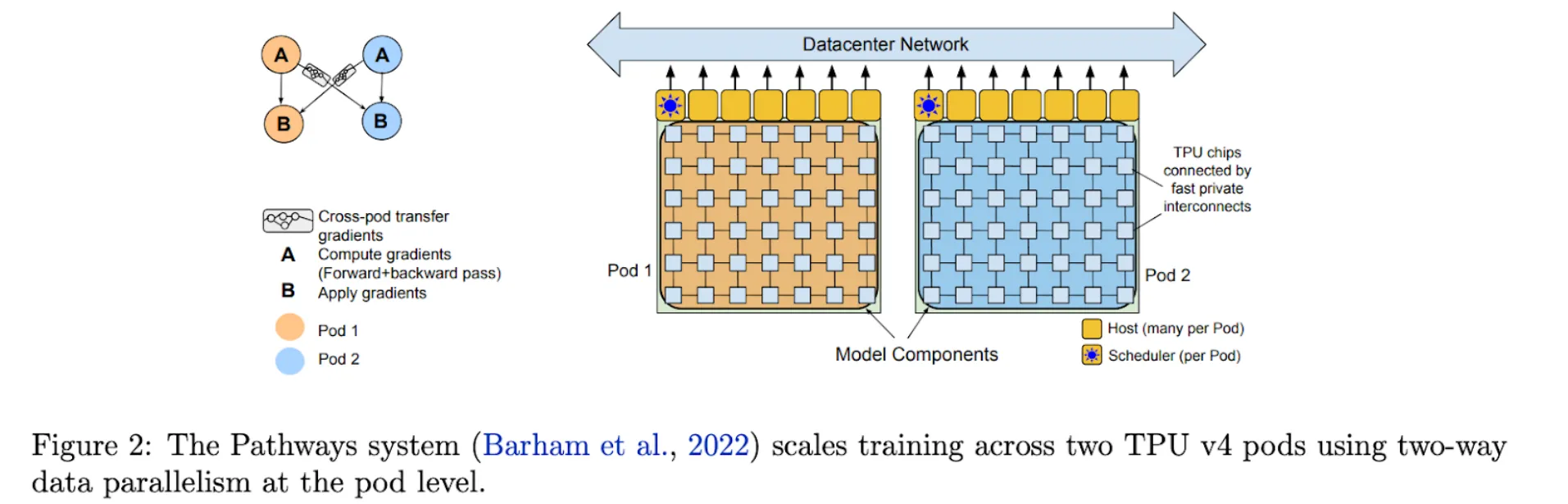
Pathways, a new ML approach that enables very effective training across several TPU Pods, was used to train PaLM, a 540 billion parameter model, on 6144 TPU v4 chips.
PaLM, in contrast to standard AI models, which are normally taught to perform only one task, allows training a single model to perform several tasks. This is why it is considered a significant improvement in artificial intelligence (AI). PaLM is a component of Google's Pathways AI architecture.
Significance of PaLM
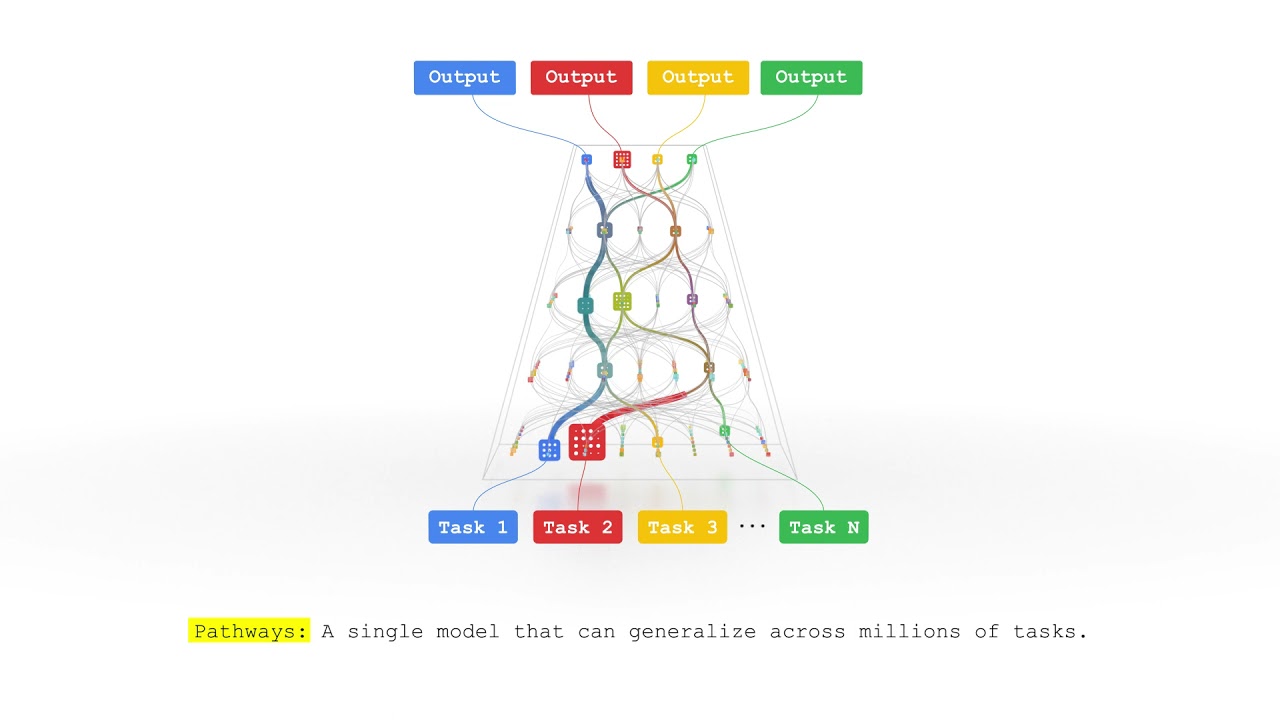
PaLM's capacity to train language models across numerous TPU Pods with high efficiency while utilizing the Pathways system is what makes its efficiency so important. As a result, PaLM may be trained more quickly and effectively than conventional AI models, which is a major development in artificial intelligence.
Unlike traditional AI models, which are normally trained to perform only one task, PaLM's efficiency allows for the training of a single model to perform several tasks.
Features of PaLM
PaLM (Pathways Language Model) is a dense decoder-only Transformer model with 540 billion parameters that were learned using the Pathways system. On various Big-bench tests, such as differentiating between cause and effect, comprehending conceptual combinations in appropriate settings, and figuring out the movie from an emoji, PaLM has shown outstanding natural language understanding and creation capabilities.
PaLM excelled at a variety of NLP tasks, including textual entailment, reading comprehension, and long-form question answering. PaLM employs a decoder-only configuration with a typical Transformer model architecture, which means that each timestep can only be used to decode prior timesteps.
PaLM is a component of Google's Pathways AI architecture, which allows training a single model to perform thousands or millions of tasks, as opposed to standard AI models, which are normally trained to perform just one task.
To understand the architecture of PaLM, you first need to get familiar with the Transformer model architecture. So, let’s explore it.
What is Standard Transformer Model architecture?
Vaswani et al.'s 2017 paper unveiled the Transformer model architecture, a neural network design. It has evolved into the foundation of numerous cutting-edge natural languages processing models, such as BERT and GPT.
An encoder and a decoder make up the basic architecture of the Transformer model. The input sequence is processed by the encoder, which creates a sequence of hidden representations. The hidden representations are then used by the decoder to create the output sequence.
An identical stack of layers makes up both the encoder and decoder. A position-wise completely connected feedforward network and a multi-head self-attention mechanism are the two sub-layers that make up each layer. The feedforward network performs a non-linear change to each location in the sequence separately, whilst the self-attention mechanism allows the model to attend to different regions of the input sequence while processing each token.
Each sub-layer is followed by the application of residual connections and layer normalization, and the output of the encoder is fed into the decoder using an attention mechanism that enables the decoder to concentrate on pertinent portions of the input sequence.
Overall, the field of natural language processing has evolved greatly thanks to the Transformer model architecture's ability to capture long-range dependencies in natural language data.
Limitations of PaLM
However, like any other large language model, PaLM performs better as it scales up and can simultaneously interpret several sorts of data, including text, images, and speech.
Instead of engaging the whole neural network for all tasks, PaLM has been taught to be "sparsely activated" for tasks of all complexity levels. A thorough examination of LM restrictions in the medical field is mentioned in one piece, however, it is unclear how this precisely applies to PaLM.
Overall, it appears that PaLM is a highly effective and powerful language model with the potential for a wide range of real-world AI applications. It has achieved state-of-the-art performance on numerous NLP tasks.
Conclusion
In conclusion, the Pathways Language Model (PaLM), one of the most potent language models ever constructed, offers a breakthrough in natural language processing by scaling up to a mind-boggling 540 billion parameters.
The immense potential of large-scale language models to revolutionize the field of natural language processing is demonstrated by their excellent performance on a variety of language tasks. With PaLM, we have improved language comprehension to new levels, opening the door for future developments in AI and machine learning.
Explore more such related blogs to gain more insights!
FAQs
1. What is PaLM?
PaLM, a sizable language model created by Google, is one of the large language models in the world with 540 billion parameters.
2. What are the PaLM usage cases?
PaLM has several applications, such as language production and comprehension, coding activities, security, and providing medical information.
3. What are PaLM's limitations?
The commercial usage for PaLM, a model that Google created and released, is unclear. PaLM is a proprietary model and not an open-source project, meaning outside developers cannot contribute new code or aid in its development. The possibility of toxic content—content that can be seen as being biassed, malevolent, or detrimental to users has been noted by Google researchers as a major weakness of PaLM.
4. How does PaLM 2 differ from the first version?
In comparison to PaLM 1, PaLM 2's pre-training ingested a larger variety of data, such as scientific publications, web pages, and mathematical expressions. As a consequence, PaLM 2 exhibits enhanced logic, arithmetic, and common sense thinking skills. PaLM 2 outperforms earlier models in terms of speed and effectiveness.
5. How can external developers use PaLM through API, Firebase, and Colab?
To leverage PaLM using these APIs, Firebase, and Colab, Developers must download and install the Google-generative Python package and authenticate access to the platform. PaLM API on Vertex AI is a more generic platform for developing AI applications, whereas PaLM API on Firebase Extensions and PaLM API on Colab offer distinct features, such as chatbot and linguistic tasks.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
