

Claude Opus 4.8 Crushes Coding Benchmarks
Claude Opus 4.8 delivers stronger coding performance, improved honesty, Dynamic Workflows, and lower Fast Mode costs. Discover how it compares to Opus 4.7, the benchmark gains that matter, and whether upgrading is the right move for your team.


Most model upgrades promise a revolution. Opus 4.8 does not. Anthropic shipped it on May 28, 2026, just 41 days after Opus 4.7, and called it "a modest but tangible improvement." That honesty is itself a signal.
What you get is a model that codes better, lies less, costs the same, and runs parallel agents at a scale the previous version could not touch. This post breaks down every real difference between 4.7 and 4.8, with verified benchmark numbers and zero filler.
What Changed Under the Hood
Opus 4.8 is a point release inside the Opus 4.5 family lineage: 4.5 (Nov 2025) → 4.6 (Feb 2026) → 4.7 (Apr 2026) → 4.8 (May 2026). The API model string is claude-opus-4-8, available immediately across the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
The same 1M-token context window carries over. Pricing is flat, $5 per million input tokens and $25 per million output tokens. The only cost shift is in fast mode, which gets dramatically cheaper (more on that below).
The three core improvements are: sharper agentic coding, a major honesty upgrade, and near-Mythos alignment scores. Each one connects to the next.
Benchmark Comparison: 4.7 vs 4.8
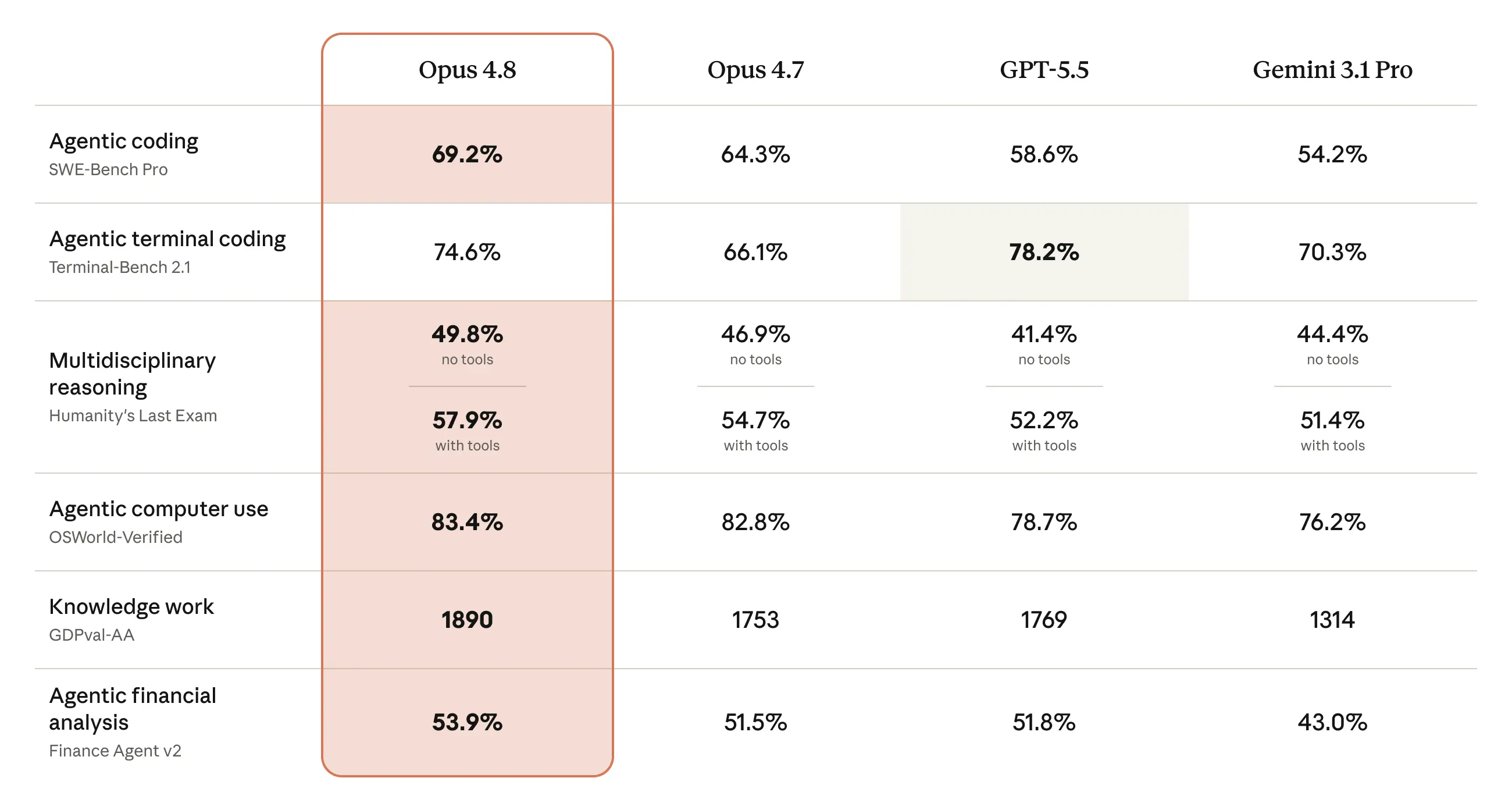
benchmark comparison table
Coding (SWE-bench Pro) Opus 4.8 lands at 69.2% on SWE-bench Pro, nearly 5 points ahead of Opus 4.7 (64.3%) and over 10 points clear of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%). SWE-bench Pro uses problems from actively maintained repositories with multi-file diffs and no public ground-truth leakage. It resists memorization. A 5-point gain here is real.
Coding (SWE-bench Verified) Opus 4.8 scores 88.6% on SWE-bench Verified, up from 87.6% for Opus 4.7. A smaller jump on the easier benchmark, which is expected when a model is already near the ceiling.
Terminal/CLI Tasks Opus 4.8 scores 74.6% on Terminal-Bench 2.1, up from 66.1% for Opus 4.7. GPT-5.5 still leads on this specific benchmark at 83.4%, but with an important caveat: GPT-5.5's Terminal-Bench score uses the Codex CLI harness, not the standard Terminus-2 harness used for all other models. That comparison is not apples-to-apples.
Computer Use (OSWorld-Verified) Opus 4.8 scores 83.4% on OSWorld-Verified, leading the comparison set and making it the strongest computer-use model on the market as of this release. Browserbase's team confirmed Opus 4.8 scoring 84% on Online-Mind2Web, a meaningful jump over both Opus 4.7 and GPT-5.5.
Knowledge Work (GDPval-AA) Opus 4.8 scores 1890 on the GDPval-AA knowledge-work evaluation, a clean lead over GPT-5.5 (1769) and a wide gap over Gemini 3.1 Pro (1314).
Reasoning (GPQA Diamond) This is the one regression worth noting. Opus 4.8 scores 93.6% on GPQA Diamond, slightly below Opus 4.7 (94.2%). This is a near-saturated benchmark. At this level, variance is expected and the gap is not operationally meaningful.
Mathematical Reasoning (USAMO 2026) Opus 4.8 posts 96.7% on USAMO 2026 against 69.3% for Opus 4.7, the single largest jump across any benchmark in this release cycle.
The Honesty Upgrade: Why It Matters More Than Any Benchmark
This is where 4.8 separates from 4.7 in practice, not just on paper.
One of the most prominent improvements in Opus 4.8 is its honesty. Opus 4.8 is more likely to flag uncertainties about its work and less likely to make unsupported claims. Evaluations show that Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.
For any team running Opus inside an agentic loop, code review, automated QA, multi-step reasoning chains, this is the number that changes production behavior. A model that flags its own errors costs you less in downstream debugging. It also means less human oversight at review time.
Anthropic's Alignment team reported that Opus 4.8 "reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user's best interest." Rates of misaligned behavior, such as deception, came in well below Opus 4.7 and close to the company's best-aligned model so far, Claude Mythos Preview.
One important trade-off: Agentic prompt-injection robustness is somewhat less robust than Opus 4.7, with Gray Swan agent red-teaming showing a ~9.6% attack-success-rate versus 6.0% for Opus 4.7. Teams running Opus 4.8 in agentic pipelines with untrusted input should review their sandboxing before deploying.
Dynamic Workflows: The Architecture Shift
Video Source
This is the biggest architectural change in the 4.8 release, and it does not run on the model alone.
Dynamic workflows allows Claude to plan the work and then run hundreds of parallel subagents in a single session. It then verifies its outputs before reporting back to the user. Claude Code with Opus 4.8 can now carry out codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, with the existing test suite as its bar.
In plain terms: instead of a single model instance running a task sequentially, Opus 4.8 acts as the orchestrator. It decomposes the job, dispatches parallel agents, and validates the merged output before the user sees it.
A real-world demonstration of the scale this enables: Jarred Sumner used dynamic workflows to port Bun from Zig to Rust, 750,000 lines, 99.8% test pass rate, eleven days from first commit to merge.
Dynamic workflows is available on Claude Code's Enterprise, Team, and Max plans.
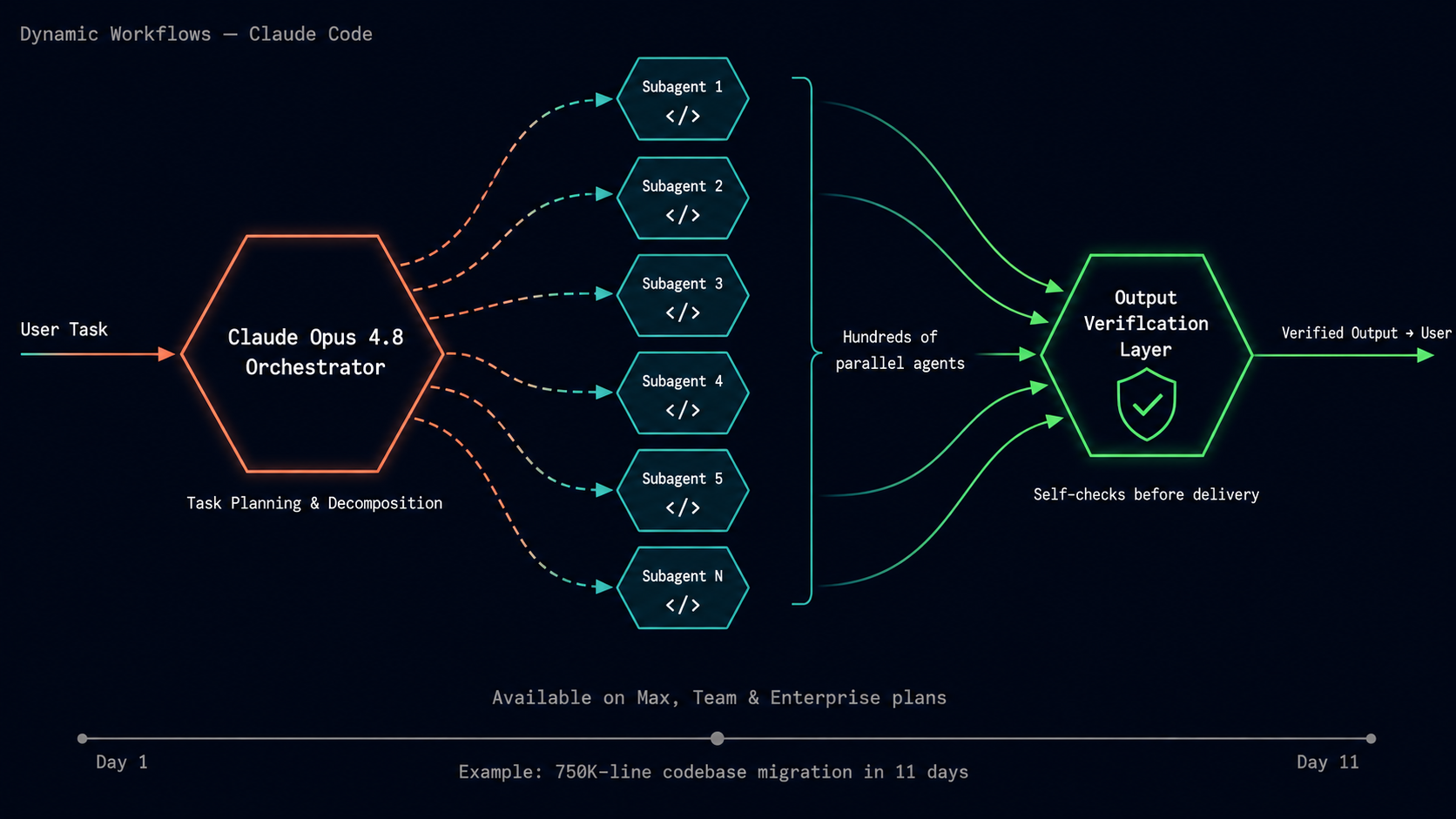
dynamic workflows
Effort Control: A New Tuning Knob for Every Team
A new control alongside the model selector lets users choose how much effort Claude puts into a response. On higher effort settings, Claude will think more frequently and more deeply to give better responses. On lower effort settings, Claude will respond faster and use up a user's rate limits more slowly.
Effort control runs from Low to Max. The default is "high." Users can pick "extra" (xhigh in Claude Code) or "max," and the model spends more tokens to chase better answers.
There is also a new top tier called ultracode. Ultracode is defined as xhigh plus workflows, it pairs the highest reasoning effort with dynamic workflows, so Claude plans a large task, spins up hundreds of parallel subagents in one session, and verifies its own outputs.
The practical implication: a pipeline that needs occasional deep analysis can use Max selectively without paying for it on every call. Teams can tune cost-per-task without touching the model itself.
Fast Mode: 3× Cheaper, Same Speed Advantage
Fast mode for Opus 4.8, where the model can work at 2.5× the speed, is now three times cheaper than it was for previous models.
Standard pricing held flat: $5 input / $25 output per million tokens. Fast mode pricing is $10/$50 compared to $30/$150 for Opus 4.7's fast tier.
For teams that were previously using Sonnet for latency-sensitive tasks instead of Opus, this pricing shift changes the math. You get flagship-tier reasoning at fast-mode speed for a fraction of what it cost six weeks ago.
The Messages API Change Developers Need to Know
The Messages API now accepts system entries inside the messages array. Developers can update Claude's instructions mid-task without breaking the prompt cache or routing the update through a user turn. This can be used to update permissions, token budgets, or environment context as an agent runs.
This is a quiet but significant change for anyone building long-running agentic systems. Updating a system prompt mid-session previously forced a context break. Now it does not.
4.7 vs 4.8: When to Upgrade, When to Hold
Upgrade to 4.8 if you are:
- Running agentic coding pipelines where unflagged bugs cost real money
- Doing codebase-scale migrations or refactors with Claude Code
- Using computer-use or browser-agent features (OSWorld jump is significant)
- Paying for Opus 4.7 fast mode (3× cost reduction is immediate savings)
Hold on 4.7 if you are:
- Running agentic pipelines that receive untrusted external input (prompt injection regression)
- On Microsoft Foundry with a context requirement above 200K tokens (Opus 4.8 is currently capped at 200K context on Microsoft Foundry while running 1M elsewhere)
For most teams, the upgrade is a direct swap. The model ID changes to claude-opus-4-8. The price does not.
What Comes After 4.8
Anthropic plans to release a new class of model with even higher intelligence than Opus. Claude Mythos Preview is currently being used by a small number of organizations for cybersecurity work under Project Glasswing. Anthropic is making swift progress on developing safeguards and expects to bring Mythos-class models to all customers in the coming weeks.
Opus 4.8 lands between Opus 4.7 and the more capable Claude Mythos Preview in Anthropic's internal capability ladder. Think of it as the public frontier while Mythos completes its safety assessment.
Conclusion
Claude Opus 4.8 is not a flashy upgrade. It is a precise one. Coding accuracy improved. Honesty is measurably better. Fast mode is dramatically cheaper. Dynamic workflows open a new category of long-running, parallel agentic tasks that simply were not possible before. And alignment scores sit closer to Mythos than to any previous Opus model.
For teams evaluating the 4.7-to-4.8 switch, the math is clear. Same price. Better performance on every workload that matters for production AI systems. The one trade-off, prompt injection robustness in agentic loops, is manageable with proper sandboxing.
The real question is not whether to upgrade. It is how to use the new headroom.
FAQs
Q1. What are the biggest improvements in Claude Opus 4.8 compared to Opus 4.7?
Claude Opus 4.8 improves coding performance, honesty, mathematical reasoning, and agentic workflows. It also introduces Dynamic Workflows, Effort Control, and significantly cheaper Fast Mode pricing while maintaining the same base API pricing.
Q2. What is Dynamic Workflows in Claude Opus 4.8?
Dynamic Workflows enables Claude to act as an orchestrator that plans tasks, launches hundreds of parallel subagents, verifies outputs, and combines results into a final response. This allows large-scale software engineering and complex agentic tasks.
Q3. Should developers upgrade from Claude Opus 4.7 to Opus 4.8?
Most developers should upgrade because Opus 4.8 offers better coding accuracy, improved honesty, stronger computer-use capabilities, and lower Fast Mode costs. Organizations handling untrusted external inputs should evaluate prompt injection risks before deployment.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
