

What are adversarial attacks in machine learning and how to prevent them?
Adversarial attacks in ML manipulate input data to mislead models, affecting fields like image recognition and spam detection. Learn how techniques like MLOps, secure ML practices, and data validation can defend against these evolving security threats.

Several of the technologies users use daily now include machine learning, from the face detection security on iPhone to Alexa's voice recognition feature and the spam protection in our emails.
However, the widespread use of machine learning and its variant, deep learning, has also sparked the emergence of adversarial assaults, a class of techniques that pervert algorithmic behavior by feeding them carefully constructed input data. Let’s get deep into what What are adversarial attacks in machine learning and how can you prevent them.
Adversarial machine learning definition
A machine learning technique called adversarial machine learning tries to deceive machine learning models by giving them false information. As a result, it covers both the creation and detection of hostile examples or inputs made specifically to trick classifiers.
These so-called adversarial machine learning attacks have been thoroughly researched in various fields, including spam detection and image classification.
The most thorough research on adversarial machine learning has been done in the field of image recognition, where alterations to images are made to trick classifiers into making the wrong predictions.
A technique for producing hostile examples is an adversarial attack. An example that is intended to induce a computer vision model to predict incorrectly even though it would appear to be valid to a person is called an adversarial example.
Types of adversarial attacks
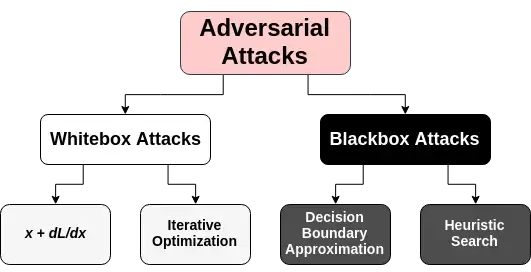
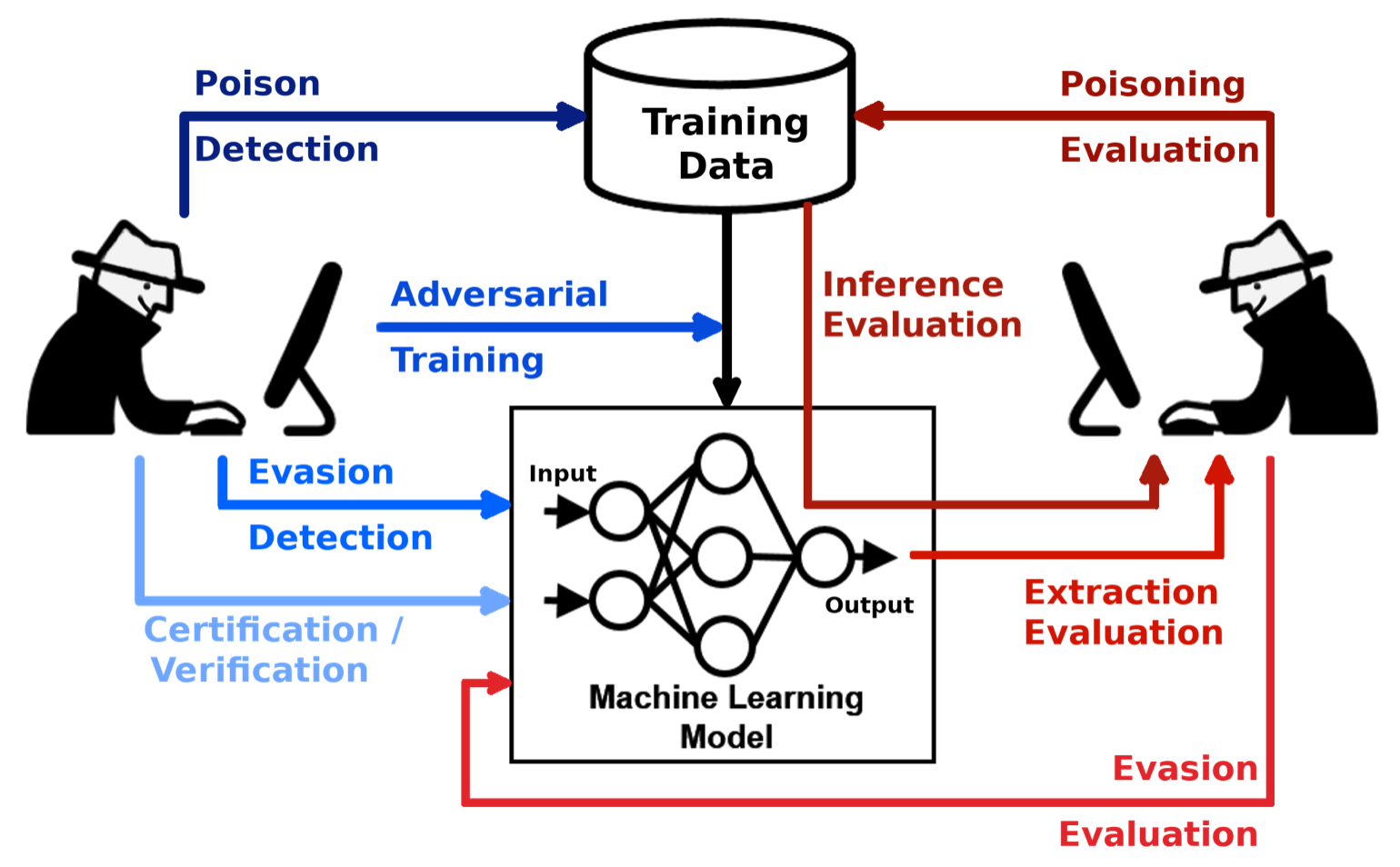
Attacks on AI models are frequently divided into "white box" and "black box" subcategories based on how they affect the classifier, violate security, and are specifically targeted. In contrast to black box attacks, which are more difficult to execute, white box attacks provide the attacker access to the model's parameters.
A security violation is providing malicious data that is mistaken for valid data, but an attack can affect the classifier, or the model, by interfering with the model as it generates predictions. A targeted attack seeks to enable a particular intrusion or disruption or, conversely, to spread mayhem broadly.
Attacks that modify data to avoid detection or be recognised as legitimate are the most common sort of attacks. Evasion is similar to how spammers and hackers disguise the content of spam messages and malware, but it does not require control over the data used to train a model. Spam that is contained within an attached picture to avoid being detected by anti-spam models is an example of evasion. Spoofing attempts against AI-driven biometric verification systems serve as another illustration.
Data "adversarial contamination" is a different attack type. Machine learning systems frequently undergo retraining using data gathered while they are in use. An attacker might taint this data by introducing malicious samples, which then prevent the retraining from taking place. During the training phase, an adversary may introduce data that was tagged as benign but malicious. For instance, research has demonstrated that when given specific words and phrases, huge language models like OpenAI's GPT-3 can divulge private and sensitive information.
Read here about another fantastic product by OpenAI's-ChatGPT
Model stealing, also known as model extraction, entails an adversary examining a "black box" machine learning system to either reconstitute the model or obtain the data on which it was trained on. When the model itself or the training set of data is sensitive or confidential, this can lead to problems. A custom stock trading model, for instance, may be taken using model stealing, and the adversary can then exploit it to their financial advantage.
The implementation of adversarial attacks
Machine learning algorithms learn their behaviour through experience, in a contrast to traditional software, where programmers manually create instructions and rules.
For instance, to construct a lane-detection solution, the developer creates a machine-learning algorithm, trains it, and then feeds it numerous tagged photos of street lanes taken at various angles and in various lighting situations.
The machine-learning model then fine-tunes its settings to catch the typical patterns that appear in photographs with street lanes.
The model can detect lanes in new photos and videos with astounding accuracy if the algorithm is designed correctly and there are enough training samples.
Contrary to popular belief, algorithms for machine learning are statistical inference engines—complex mathematical operations that convert inputs to outputs—despite their success in challenging disciplines like computer vision and speech recognition.
When a machine learning algorithm classifies a picture as containing a particular object, it does so because it has discovered that the image's pixel values are statistically comparable to other photographs of that object that it has previously analyzed.
The targeted data type and intended outcome determine the kinds of perturbations used in adversarial assaults.
For instance, it is sensible to take into account minor data perturbation as an adversary model for images and audio because they are not detected by humans but may cause the target model to behave inappropriately, leading to the contradiction between machine and human.
The semantics of some data types, such as text, can be "perturbed" by changing a single word or letter, although this disruption is simple for humans to pick up on. As a result, the danger model for text must be distinct from that for image or audio.
Some other types of adversarial attacks include:
- Malicious ML assault: Threat actors identify subtle inputs to ML that support further, unnoticed attack actions using the adversarial sampling technique mentioned above.
- Data contamination: Threat actors modify learning outcomes by adding data to ML inputs as opposed to actively attacking the ML model. Threat actors need access to the unprocessed data that the ML solution uses to poison.
- Adversarial online attack: Threat actors put bogus data into machine learning (ML) solutions that collect internet data as part of their modelling processes.
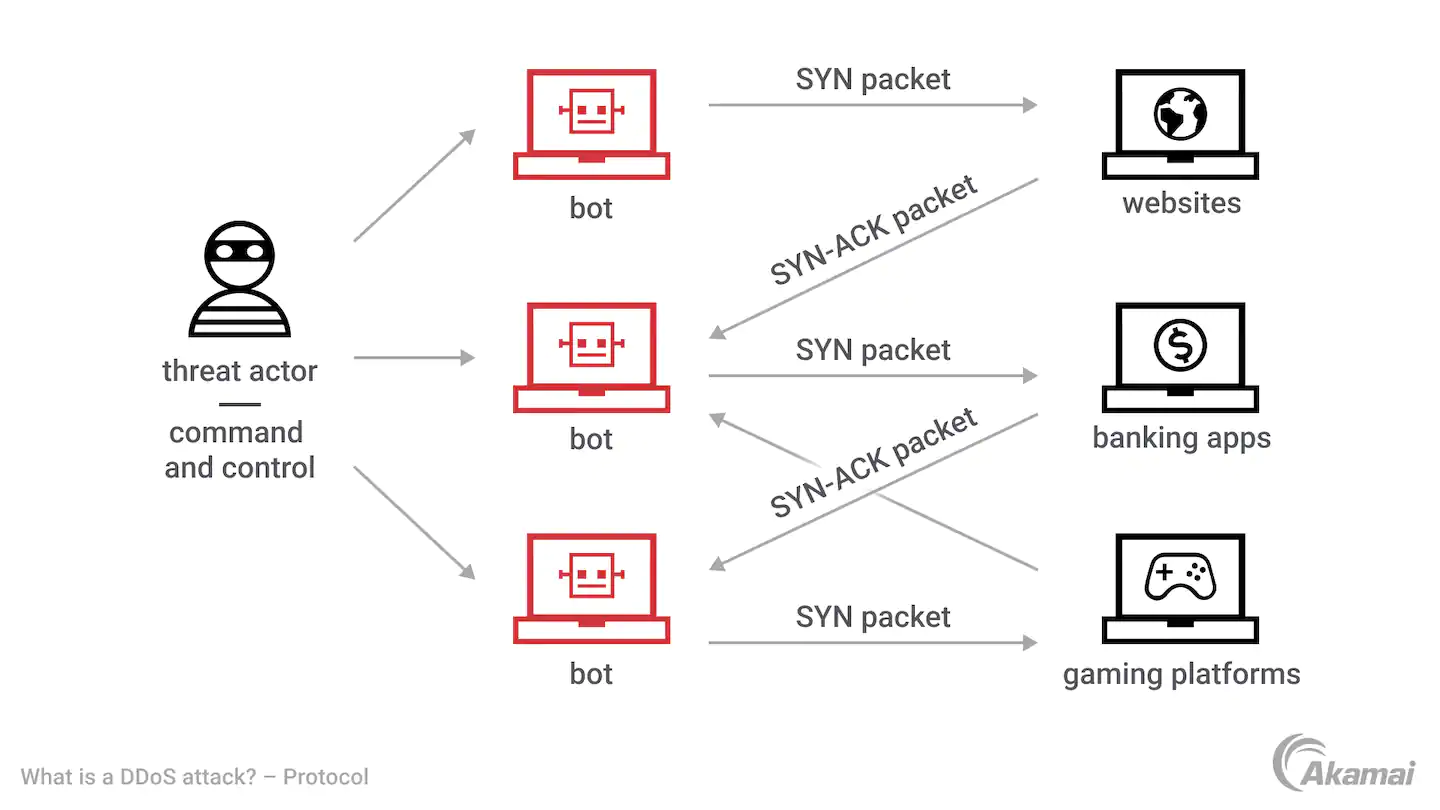
- DDoS: ML is vulnerable to denial of service attacks, just like any security measure that threat actors can bypass. Threat actors systematically provide ML with challenging challenges, rendering the learning processes ineffective.
- Transfer of knowledge: Bolun Wang et al. show how threat actors can use machine learning (ML) training models to understand flaws in ML processes, increasing the likelihood of tricking ML into drawing the wrong conclusions and opening up additional attack avenues. This capability is described in their research paper With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning.
- Phishing for personal data: Threat actors compromise the secrecy of the ML dataset by reverse engineering it. This is feasible, for instance, if the model is only trained on a tiny fraction of sensitive data.
How can you prevent Adversarial attacks in AI?
These ML attacks demand a thorough ML management strategy, which includes securing ML activities and keeping an eye out for the defenses' inevitable gaps. Risk analysis for each ML implementation, assignment of content ownership and operational control, modification of existing security policies, and establishment of new security policies are the first steps in ML defense.
In terms of design, model creation, and operations of ML systems, including validation and data validation, MLOps is emerging. It is a collection of procedures meant to strengthen and standardize the ML, DevOps, and machine learning fields.
- Model reproducibility
- Reliability of predictions
- Conformity with security policy
- Regulation observance
- Monitoring and administration
The Mechanism of Adversarial Attacks on AI Systems
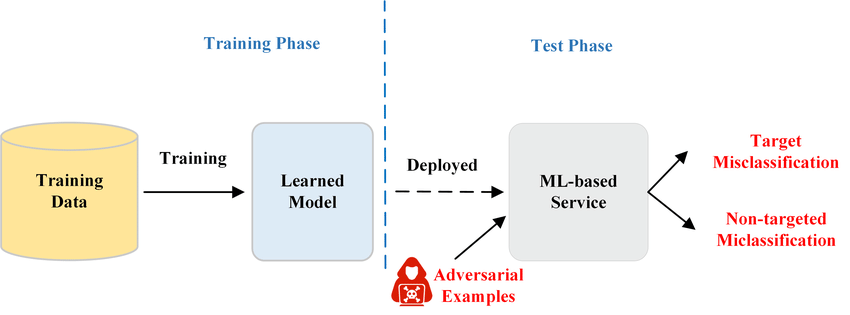
Machine learning systems are vulnerable to a wide range of various adversarial assaults. Many of them employ classic machine learning models like linear regression and support vector machines (SVMs), as well as deep learning systems. The majority of adversarial assaults often try to reduce classifier performance on particular tasks, thus "fooling" the machine learning system. The area of adversarial machine learning investigates a class of assaults meant to degrade classifier performance on particular tasks. The following categories can be used to classify adversarial attacks:
Attacks Using Poisons
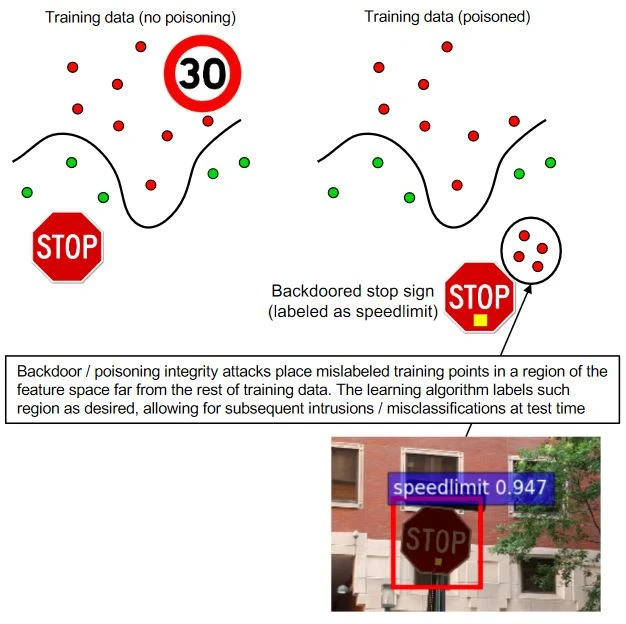
By manipulating the training data or its labels, the attacker can make the model perform poorly during deployment. Poisoning is simply the hostile contamination of training data, so to speak. As data gathered during operation can be used to retrain ML systems, an attacker might taint the data by introducing malicious samples. This would interfere with or affect the retraining process.
Evasion Attacks
The most common and studied types of attacks are evasion attacks. During deployment, the attacker tampers with the data to trick classifiers that have already been trained. They are the most common sorts of attacks employed in penetration and malware scenarios since they are carried out during the deployment phase. By hiding the information in spam emails or malware, attackers frequently try to avoid being discovered. Since this classification does not directly affect the training data, samples are altered to avoid detection. Attacks on systems for bio metric verification that use spoofing are examples of evasion.
Extraction of Models
An attacker exploring a black box system for machine learning to either rebuild the model or recover the data it was built on is known as model stealing or model extraction. This is especially important if the model itself or the training data are private and sensitive information. An adversary could utilise a share market prediction model stolen through a model extraction attack to their financial advantage.
Conclusion
Through the potential for data manipulation and exploitation, machine learning creates a new attack surface and raises security threats. Companies implementing machine learning technology must be aware of the dangers of hostile samples, stolen models, and data manipulation.
Discover More About AI-Powered Data Labeling Solutions

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
