

What is MLOps — Everything You Must Know to Get Started
MLOps is a practice combining machine learning and DevOps principles, streamlining the ML lifecycle for better collaboration, automation, and deployment of models. Discover its stages, uses, and best practices.

Till recent times, we were all learning about the software development lifecycle (SDLC) and how it starts with requirement elicitation and ends with maintenance. We were (and still are) researching the iterative, and agile software development models.
Almost every other entity is now attempting to accommodate AI/ML into ones product. This new requirement for building ML processes adds/reforms some SDLC principles, giving rise to a new practice of engineering known as MLOps.
Let’s get into detail about MLOPs- their uses, benefits, and stages and how you can do it effectively.
Table of Contents
- What exactly is MLOps?
- What are MLOps used for?
- Why do we require MLOps?
- What are the advantages of MLOps?
- What are the MLOps components?
- Phases of MLOps
- Some of the Best MLOps Practices
- Conclusion
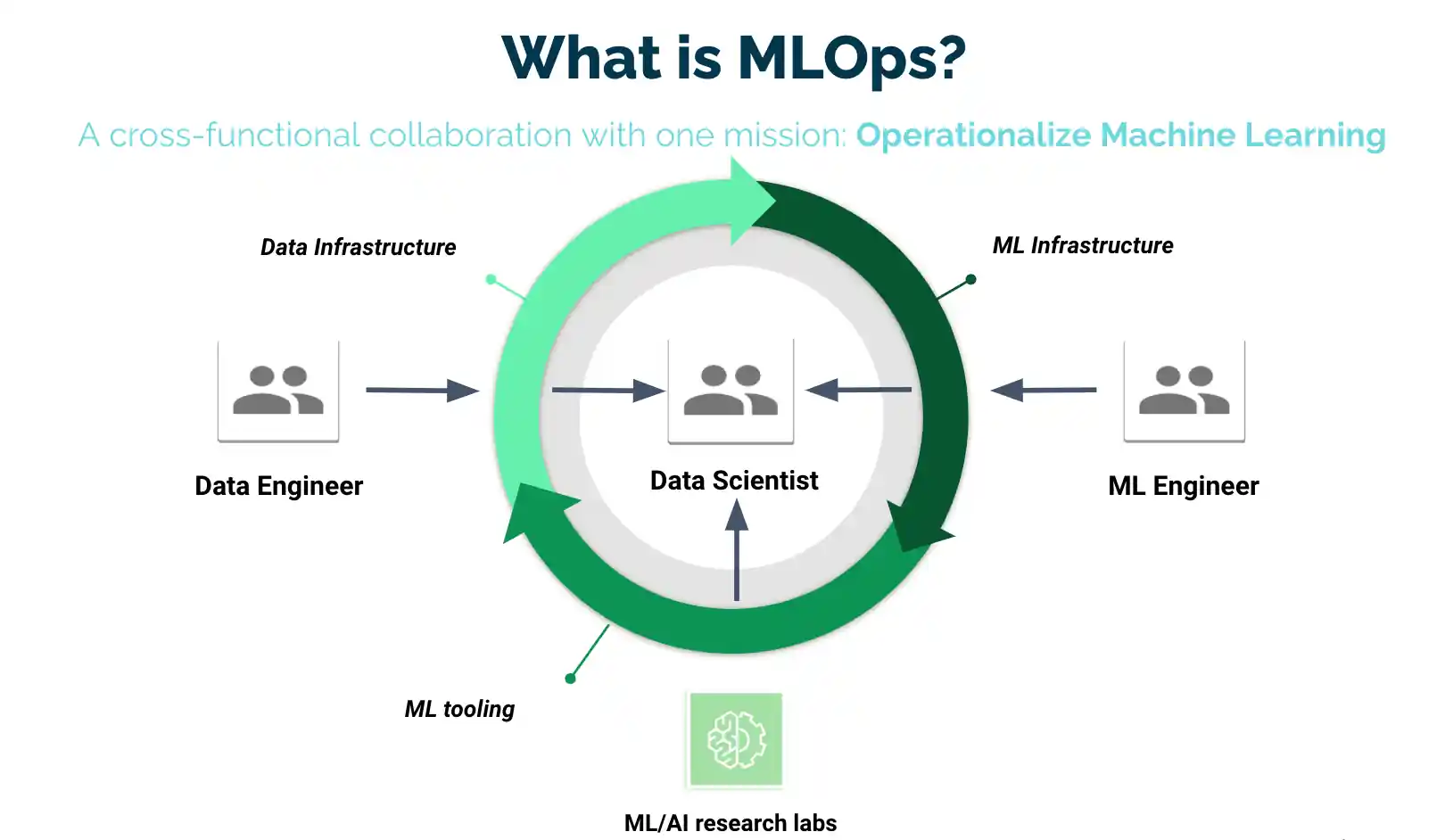
What exactly is MLOps?
MLOps is a collection of practices for data professionals and operations professionals to collaborate and communicate. Using these practices improves the quality of Machine Learning and Deep Learning algorithms, simplifies management, and automates their deployment in large-scale production environments. Models are easier to align with business needs as well as compliance standards.
MLOps is gradually evolving into a stand-alone methodology to ML life - cycle management. It covers the entire lifecycle, including data collection, model creation (SDLC, CI/CD), orchestration, implementation, health, diagnostic tests, governance, and performance measurement systems.
What are MLOps used for?
MLOps is a useful approach for developing and enhancing the performance of AI and machine learning solutions. By maintaining continuous integration and deployment (CI/CD) practices with close supervision, validation, and governance of ML models, data engineers, and machine learning engineers can collaborate and accelerate model development and production by using an MLOps approach.
Why do we require MLOps?
It is difficult to commercialize machine learning. The machine learning life cycle includes many complicated structures like data ingestion, data preparation, model training, model optimization, model deployment, model tracking, and much more.
It also necessitates cross-team collaboration and hand-offs, from Data Science to Data Engineering to Machine Learning Engineering.
To keep all of these mechanisms synchronous as well as working in tandem, stringent operational rigor is required.
MLOps refers to the machine learning lifecycle's experimentation, refinements, and continuous improvement.
What are the advantages of MLOps?
MLOps' primary advantages are efficiency, expandability, and risk reduction. MLOps enables data teams to develop models faster, deliver higher-quality ML models, and deploy and produce models more quickly. MLOps also allows for massive scalability and management, with thousands of models being overseen, governed, managed, and supervised for continuous deployment, continuous delivery, and agile methodologies.
MLOps, in particular, allows for the internal consistency of ML pipelines, allowing for more tightly connected collaborative efforts across data teams, resolving conflicts with continuous integration and IT, and speeding up release velocity. Reducing risk: Machine learning models frequently require regulatory scrutiny and drift-checking, and MLOps allow for greater clarity and faster responses to such requests, as well as greater adherence to an organization's or industry's policies.
What are the MLOps components?
In machine learning projects, the scope of MLOps can be as narrow or as broad as the project requires. MLOps can range from data pipeline to model output in some cases, while other projects may only require MLOps execution of the model deployment process. The majority of businesses use MLOps principles in the following areas:
- Analyzing exploratory data (EDA)
- Data Preparation and Feature Development
- Model development and refinement
- Model evaluation and governance
- Serving and model inference
- Model surveillance
- Model retraining that is automated
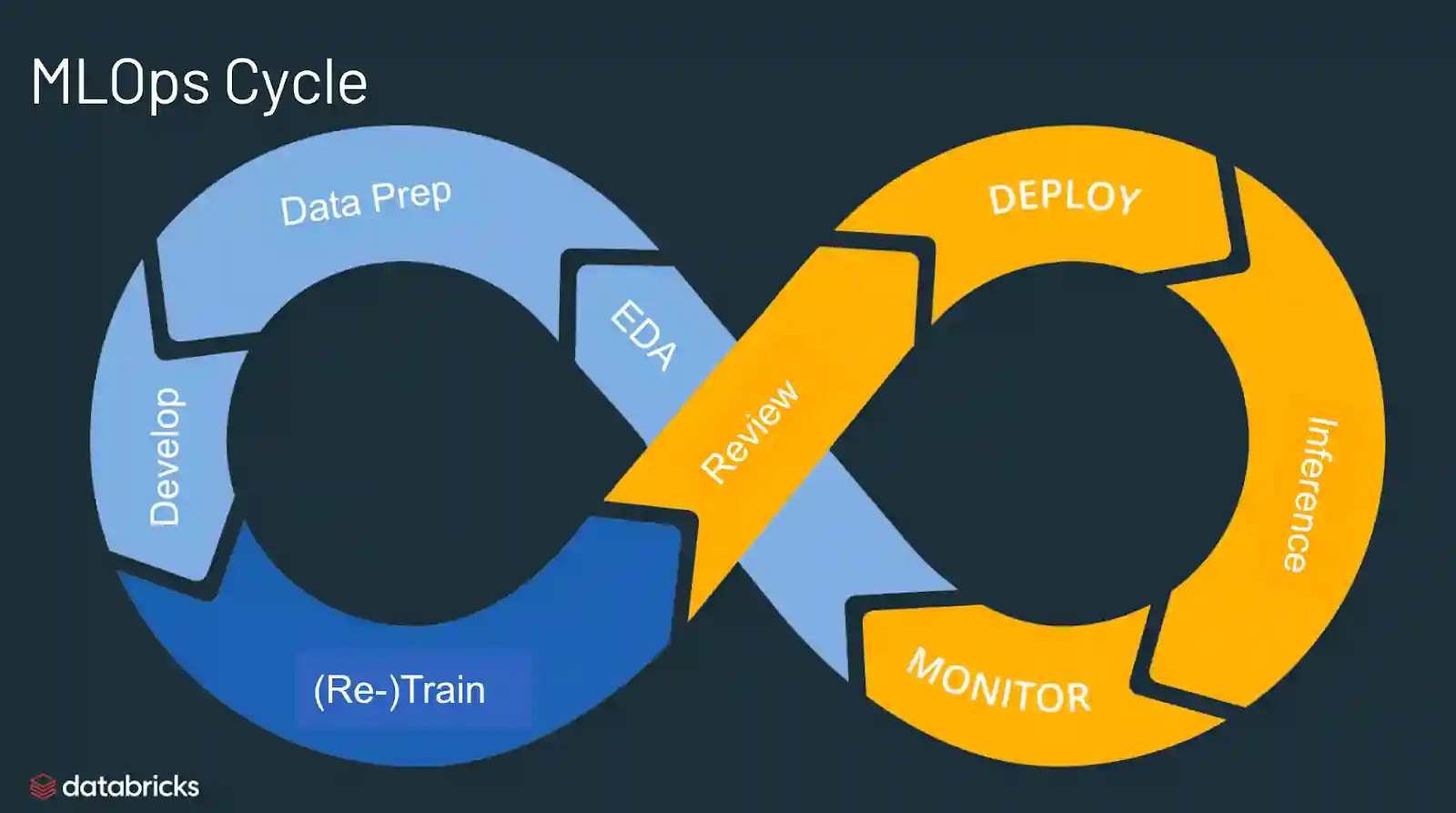
Phases of MLOPs
Stage 1: Successful Machine Learning Pilot
This is the stage at which everyone in your company, function, or department is ecstatic about the first few ML use cases. The leader (company-wide, operational, or divisional) has established a mandate to learn from MS in ML to use machine learning to improve customer support, reduce costs, or process automation tasks. There are pilot projects set to begin, and numerous of them show early signs of significant benefit.
Stage 2: Initial Deployment
You have completed ML proofs of concept successfully. With the available data, you can make precise predictions (internal and external data). You have worked hard to convert the models into judgments.
The team of data scientists deploys and manages the models. For example, they may enclose the model in a flask machine to provide real-time predictions via an API, or they may run batch scoring programs on a regular basis to deliver model results that are integrated into a database.
Stage 3: IT is in charge of serving
You have a few models and have successfully enlisted IT to manage the deployment of ML models in a devoted production environment.
It manages the data pipeline that can provide input data and convert it into the features required by the models. The versioning of model objects is managed collaboratively by IT and data science. The team of data scientists certainly provides the extended model and convert logic for the features, with Jupyter notebooks serving as the primary workbench and delivering source code. They are still working on new models.
Stage 4: Ongoing Integration
Based on DevOps lessons learned, you create an environment in which data scientists teams can create a structured training pipeline for ML models, optimizing unit and assimilation tests to make sure the model corresponds, the feature converts logic produces expected results, and so on.
Once the data science team has finished developing and testing the models, IT simply packages and deploys the orchestrated training pipeline into production.
IT engineers developed business logic in collaboration with data scientists that triggers model retraining based on predetermined timelines or some changes in model input/output.
Now that the data scientists team is no longer required to update the models on a regular basis, they have significantly expanded the reach of ML. They want to incorporate machine learning models into each and every business operation where a significant number of choices are taken by judgment.
Stage 5: Complete Automation and Monitoring
At this point, the MLOps stack includes capabilities for automatically implementing different models and enhancements into production environments, regardless of the tools used by data scientists.
Feature stores serve as a single source of truth for features. Monitoring is advanced. Continuous and automatic training is used.
All of this results in a highly efficient and satisfied team of data scientists, effective because they can complete tasks more quickly, and pleased because they have a considerable impact on the company.
The technical team is working hard. They can concentrate on improving infrastructure rather than trying to manage operational tasks, and they are pleased because they can translate the pledge of data science into substantial business benefits.
Some of the Best MLOps practices
The phase where the MLOps principles are implemented can help to define the best practices for MLOps.
Exploratory data analysis (EDA) - Create reproducible, customizable, and easy-to-share datasets, tables, and visualizations to iteratively investigate, share, and process the data for the machine learning lifecycle.
Data Preparation and Feature Engineering- Transform, accumulate, and de-duplicate data iteratively to create finely tuned features. Most importantly, use a feature store to make features recognizable and accessible across data teams.
Model training and optimization - To train and enhance model performance, use well-known open-source library functions like sci-kit-learn and hyperopic. Utilize machine learning automation tools like Auto ML to perform trial runs and generate reviewable and ready-to-deploy code as a simpler alternative.
Model review and governance entail tracking model lineage and versions, as well as managing model artifacts and transitions throughout their lifecycle. Explore, share, and work collaboratively across ML models.
Model extrapolation and serving - Manage model refresh frequency, inference request times, and other production-specifics in diagnostics and QA. To optimize the pre-production pipeline, use CI/CD methods such as repositories and orchestrators (based on DevOps principles).
Model deployment and surveillance - Automate authorizations and grouping creation to allow registered models to be produced. Turn on REST API model access points.
Automated model retraining entails creating alerts and automating actions to correct model drift caused by variations in training and inferential data.
Conclusion
If you are currently working in the experimental stage of MLOPs, data preparation is the first step. Labellerr helps ML teams to manage computer vision data pipelines effectively that enable MLOps efficiently.
With our unique smart feedback loop, we automate the processes and allow you to get effective results by saving time and project costs.
To know more about such related information, stay tuned with Labellerr!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
