

The essential guide to quality training data for machine learning


Data are necessary for machine learning models. Even the most efficient algorithms might become useless without a base of high-quality training data. In fact, when they are initially trained on insufficient, erroneous, or irrelevant data, strong machine learning algorithms can be severely hindered. A well-known adage still holds brutally when it pertains to training data for machine learning: garbage in, garbage out.
Quality training data are therefore the most crucial component in machine learning. A machine learning model builds and fine-tunes its rules using initial data, which is referred to as "training data." The model's future development will be greatly impacted by the quality of this training data, which will also have significant implications for all applications that use this training data in the future.
How do you verify that your algorithm is ingesting high-quality datasets since training data is a vital component of almost any machine learning model? The effort required to gather, categorize, and prepare training data is highly onerous for many project teams. They occasionally make compromises when it comes to the quality or quantity of training data, which might have serious consequences later.
Let’s start with basics, first try to understand training data and testing data in detail.
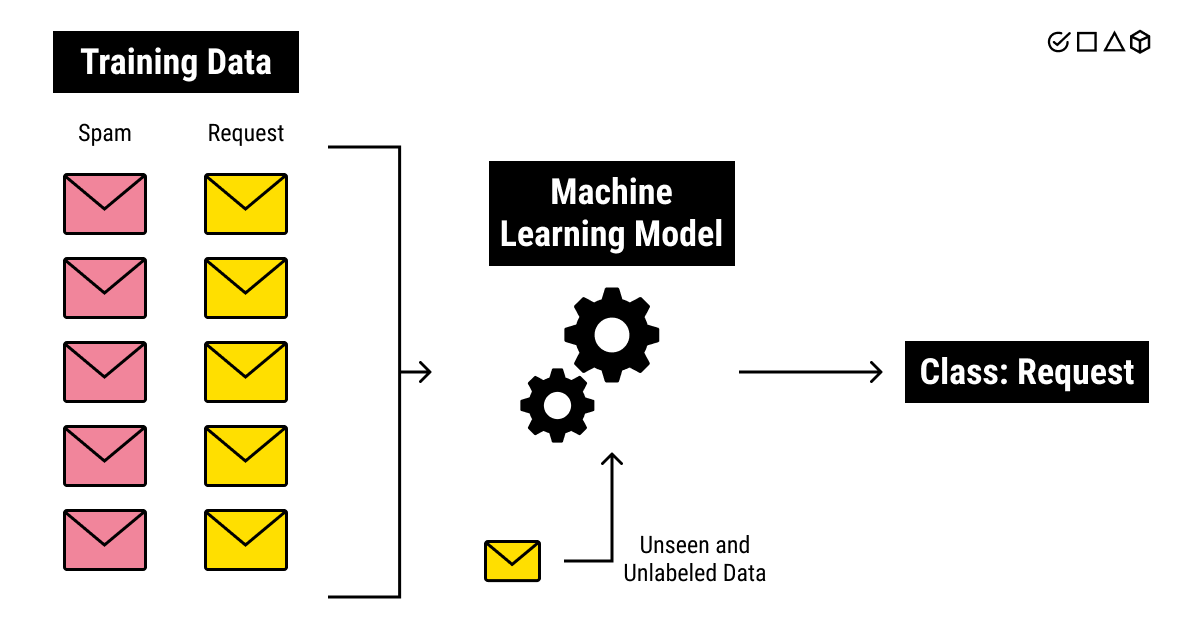
Training Data: what is it?
Algorithms are used in machine learning to extract knowledge from datasets. They identify patterns, gain insight, make judgments, and assess those judgments.
The datasets are divided into two groups for machine learning.
The first subset, referred to as the training data, is a section of our real dataset that is used to train a machine learning model. Using this dataset, they train the model The testing data refers to the other subset. Below, we'll go into greater detail.
Usually, the size of training data is greater than testing data. This is because we want to provide the model with as much information as we can in order for it to identify and learn useful patterns. When our datasets' data are supplied to a machine learning algorithm, the programme recognises patterns in the data and draws conclusions.
Machines can answer problems based on prior observations thanks to algorithms. comparable to how humans learn by doing. The sole distinction is the quantity of samples needed by machines to recognise patterns and learn.
Machine learning models get better over time as they are exposed to more useful training data.
Training your object detection AI model with Labellerr: Read here
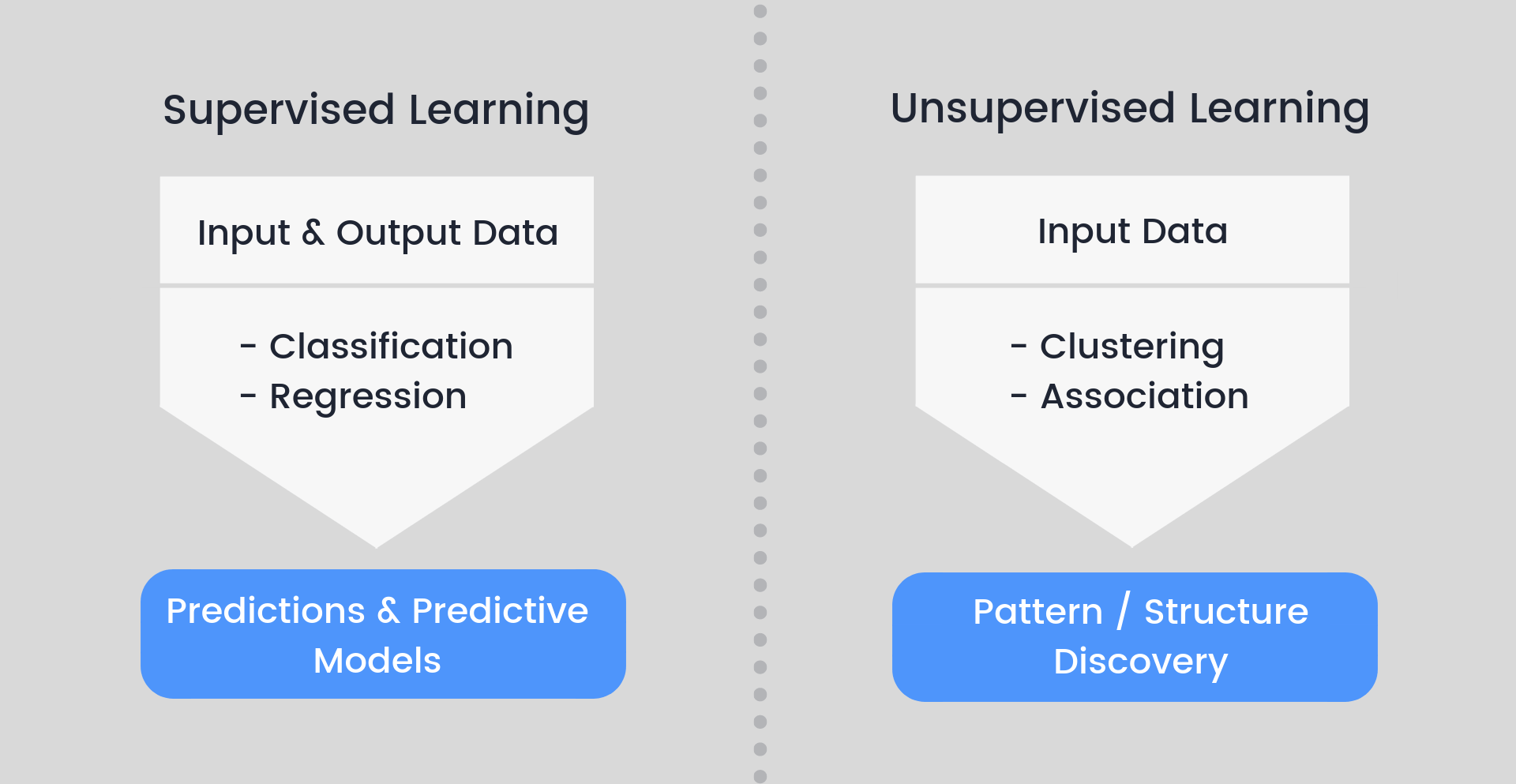
Whether you're utilizing supervised or unsupervised machine learning, your training data will change.
- In supervised learning, the features of the data that will be utilised in the model are selected by humans. To teach the computer how to recognise the results of your model is supposed to detect, training data must always be labelled, that is, enhanced or annotated.
- In unsupervised learning, patterns in the data—such as inferences or grouping of data points—are discovered using unlabeled data. There are machine learning models that combine supervised and unsupervised learning, known as hybrid models.
The variety of training data types reflects the numerous potential uses for machine learning algorithms. Text (words and numbers), photos, video, and audio can all be included in training datasets. Additionally, you may have access to them in a variety of formats, including a spreadsheet, PDF, HTML, or JSON. Your data can act as the foundation for creating a flexible, effective machine-learning formula when it is properly categorized.
What is Testing data?
You need unknown data to test a machine learning model after it has been constructed (using your training data). You can use this data, which is referred to as testing data, to assess the effectiveness and development of the training of your algorithms and to modify or optimize them for better outcomes.
Two main standards apply when testing data. It ought to:
- Display the actual dataset
- Be ample enough to produce accurate predictions
The data set must contain brand-new, "unseen," data. This is so because your model "knows" the training set of data beforehand. You'll be able to tell if it's operating appropriately or if it needs more training data based on how it performs on fresh test data.
Test data offer a last-minute, practical verification of an unknown data set to show that the algorithm for machine learning was successfully trained.
80% of your data are often used for training and 20% are typically used for testing in data science.
How does machine learning use training data?
Machine learning algorithms develop by exposure to relevant instances in your training data, in contrast to other types of algorithms, which are controlled by pre-established variables that serve as a form of "recipe."
How successfully the machine learns to recognize the outcome, or the response, that you want the machine learning model to predict, depends on the characteristics in the training data and the quality of the labelled training data.
For instance, you may use consumer transaction information that is appropriately labelled for the observed data, or characteristics, you feel are significant indications for fraud to train an algorithm meant to spot suspect credit card payments.
The accuracy and effectiveness of a machine learning model are determined on the calibre and amount of your training data. Your model's performance would most likely be subpar if you trained using the training data from only 100 transactions as opposed to training it using data from 10,000 interactions. More is typically better when it comes to training data diversity and volume, assuming the data is correctly categorized.
All through the AI development lifecycle, training data is utilized to both initially train and afterwards retrain your model. Training data is dynamic; as real-world conditions change, your basic training dataset may become less accurate over time in capturing the ground truth, necessitating an update of your training data and a retraining of your model.
What distinguishes training data from testing data?
Although both are necessary for enhancing and verifying machine learning models, it is vital to distinguish between training and testing data. Testing data is used to evaluate the model's accuracy, whereas training data "teaches" an algorithm to recognize patterns in a data set.
Training data is the data set that you use to hone your algorithm or model so that it can correctly predict your outcome. You can evaluate and get information from validation data to help you choose the right algorithm and model parameters. Test data are used to gauge how well the algorithm that trained the machine performed in terms of accuracy and efficiency, as well as how well it predicted future responses in light of its prior training.
Consider a machine learning model designed to determine whether a human is depicted in an image or not. Images that have been tagged to identify whether a person is present or not in the photo would be included in the training data in this scenario. You would next unleash your model on unstructured test data, such as pictures of people and pictures of objects, after feeding it this training data.
The performance of the algorithm on test data will then confirm the efficacy of your training strategy or point to the necessity for additional or alternative training data.
Data labeling: why it is important to manage it efficiently: Read here
How Testing and Training Data Are Used?
Computer vision models are based on algorithms that examine your training data set, categorize the inputs and outputs, and then examine it again.
A issue arises when an algorithm needs to take into account data from other sources, like real-world consumers, because a sufficiently trained algorithm will effectively memorize all of the outputs and inputs in a training data set.
There are three steps in the training data process:
- Feed - supplying data to a model.
- Define - The model creates text vectors from training data (numbers that represent data features)
- Test - Lastly, you put your model to the test by providing it with test data.
After training is finished, you can test the model using the 20% of the original data set that you saved (without labelled results, if using supervised learning). Here, the model is adjusted to ensure that it performs as intended.
You don't have to bother about fine-tuning in Obviously AI because the entire procedure (training and testing) is completed in a matter of seconds. To ensure that it's not a black box, we constantly advise knowing what's going on in the background.
How much training data is required for your model?
There is no simple solution to this problem and no magic mathematical formula, but more information is always better. The intricacy of the problem you're trying to solve as well as the algorithm you come up with to solve it will determine how much training data you need to build a machine learning model. Build your model using the data you have and evaluate its performance to determine the amount of training data you will need.
Read here on how you can train your model with limited training data
Where can you find training data?
Whether you employ an internal team, turn to the public for help, or hire a data labeling service, you can utilize your existing data and tag it yourself. Additionally, you can buy training data that has been labelled for the data characteristics you decide are important for the machine learning model you are creating.
If you are engaged on a computer vision program to train a machine to recognise or interpret items that are visible with the human eye, you would need an unique kind of training data. To teach a machine learning model to "see" for itself in this situation, you would require labelled photos or videos. For further procedure of model training, take professional help from us.
Who we are?
Labellerr is a training data platform that offers a smart feedback loop that automates the processes that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. Our advanced technology helps to fasten processes to generate training data by optimization of human-in-the-loop and automating data preparation pipeline.
Waiting is never a solution to your problem, contact us today to fasten your process!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
