

Data labeling: why it is important to manage it efficiently

In today’s technically advanced world, Computer Vision has enabled a lot of ways to automate processes. With different machine learning models, understanding and classifying data has become an easy task. What human efficiency is incapable of, computer vision can do it very easily. It might take months to label 1000 images but your machine can do it in a much easier way-basically they annotate data. You must have come across the term data labeling.
Have you wondered why managing or labeling data plays an important role while applying computer vision technology to your use case application?
Since the quality of the input data directly affects the performance of the model, data labeling is an important stage in the training of Machine Learning algorithms. Indeed, the most effective technique to enhance an algorithm is to increase the quality and quantity of training data.
Table of Contents
- What is Data Labeling?
- Types of Data Labeling
- What Are Some of the Data Labeling Approaches?
- How Can Data Labeling Be Carried Out Efficiently?
- What Factors Impact the Efficiency and Accuracy of Data Labeling?
- Conclusion
What is data labeling?
Data labeling in machine learning is the procedure of classifying unlabeled data (such as photos, text files, video, etc.) and putting one or more insightful labels to give the data perspective so that a machine-learning model may learn from it. Labels might say, for instance, if a photograph shows a bird or an automobile, which words were spoken in a voice recording, or whether a tumor is visible on an x-ray. For several use cases, such as natural language processing (NLP), computer vision, as well as speech recognition, data labeling is necessary.

Types of data labeling
There are types of data labeling. Here are some instances of the most typical types since every data form has a distinct labeling process:
1. Text annotation
The technique of categorizing phrases or paragraphs in a document according to the topic is known as text annotation. This material can be anything, from customer reviews to product feedback on e-commerce sites, from social network mention to email messages. Text annotation offers several opportunities to extract relevant information from texts because they clearly express intents. Because machines don't understand concepts and feelings like humor, sarcasm, rage, and other abstract concepts, text annotation is a complicated process with many steps.
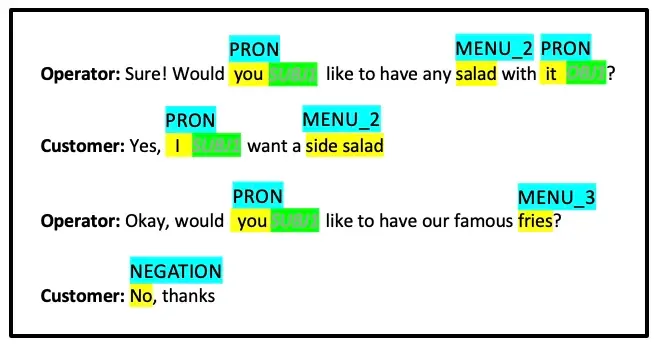
2. Image annotation
Annotating an image makes sure that a machine will recognize the annotated region as a different object. These models receive captions, IDs, and keywords as attributes when they are trained. The algorithms then recognize and comprehend these factors and develop their internal knowledge. To be employed in a variety of AI-based technologies like face detection, computer vision, robotics vision, and autonomous vehicles, among others, it typically includes the usage of bounding boxes or semantic segmentation.
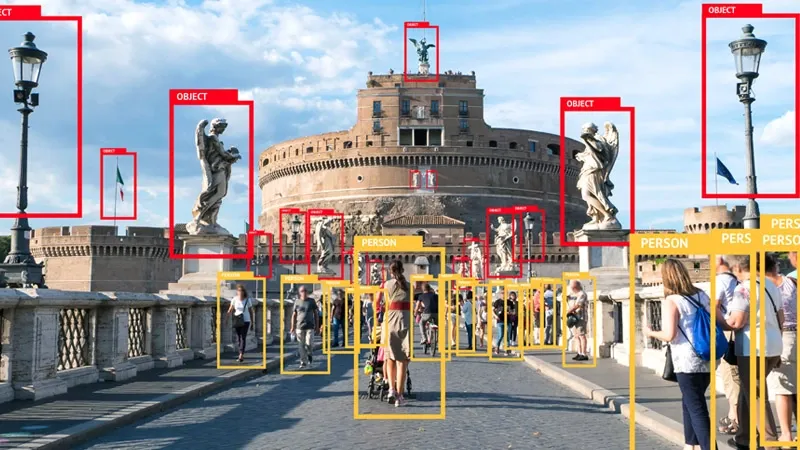
3. Video annotation
Similar to image annotation, video annotation makes use of tools like bounding boxes to identify motion frame-by-frame. For computer vision algorithms that carry out object location and tracking, the information gathered through video annotation is crucial. The systems can easily incorporate ideas like location, image noise, and detection and tracking thanks to video annotation.
4. Audio Annotation
All types of sounds, including speech, animal noises (growls, whistling, or chirps), and construction noises (breaking glass, scanners, or alarms), are transformed into structured formats during audio processing so they can be employed in machine learning. It is frequently necessary to manually convert audio files into text before processing them. The audio can then be tagged and categorized to reveal more details about it. Your training dataset is this audio that has been categorized.
5. Key-point Annotation
With key-point annotation, dots are added to the image and connected by edges. You receive the x and y-axis coordinates of important locations that are labeled in a specific order at the output. The method finds little objects and forms variations that share the same composition (e.g., facial expressions and features, parts of the human body and poses).

What are some of the Data labeling approaches?
1. In-house
Within an organization, specialists perform in-house data labeling, which guarantees the best possible level of labeling.
When you have sufficient time, human, and financial resources, it's the best option because it offers the highest level of labeling accuracy. On the other hand, it moves slowly.
For sectors like finance or healthcare, high-quality labeling is essential, and it frequently necessitates meetings with specialists in related professions.
2. Outsourcing
For building a team to manage a project beyond a pre-determined time frame, outsourcing is a smart choice. You can direct candidates to your project by promoting it on job boards or your business's social media pages. Following that, the testing and interviewing procedure will guarantee that only people with the required skill set join your labeling team. This is a fantastic approach to assembling a temporary workforce, but it also necessitates some planning and coordination because your new employees might need the training to be proficient at their new roles and carry them out according to your specifications.
3. Crowdsourcing
The method of gathering annotated data with the aid of a sizable number of independent contractors enrolled at the crowdsourcing platform is known as crowdsourcing.
The datasets that have been annotated are primarily made up of unimportant information like pictures of flora, animals, and the surroundings. Therefore, platforms with a large number of enrolled data annotators are frequently used to crowdsource the work of annotating basic datasets.
4. Synthetic
The synthesis or generation of fresh data with the properties required for your project is known as synthetic labeling. Generative adversarial networks are one technique for synthetic labeling (GANs). A GAN integrates various neural networks (a discriminator and a generator) that compete to discriminate between real and false data and produce fake data, respectively.
As a result, the new facts are very realistic. You can generate brand-new data from already existing datasets using GANs and other synthetic labeling techniques. They are hence good at creating high-quality data and are time-effective. Synthetic labeling techniques, however, currently demand a lot of computational power, which can render them quite expensive.
How can data labeling be carried out efficiently?
Building effective machine learning algorithms requires a lot of good training data. However, it can be expensive, complex, and time-consuming to produce the data for training required to develop these models.
The majority of models used today require data to be manually classified so that the model knows how to draw appropriate conclusions. This problem might be solved by proactively classifying data using a machine learning model, which would make labeling more effective.
In this process, a subset of your real data which has been labeled by humans is used to train a machine learning algorithm for categorizing data. When the labeling model is certain of its conclusions depending on what others have discovered thus far, it will automatically apply labels to the raw data.
The labeling model will forward the data to the humans for labeling in cases when it has less confidence in its results. The labeling model is then given the human-generated tags once more so that it can learn from them and become more adept at automatically identifying the following batch of raw data.
What factors impact the efficiency and accuracy of data labeling?
Although the accuracy of the words, as well as their quality, are frequently used interchangeably, we now know that they are not the same.
Reliability of data labeling: The degree to which the identified characteristics within data are compatible with actual environmental factors is gauged by how accurately they were assigned. This holds whether you're developing natural language processing (NLP) models or computer vision models (such as putting bounding boxes around items in street scenes) (e.g., identifying text for social sentiment).
Quality of data labeling: Accuracy over the entire dataset is what defines the quality of data labeling. Do all of the labelers produce similar-looking work? Are your datasets' labels consistently accurate? Whether numerous data labels are functioning at once, is essential.
Conclusion
Low-quality data will have two negative effects: first, during model training, and second, when your model uses the labeled data to guide decision-making in the future. You must train and validate high-performing models for machine learning using dependable, trustworthy data to design, verify, and ensure production for such models. If you are looking for ways to effectively manage the data labeling process with a smart workflow management system, then you should reach out to labellerr.
To know more such information, stay updated with us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
