

What is data labeling and how many different types of it are there?


In today’s technically advanced world, computer vision has enabled a lot of ways to automate processes. With different machine learning models, understanding and classifying data has become an easy task.
What human efficiency is incapable of, computer vision can do it very easily. It might take months to label 1000 images but your machine can do it in a much easier way-basically they annotate data.
You must have come across the term data labeling. Do you know what actual data labeling or data annotation is or, in many ways, you can label data? If not, then read out the complete article to get detailed information.
Data labeling in machines is the method of classifying unlabeled data (such as photos, text files, video, etc.) and giving one or more insightful labels to give the data structure so that a machine-learning model may learn from it.
For example, with the help of a label we can identify if a photograph shows a bird or an automobile, or in any audio which words were used/ spoken, or whether a tumor is visible on an x-ray. For a number of use cases, such as natural language processing, computer vision, and speech recognition, data labeling is necessary.
Table of Contents
What's the process of data labeling?
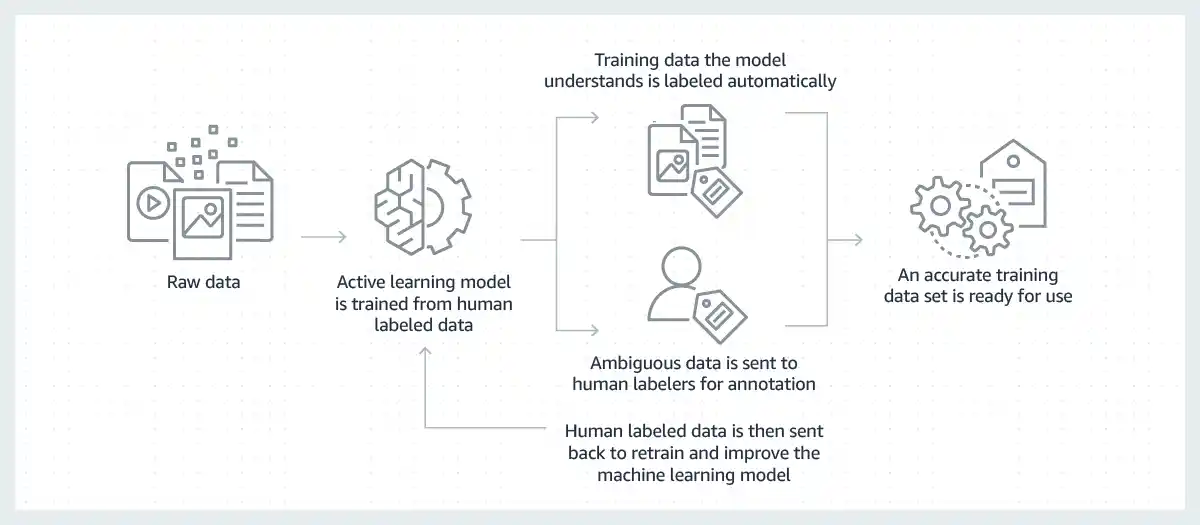
Processes for data labeling operate in the following ways:
Data gathering: Gathering of Raw data will be employed for training the model. In order to create a datasets that can be used to feed the model directly, this data must be cleaned and processed.
Data tagging: A number of ways of data labeling are used to label the data and link it to an appropriate context that the computer can utilize as a source of truth.
Quality control: The accuracy of the coordinate points for bounding boxes and keypoint annotations, as well as the precision of the tags for a given data point, are frequently used to assess the quality of the data annotations. Finding the accuracy rate of these annotations can be done with the use of QA tools like the Consensus mechanism and Cronbach's alpha test.
What are the different types of data labeling?
Computer Vision
Visual data present in the form of photos/videos are needed for computer vision, or research to enable computers to "see" the world around them. Based on the visual data we try to train the datasets model, and data annotation in computer vision might take many different forms.
Following is a list of typical data annotation kinds dependent on the task.
Image Classification: Adding a tag to the image under consideration is required for data labeling for image classification. The number of training that the model will categorize is determined by the total amount of distinct tags in the database.
Problems with classification can be further broken down into:
- Categorization into binary classes (that comprise only two tags)
- Classifiers with numerous levels (that comprise multiple tags)
Additionally, multi-label classification—which refers to each image containing more than one tag—can also be observed, especially in the case of disease diagnosis.
Separating items in photographs from their backdrop as well as other objects within the same image is the duty of a computer vision algorithm during image segmentation. In most cases, this entails a pixel map of the very same dimension as the image, with 1 in which the object is shown and 0 in which an annotation has not yet been made.
Pixel mappings for every object are combined channel-wise and utilized as the underlying data for the model in order to segment several objects in the same image.
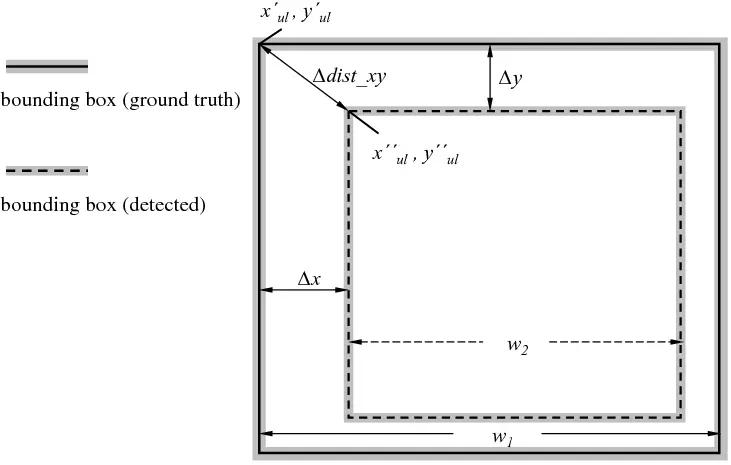
Object detection is the process of using computer vision to identify things and their positions. Each object is tagged using bounding boxes in object detection, which is a fundamentally different process from image classification.
The smallest rectangular area that encloses an object in a picture is known as a bounding box. Typically, bounding box annotations come with tags that give each bounding box a label in the image.
The dimensions from the bounding boxes and also the tags associated with them are often saved in a distinct JSON file in dictionary format, with the picture ID serving as the dictionary's key.
Pose estimate: Pose estimation is the process of estimating a person's pose based on an image using computer vision techniques. Pose estimate works by finding critical body points and correlating them to determine the pose. Thus, important portions of an image would serve as the pose estimation model's equivalent ground truth. This would be straightforward coordinate data that has been labeled with the aid of tags, in which each coordinate indicates the location of a specific key point in the corresponding image that has been identified by the tag.
Natural Language Processing
The field of computer science known as "natural language processing" (NLP) is more particularly the field of "artificial intelligence" (AI) that is concerned with providing computers the capacity to comprehend written and spoken words in a manner similar to that of humans.
NLP blends analytical, computer vision, and deep learning models with computational linguistics—rule-based modeling of human language. With the use of these technologies, computers are now capable of processing human language in the format of text or audio data and fully "understanding" what is being said or written, including the speaker's or writer's intentions and sentiments.
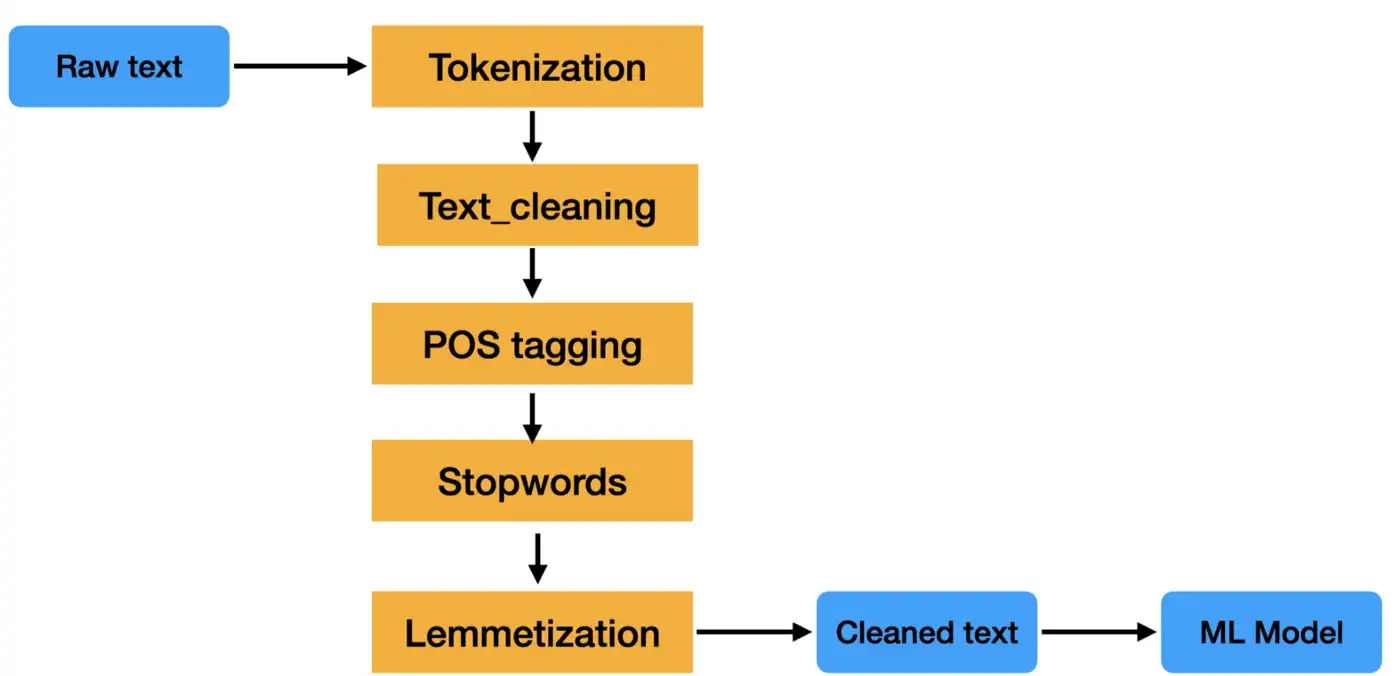
Computer programs that translate text between languages, reply to spoken instructions, and quickly summarize vast amounts of text—even in real-time—are all powered by NLP. You've probably used NLP in the form of voice-activated GPS devices, digital assistants, speech-to-text translation programs, customer service chat-bots, and various other consumer conveniences. The use of NLP in corporate solutions, however, is expanding as a means of streamlining business operations, boosting worker productivity, and streamlining mission-critical business procedures.
Audio annotation
All types of sounds, including speech, animal noises (growls, whistling, or chirps), and construction noises (breaking glass, scanners, or alarms), are transformed into structured formats during audio processing so they can be employed in machine learning. It is frequently necessary to manually convert audio files into text before processing them. The audio can then be tagged and categorized in order to reveal more details about it. Your training datasets is this audio that has been categorized.
Conclusion
Data labeling is a crucial component of data pre-treatment for Machine Learning, especially for supervised learning, where input and output data are both classified and labeled to serve as a learning foundation for subsequent data processing. Human error in data annotation frequently prevents these models from operating at their peak capacity, lowering prediction accuracy as a whole. If you are dealing with supervised learning, then data labeling becomes crucial.
If you are working and dealing with supervised learning and are looking to automate the annotation process, then reach out to Labellerr.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
