

Sakana Fugu: The Model That Outsmarts Claude Fable 5
Sakana Fugu introduces a new AI paradigm: a learned multi-agent orchestration system that coordinates multiple frontier models through TRINITY and Conductor architectures, delivering state-of-the-art performance while improving resilience, flexibility, and AI sovereignty.


The AI world spent years chasing a single dream: one giant model that knows everything. Train it bigger. Feed it more data. Hope it handles whatever you throw at it.
That dream has a fragile side. On June 12, 2026, the US Department of Commerce placed export controls on Anthropic's Fable 5 and Mythos models. Overnight, teams that had built on those APIs lost access. No migration path. No warning.
Sakana AI had a different idea already in motion.
On June 22, 2026, the Tokyo-based lab released Sakana Fugu, a multi-agent orchestration system packaged as a single model. It coordinates a pool of frontier LLMs behind one OpenAI-compatible endpoint.
The result is a system that, on Sakana's own benchmarks, stands shoulder-to-shoulder with the export-controlled Fable 5 and Mythos Preview, without touching either of them.
What Makes Fugu Different from a Simple Router

Difference between Fugu and simple router
Most people hear "multi-agent system" and think of a glorified if-else dispatcher. Fugu is not that.
The core innovation is learned orchestration. Traditional multi-agent systems use hand-designed workflows, if task X, call model Y. Fugu instead uses a trained 7-billion-parameter conductor model that learns which models to activate, how agents should communicate, and how to combine their work.
Fugu is itself a language model. Not a wrapper or a router built with if/else logic, a trained orchestrator that has learned when to delegate versus solve directly.
This distinction matters. A gateway picks a single model and routes your prompt to it. Fugu operates on a fundamentally different paradigm. Rather than making a one-shot routing decision, it breaks a query down, interleaves reasoning with delegation, and dynamically assigns sub-tasks to multiple models in parallel or sequence before synthesizing a final output.
Architecture: TRINITY + Conductor
Fugu's internals rest on two peer-reviewed papers accepted at ICLR 2026.

Architecture
TRINITY
TRINITY is a roughly 0.6B-parameter coordinator, evolved with CMA-ES, that assigns Thinker, Worker, and Verifier roles across a pool of much larger worker models.
Each incoming task gets decomposed. A Thinker model reasons about the approach. A Worker model executes. A Verifier model checks the output. TRINITY uses a lightweight evolved coordinator that assigns models to Thinker, Worker, or Verifier roles across multiple turns, adapting dynamically to the task.
Conductor
Conductor is a 7B model trained with reinforcement learning to discover natural-language coordination strategies, and it can call itself recursively to scale compute at test time. The orchestrator is tiny; the heavy lifting is delegated to a swappable pool of frontier models behind the scenes.
Recursive self-calling enables a new form of test-time scaling: Fugu reads its own prior output and launches corrective workflows when a first attempt falls short.
Put simply: TRINITY assigns the roles. Conductor learns how those roles talk to each other. Fugu ships both as one API call.
The Two Tiers: Fugu vs Fugu Ultra
Sakana AI is offering two variants to cater to different operational workloads. Fugu is a high-speed, low-latency model optimized for everyday tasks, designed to act as the default engine for interactive chatbots and coding environments like Codex. Fugu Ultra is the flagship tier engineered for complex, high-stakes tasks such as AI research, cybersecurity analysis, and multi-step patent investigations.
Both share the same OpenAI-compatible API. Switching between them is a single parameter change. The agent pool in Fugu Ultra is deeper and fixed. The standard Fugu tier lets you opt specific models out for compliance.
Benchmark Results
This is where Fugu makes its boldest claim.

Fugu vs Fable 5, Mythos Preview, GPT-5.5, Opus 4.8, Gemini 3.1 Pro across coding, reasoning, science, and agentic evals.
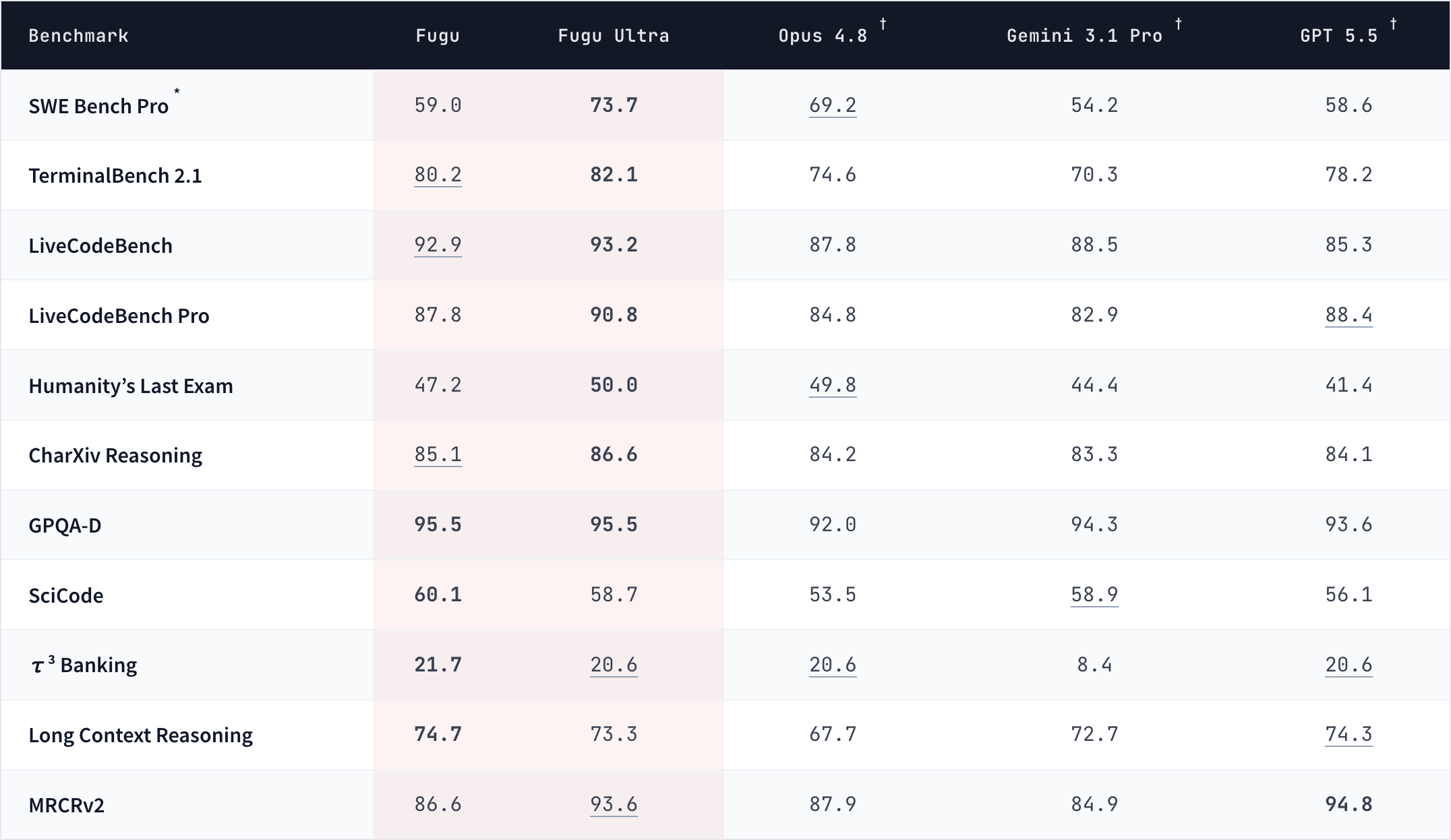
per-benchmark scores
Benchmark source
Here are the key numbers from Sakana's official report:
On SWE-Bench Pro, a demanding software engineering benchmark, Fugu Ultra scores 73.7, ahead of Claude Opus 4.8's 69.2 and GPT-5.5's 58.6. On LiveCodeBench, Fugu scores 92.9 and Fugu Ultra 93.2, both ahead of Gemini 3.1 Pro's 88.5. On Humanity's Last Exam, one of the hardest general-knowledge benchmarks available, Fugu Ultra reaches 50.0, essentially matching Opus 4.8's 49.8.
Fugu Ultra also exceeds Fable 5 on LiveCodeBench (Fugu Ultra: 93.2, Fugu: 92.9, Fable: 89.8), and beats Mythos Preview on GPQA-Diamond, a test of 198 graduate-level multiple-choice questions in biology, physics, and chemistry (Fugu Ultra: 95.5, Fugu: 95.5, Mythos Preview: 94.6).
Fugu Ultra leads on GPQA-D (95.5), LiveCodeBench (93.2), LiveCodeBench Pro (90.8), and TerminalBench 2.1 (82.1). But the wins are not universal: Fable 5 tops SWE-Bench Pro and Humanity's Last Exam (53.3); GPT-5.5 leads the MRCRv2 long-context-recall test (94.8); and Opus 4.8 edges out on the CTI-REALM cybersecurity benchmark (69.6).
One honest quirk: on SciCode and a few others, the balanced Fugu actually scores higher than Fugu Ultra, so more orchestration is not always better.
All baseline scores for competing models are provider-reported. Independent replication on long-horizon agentic tasks is still pending.
What Real Users Built During Beta
Sakana ran a beta with close to 500 early users. The results from real workflows matter more than benchmark tables.
Fugu Ultra found over 20 issues in a production codebase where competing single models found only 3. The multi-agent approach catches bugs across different categories simultaneously.
One enterprise executive noted something unexpected. Raw output quality is on par with top frontier models, but Fugu showed unusually strong persona stability across long sessions, holding its identity where other models drift. For agent products, that may matter more than raw benchmark scores.
A cybersecurity engineer reported that given one scoped instruction, Fugu drove a full security assessment end-to-end, recon, XSS/SQLi checks, auth review, and a clean report with evidence and retest steps, staying inside scope and avoiding destructive actions.
Sakana also ran six structured demos. In automated ML research, Fugu Ultra ran 123 experiments and found the best reported BPB score in its evaluation. In Japanese historical-document recognition, it reports a normalized edit distance of 0.80. In a Rubik's Cube coding task, the generated solver completed all 300 test cases.
The Geopolitical Angle: AI Sovereignty
Sakana does not frame Fugu as just a better model. It frames it as infrastructure resilience.
The timing is pointed. Anthropic's Fable 5 and Mythos 5 have been inaccessible globally since June 12 under a US Department of Commerce export control directive. Teams that built on those APIs had their production systems disrupted with no rollback path.
Fugu's agent pool is explicitly swappable. If a single provider restricts access, Fugu dynamically routes around the disruption. Over time, Fugu will naturally grow by incorporating newer, more efficient models, including Sakana's own.
The architecture compounds naturally: every new capable model that enters the open ecosystem potentially enters Fugu's pool. Unlike a monolithic model that requires an expensive retraining cycle to improve, Fugu improves incrementally as the broader ecosystem does.
For teams in finance, healthcare, or government infrastructure, where a sudden API blackout is catastrophic, this is not a marketing pitch. It is an engineering requirement.
Pricing and Availability
Teams can opt for monthly subscription allowances: a Standard tier at $20/month for lightweight workflows, a Pro tier at $100/month providing 10x standard usage, and a Max tier at $200/month offering 20x usage for continuous, long-running tasks.
Fugu Ultra runs $5 per million input tokens, $30 per million output tokens, and $0.50 for cached input. These rates increase to $10, $45, and $1.00 respectively for context windows above 272K tokens.
When multiple agents are active, fees are never stacked: you pay a single rate based on the top-tier model involved. But be aware that internal orchestration tokens, the background calls between agents, count toward billing at standard rates.
Fugu is restricted from operating within the EU and EEA while Sakana works to align its black-box data routing architecture with GDPR regulations. A free second month is available for subscribers who join before July 31, 2026.
Caveats Worth Knowing
Fugu is genuinely novel. It is also worth scrutinizing before you commit production workloads.
Fugu Ultra's pool is fixed, there's no opt-out of individual models. You can filter the standard Fugu tier, but Ultra runs the full pool regardless of your compliance preferences.
The most defensible reading of the benchmarks: Fugu Ultra looks impressive against public frontier baselines, but the Fable/Mythos comparison is mixed. It depends heavily on which benchmark, which Anthropic model version, and which evaluation configuration you use.
There are three things to track: whether Fugu's benchmark numbers survive independent replication on agentic and long-horizon tasks, the latency and cost overhead of chaining API calls across providers, and what happens to Fugu's positioning if Fable 5's access restrictions lift.
Conclusion
The AI scaling race was always a bet that one model, trained hard enough, would beat everything else. That bet is cracking, not because the models are bad, but because the infrastructure around them is unstable.
The gap between "what frontier capability exists" and "what developers can legally access" has rarely been this wide, and Fugu targets it directly: by orchestrating models not subject to export restrictions, it offers Fable 5-tier output to a geography-agnostic user base.
Strip the marketing and Fugu is still notable for one reason: orchestration is becoming a product category, not just a pattern you wire up by hand. A learned coordinator that assigns roles and scales its own compute is a real step past static agent graphs.
Sakana Fugu is not the last word. But it is the clearest signal yet that the future of AI performance is not a single, bigger model, it's a smarter system that knows which model to call.
FAQs
Q1. What is Sakana Fugu and how is it different from a traditional AI model?
Sakana Fugu is a multi-agent orchestration system that coordinates multiple frontier AI models through a trained conductor model. Unlike traditional AI systems that rely on a single model, Fugu dynamically delegates tasks, verifies outputs, and combines results to improve performance.
Q2. How does Fugu's TRINITY architecture work?
TRINITY assigns specialized roles to AI models: Thinker, Worker, and Verifier. The Thinker plans the solution, the Worker executes the task, and the Verifier checks the output. This coordinated workflow helps improve accuracy and reliability.
Q3. Why is Fugu important for AI sovereignty and infrastructure resilience?
Fugu's model pool is swappable, allowing organizations to continue operating even if a specific AI provider becomes unavailable due to regulations, export controls, or service disruptions. This reduces dependency on any single model vendor.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
