

RoBERTa: A Robustly Optimized BERT Pretraining Approach

Keeping up with the latest developments in the rapidly expanding field of natural language processing is challenging. But fear not—a strong ally is on hand to completely alter the way we think about language comprehension. Welcome to RoBERTa, the robustly optimized BERT pretraining approach set to revolutionize NLP.
Join us as we unravel the mysteries of RoBERTa and learn why it's destined to become the cornerstone of language models, whether you're a researcher, developer, or simply interested in the leading edge. Get ready to explore a world of unmatched language comprehension, sophistication, and optimization.
What is RoBERTa?
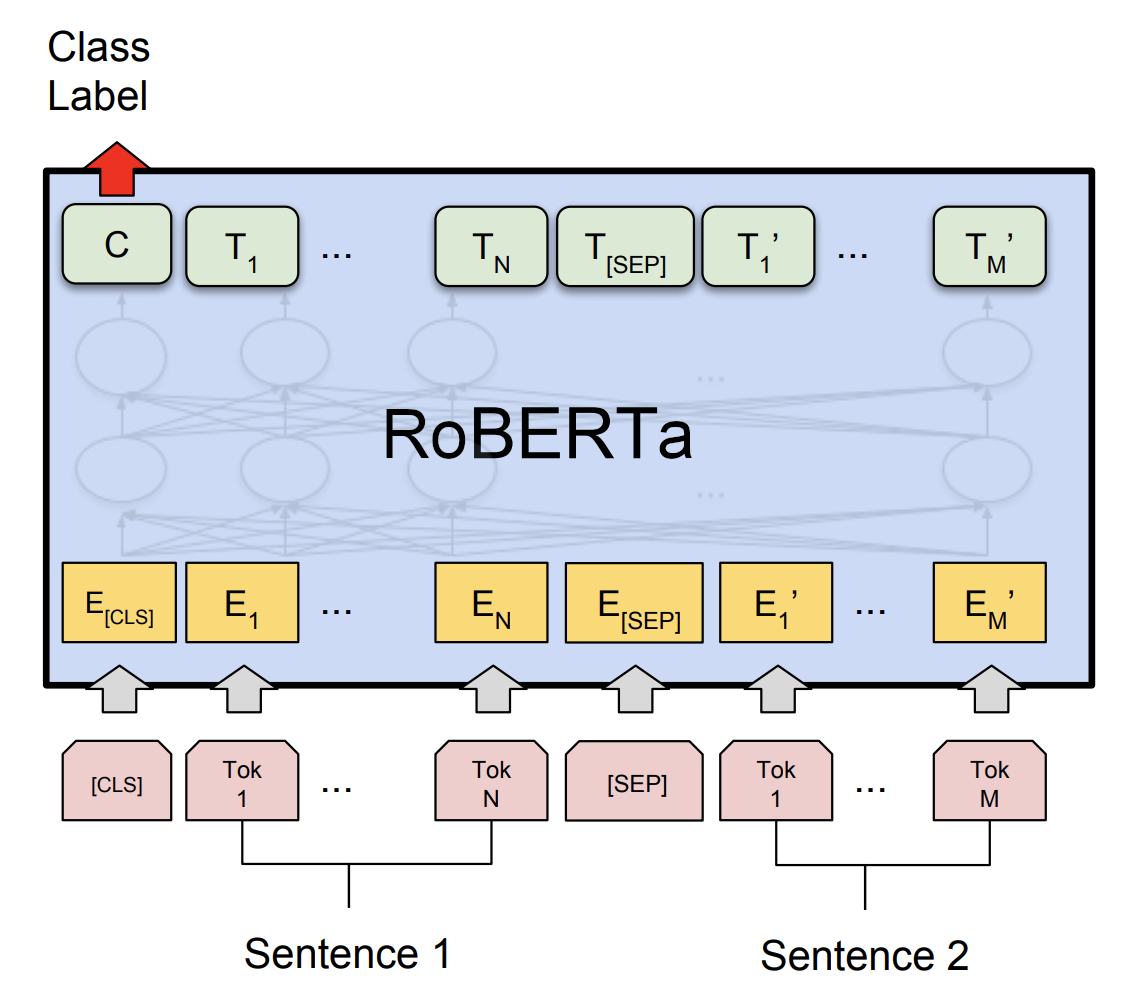
RoBERTa is a transformer-based language model that processes input sequences and produces contextualized representations of the information by using self-attention. Many natural language processing (NLP) tasks perform better thanks to our substantially optimized BERT pre-training technique.
RoBERTa expands on BERT's language masking technique, which teaches the computer to anticipate purposefully buried text within otherwise unannotated material. It is a self-supervised pre-trained model on a sizable corpus of English data.
Use cases of RoBERTa

Natural language processing (NLP) tasks like text categorization, sentiment analysis, question-answering, and language modeling have all been done using RoBERTa. On several NLP tasks, it has been demonstrated to perform better than BERT and other cutting-edge models.
Through the use of masked language modeling, RoBERTa can comprehend language more deeply and excel at tasks like social sentiment analysis. RoBERTa has also been used in conjunction with the Huggingface library Transformers to classify text. Overall, RoBERTa is a flexible model that may be applied to a variety of NLP tasks.
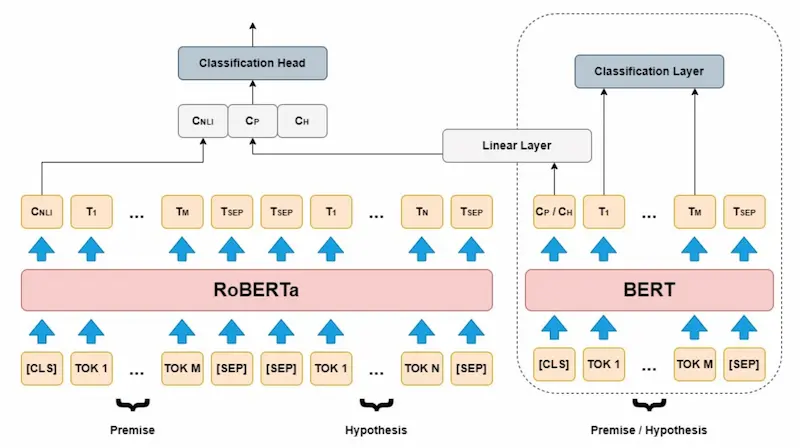
How does RoBERTa's performance compare to other NLP models on specific tasks?
On a range of natural language processing (NLP) tasks, such as text categorization, question answering, and natural language inference, RoBERTa has been demonstrated to beat BERT and other cutting-edge models. On a variety of NLP tasks, RoBERTa outperforms BERT. It can perform well in downstream tasks including dialogue systems, question answering, and document classification, and has been used as a basic model for various NLP models.
DeBERTa, a new model architecture that enhances the BERT and RoBERTa models, has been presented as an alternative to RoBERTa-Large. Overall, RoBERTa outperforms previous models like BERT in terms of performance and is a highly versatile and reliable model that can be tailored for particular NLP tasks.
Technology behind RoBERTa
RoBERTa is a transformer-based language model that creates contextualized representations of words in sentences by processing input sequences using self-attention.
It is a variation of the BERT model, which was created by Facebook AI researchers. 160GB of text, more than 10 times the size of the dataset used to train BERT, was the size of the dataset used to train RoBERTa.
Additionally, RoBERTa employs a dynamic masking strategy during training to aid in the model's acquisition of more reliable and adaptable word representations.
By randomly masking some words in the training data, a process known as masked language modeling was used to train RoBERTa. The model then had to anticipate the missing words based on the context.
RoBERTa employs a deeper Transformer model with 24 transformer layers instead of 12 and a larger training dataset than BERT, totaling over 160 million phrases.
How Roberta can be utilized for AI model training?
RoBERTa is a transformer-based language model that processes information by using self-attention. It has been demonstrated to perform better on a range of NLP tasks, including language translation, text categorization, and question answering, than BERT and other cutting-edge models.
RoBERTa can be used to train AI models by being fine-tuned for a particular NLP task. By training it on a labeled dataset of text with associated sentiment labels, for instance, it can be improved on a sentiment analysis job. RoBERTa is a popular option for research and commercial applications since it can be used as a basic model for many other effective NLP models.
How can RoBERTa be fine-tuned for Specific NLP tasks?
By training RoBERTa on a labeled dataset of text that has corresponding labels for the relevant task, specific NLP tasks can be refined for RoBERTa. For instance, a dataset of text with accompanying sentiment labels can be used to train RoBERTa for a sentiment analysis task. The pre-trained tokenizer used for RoBERTa can tokenize the text.
The AutoTokenizer class from the transformers library enables the loading of the pre-trained tokenizer used by RoBERTa. Using Hugging Face transformers, RoBERTa can also be adjusted for multiclass text classification problems. On many NLP tasks, RoBERTa has been demonstrated to outperform BERT and other cutting-edge models.
Here are some best practices for fine-tuning RoBERTa for NLP tasks:
To fine-tune RoBERTa for NLP tasks, some best practices should be followed. These include expanding the size of the fine-tuning dataset and the number of epochs, experimenting with various fine-tuning methods, including next-sentence prediction, full-sentences, and doc-sentences methods, and tokenizing the text using the pre-trained tokenizer used for RoBERTa.
Due to changes made to the pre-training process, such as training the model for longer with larger batches and applying dynamic masking during training, RoBERTa has been demonstrated to outperform BERT on several NLP tasks.
In NLP, it is common practice to fine-tune massive pre-trained models on downstream tasks, and RoBERTa has been employed for multiclass text classification tasks utilizing Hugging Face transformers.
How can Roberta be used in Computer Vision Tasks?

The use of RoBERTa is possible in computer vision applications like Vision Question Answering (VQA) systems. To obtain exceptional performance in VQA, RoBERTa, and the Vision Transformer (ViT) model can be integrated. However, RoBERTa has not been specially optimized for computer vision tasks and is primarily intended for problems involving natural language processing.
In light of other models created especially for computer vision problems, such as convolutional neural networks (CNNs) and the Transformer-based ViT model, it might not be the best option for those tasks.
Conclusion
In conclusion, the development of RoBERTa has revolutionized the discipline of natural language processing. It has upped the standard for language understanding models with its strong optimization techniques and pretraining strategy. RoBERTa has demonstrated its effectiveness and adaptability, from enhanced performance on numerous NLP tasks to its capacity to manage large-scale training.
RoBERTa is a tribute to the amazing progress being made in language modeling as we keep pushing the limits of AI and NLP. It has unquestionably played a significant role in determining the future of NLP applications thanks to its resilience and optimization. So buckle up and prepare to discover the opportunities that RoBERTa opens up as we enter a new era of language processing.
To explore more such amazing content, take a look here!
FAQs
Q 1: What is RoBERTa?
"Robustly Optimised BERT Pretraining Approach" is known as RoBERTa. It is a BERT (Bidirectional Encoder Representations from Transformers)-based natural language processing model that was developed to enhance pre-training and deliver more precise results.
Q 2: How does RoBERTa differ from BERT?
The RoBERTa model, which is a modification of the BERT model's next sentence prediction task, employs longer pre-training and larger batches. RoBERTa enhances performance in a variety of downstream natural language processing tasks by including additional training data and utilizing dynamic masking during pre-training.
Q 3: What tasks can RoBERTa be used for?
RoBERTa has proven effective in various natural language processing tasks, such as question answering, text classification, and language modeling.
Q 4: Is RoBERTa a supervised or unsupervised model?
As an unsupervised model, RoBERTa is pre-trained on a significant volume of unlabeled data to understand language's fundamental structure and patterns. For certain downstream applications, it may then be fine-tuned on smaller labeled datasets.
Q 5: Where can I find pre-trained RoBERTa models?
RoBERTa models that have already been trained have been made available by Hugging Face and are accessible via the Python Transformers module. These models can be improved to do certain tasks or be applied to transfer learning in other natural language processing initiatives.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
