

Supervised vs. Unsupervised Learning: Choosing the Right Path for Your Data Analysis
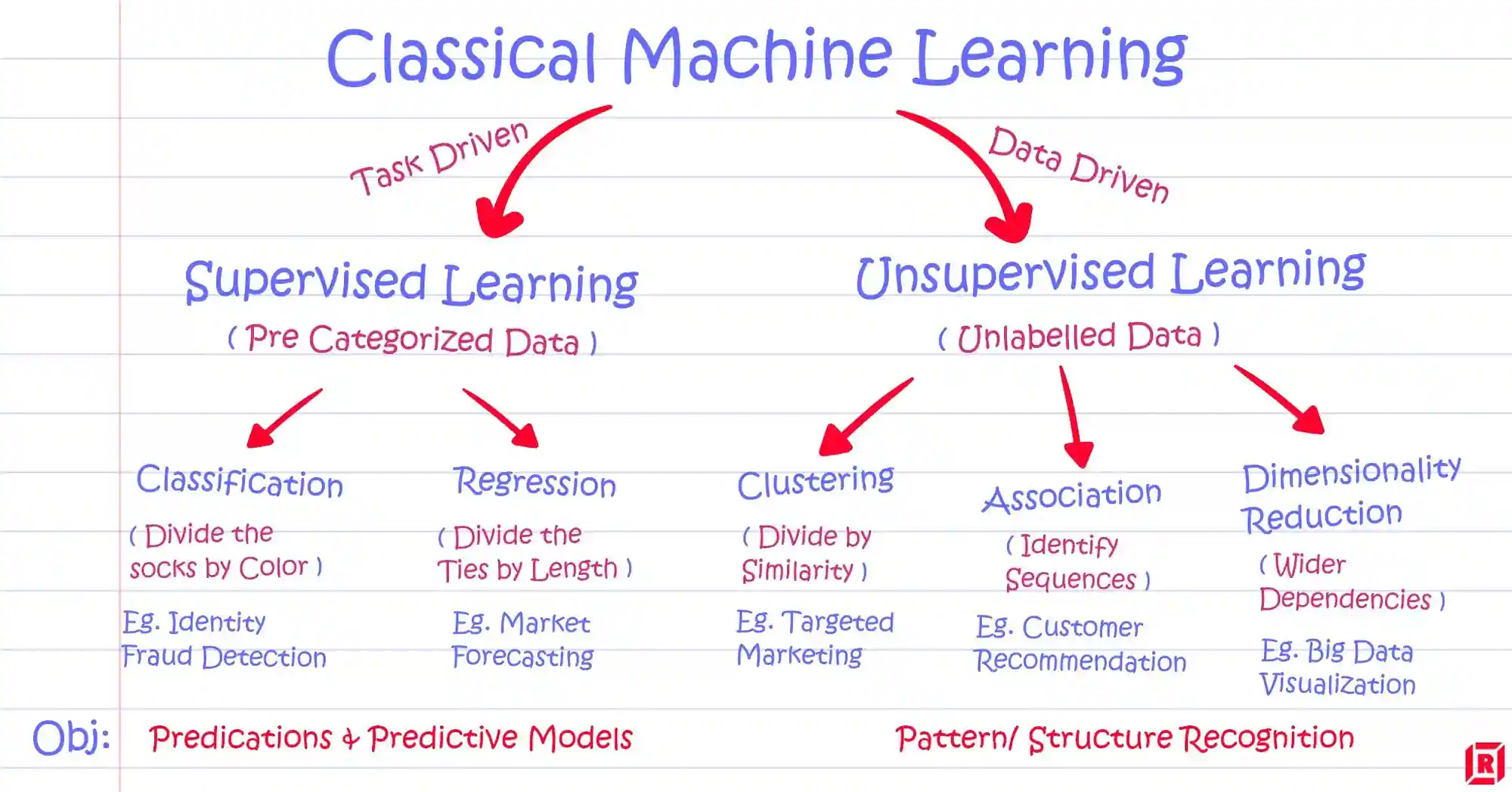
Supervised learning uses labeled data for predictive tasks like spam filtering or credit scoring, while unsupervised learning explores unlabeled data to identify patterns, aiding applications such as customer segmentation and anomaly detection

Supervised Learning and Unsupervised Learning are two well-known techniques that have dominated the large field of data analysis. Modern machine learning is built on these two techniques, which give us the ability to draw conclusions, forecast the future, and identify patterns in large datasets. Just as an essay paper writing service helps students structure and present complex ideas clearly, understanding the main differences between unsupervised and supervised learning is essential whether you're a data enthusiast or a business professional starting out on a data-driven journey.
Understanding the main differences between unsupervised and supervised learning is essential whether you're a data enthusiast or a business professional starting out on a data-driven journey.
Come along as we embark on an exciting investigation of these two effective methodologies, their distinctive features, and how to pick the best route for your data analysis adventure. Let's explore supervised and unsupervised learning in-depth, where data holds the key to revealing priceless knowledge.
First, let’s begin by exploring in detail about machine learning
What is Machine Learning?
Machine learning is a branch of artificial intelligence (AI) that focuses on the mathematical formulae and statistical models that computer systems employ to carry out operations without being explicitly programmed.
The key benefit of machine learning is its capacity to allow computers to work at their peak without explicit instructions.
Instead, they can utilize machine learning to take what they have learned from the present context and generalize it to new tasks that modify their programs automatically.
Due to the enormous amount of datasets being produced today, there is a commensurate demand across different sectors for machine learning to retrieve pertinent data capable of guiding wise business decisions.
Machine learning is particularly suited for creating significant advancements in the efficiency of distribution networks, energy usage, as well as other areas with a financial impact at the corporate level.
Now, moving on, let’s discuss Supervised Learning and Unsupervised Learning.
Supervised vs. Unsupervised Learning: Understanding the Key Differences
Here, we are going to discuss in detail the difference between Supervised and Unsupervised learning:
What is Supervised Learning?
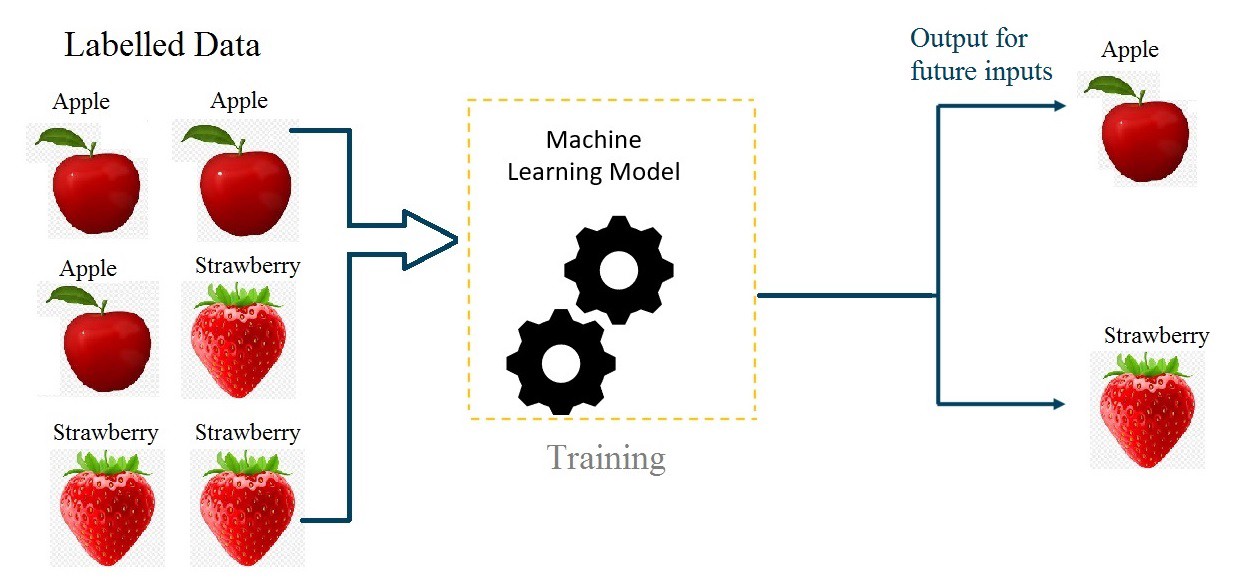
The supervised learning technique trains a model to recognize the relation between input data and associated output labels. It entails giving the model a dataset that has been labeled, with each example containing input data and the ideal output label connected to that data.
For the model to generalize from the provided examples and be able to precisely predict the output labels for brand-new, untried data, supervised learning is used.
In supervised learning, the model optimizes its internal parameters based on the input labels to discover patterns and relationships in the training data. These variables control the transformation and mapping of the input data to the output labels. Once trained, the model can use fresh input data to predict or categorize objects based on previously discovered patterns.
Types of Supervised Learning are:
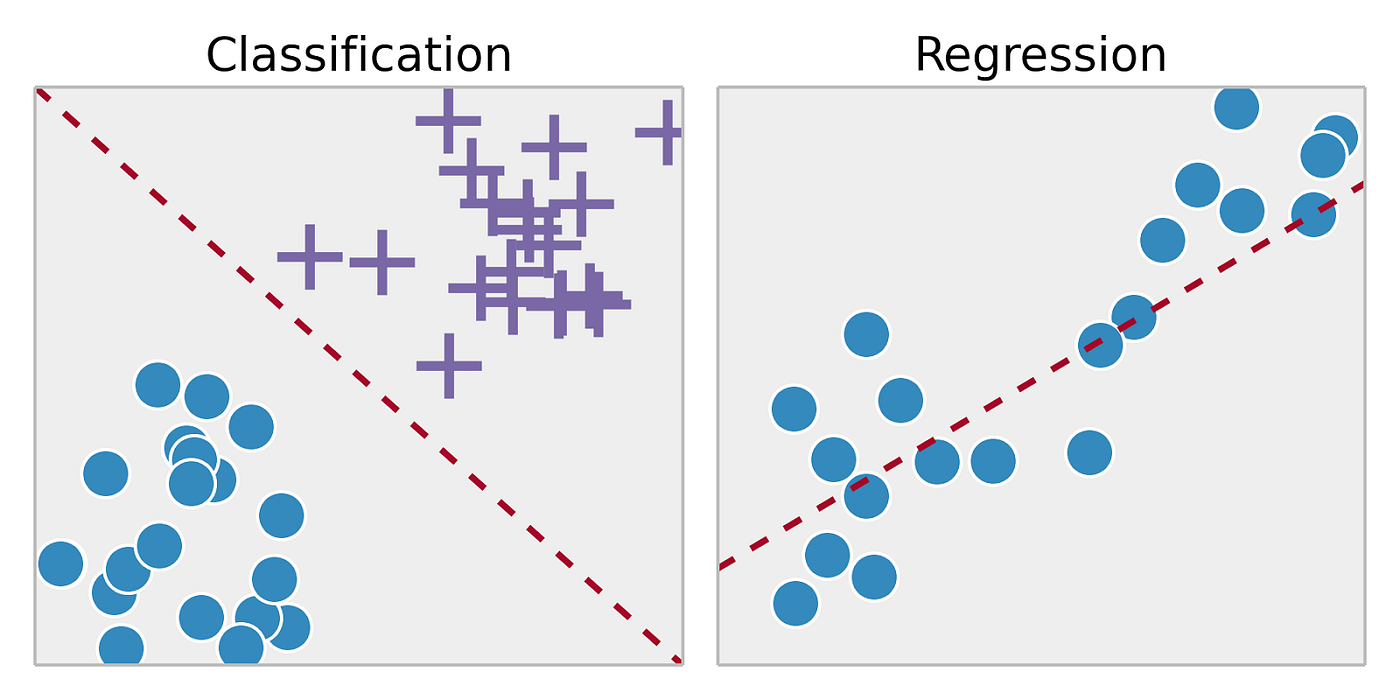
Classification: Predicting a discrete or categorical output label is the aim of classification problems. The model can be trained, for instance, to identify each animal image as a cat, dog, or bird given a collection of animal images.
Regression: In tasks involving regression, the objective is to forecast a continuous or numerical output value. The process involves creating a mathematical model (y = mx + b) that finds the optimal relationship between input variables and output values. For practical implementation, you can use statistical software, programming libraries, or linear regression calculator to compute the model and determine the best-fit relationship. For example, the model can be trained to predict the price of a property based on its parameters like size, number of rooms, and location given past data on housing prices.
There are various supervised machine learning techniques such as:
- Linear regression: To predict continuous values, use linear regression.
- Logistic regression: Using logistic regression, one can forecast binary outcomes.
- Decision Trees: for tasks involving regression and categorization
- Random Forest: an aggregate approach that increases stability and accuracy
- Support Vector Machine (SVM): used for regression and classification
- Naive k-Nearest Neighbors (k-NN): for non-parametric regression and classification Bayes' theorem: Based on Bayes' theorem for pattern detection and forecasting, use neural networks
Let’s Understand Better With an Example
A pupil would learn under supervision much like they would from a teacher. The teacher serves as a mentor or a reliable information source that the student may rely on to direct their learning. The student's mind can likewise be viewed as a computational device.
Let's imagine that these children are taking a trip to the neighborhood zoo to learn more about animals. Each animal is demonstrated to the class by the teacher, who then gives each pupil its label or name.
When a student misidentifies an animal while trying to identify it, the teacher corrects them by giving them the right tag. The pupil starts to form a mental model or pattern as the teacher proceeds to train them.
Similarly, this happens in supervised learning training, used for training machines. Using the training data supplied by a supervisor, computational engines develop the ability to spot patterns and create models. Based on what it learned from the training data, the computational engine may forecast a label for an uncertain or unlabeled element when it is presented with one.
Based on what the computational engine has acquired from the training data, it predicts a label.
Also Read: How AI-powered Data Labeling Tools Help Faster Development?
What is Unsupervised Learning?
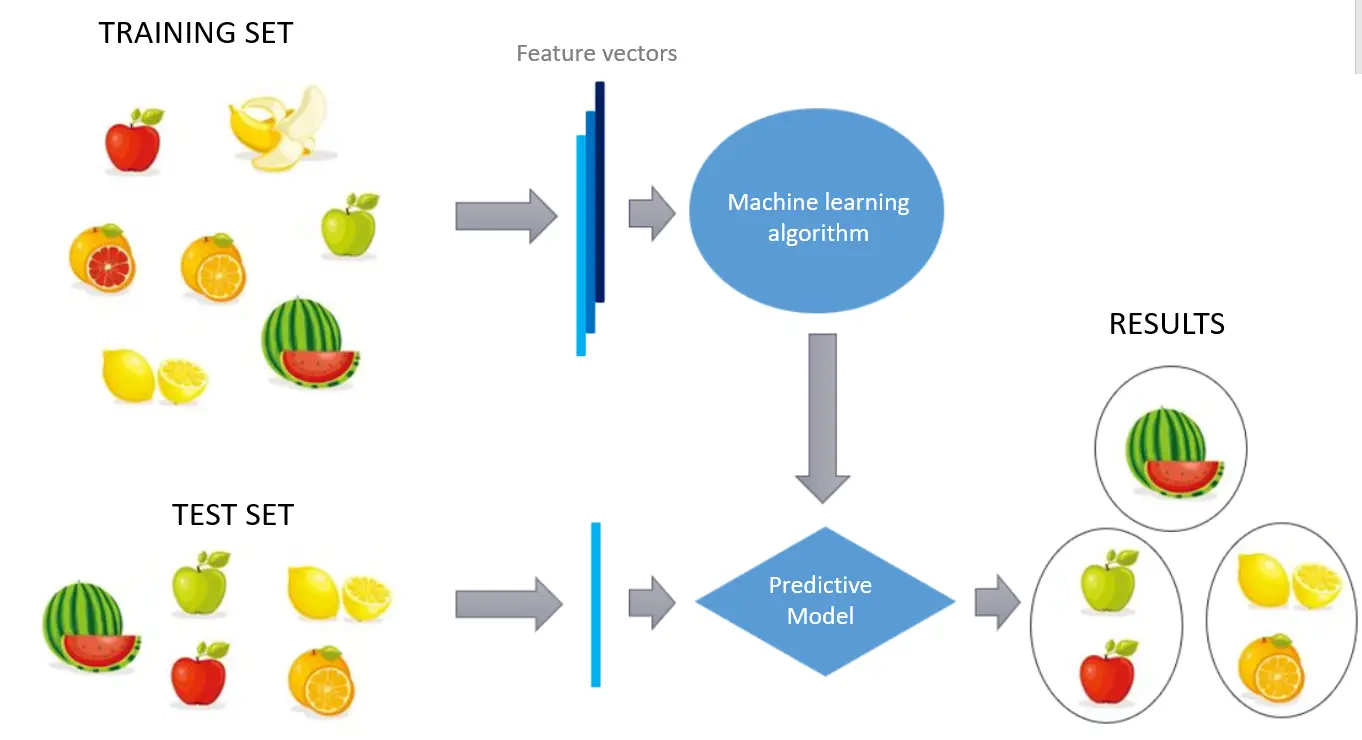
Unsupervised learning seems to have no correct answers and is no supervisor. Here, information is not ordered but rather categorized according to differences and similarities in unsupervised learning.
In other terms, In unsupervised learning, a model must search for patterns in a dataset without labels and with little to no human supervision. Unlabeled datasets are analyzed and clustered using this technique.
To sum up, the major distinction is that input data in supervised learning will have labels, whereas no labels will be present in unsupervised learning.
Types of Unsupervised Machine Learning Techniques
Clustering and association issues are further divided into subgroups of unsupervised learning challenges.
Clustering
Whenever it pertains to unsupervised learning, the concept of clustering is crucial. The primary focus is on identifying a structure or pattern in a set of uncategorized data. If there are any natural clusters or groupings in your data, clustering algorithms will analyze them and locate them. You can alter the number of clusters your algorithms should find as well. You can change the level of detail in these groups.
Association
You can create associations between data elements in sizable databases using association rules. With this unsupervised method, fascinating connections between variables in huge databases are found. Example-People who purchase a new home, for instance, are more likely to purchase new furniture.
Key Differences Between Supervised and Unsupervised Learning
The following are some of the key differences between supervised and unsupervised learning:
- Supervised machine learning requires labeled data.
- Unsupervised learning is typically used to identify correlations among datasets, whereas supervised machine learning is typically used to categorize data or generate predictions.
- Due to the requirement for labeled data, supervised learning requires significantly more resources.
Applications of Supervised Learning
Supervised Learning is a machine learning technique that creates predictive data models using labeled input and output training data. Here are a few applications of supervised learning:
- Classification Challenges
We frequently produce classes or categories as an output from categorization activities. This could entail making an educated judgment as to what data represents (a car or a bus) or whether it will rain today.
2. Problems with Regression
Continuous data are linked with regression. In regression, the anticipated output values are precise numerical values. It deals with a variety of difficulties, such as estimating a property's price or the trend in stock prices at a particular time.
3. Bioinformatics
To categorize genes and proteins, bioinformatics use supervised learning.
4. Spam filters
Supervised learning is used to recognize and eliminate spam emails.
5. Systems for Detecting Fraud
Supervised learning is used to identify fraudulent financial services transactions. Systems for recognizing photos and classifying them into distinct categories employ supervised learning.
6. Risk Assessment
To reduce the risk portfolio of the companies, supervised learning is used to evaluate the risk in the financial services or insurance domains.
7. Visual Recognition
Object recognition in images and videos is done through supervised learning.
8. Credit Scoring
Supervised learning is used in finance to evaluate a potential borrower's creditworthiness while precisely estimating the likelihood that they would make late or missed payments.
9. Health
Based on a patient's medical history and treatment regimen, supervised learning can assist forecast whether or not a patient will pass away from heart failure. A more recent example is cancer cell identification, where machine learning techniques are employed to separate malignant cells from healthy cells.
Applications of Unsupervised Learning
Unsupervised learning is used to analyze and group unlabeled datasets. Here are a few frequent uses for unsupervised learning:
- Clustering
Based on their commonalities, related things can be grouped together using unsupervised learning. This has numerous applications, including the segmentation of customers and products.
2. Visualization
Unsupervised learning can produce diagrams, images, graphs, charts, and other types of informational visualizations. Unsupervised learning, for instance, might be used by a football coach to quickly find all the statistics pertaining to their team's performance in a competition.
3. Dimensionality Reduction
Dimensionality reduction is the process of reducing the number of features in a dataset via unsupervised learning. In anomaly detection, where it's critical to spot odd patterns in data, this can be helpful.
4. Finding Association Rules
Data patterns and correlations can be found through unsupervised learning. This is helpful in recommendation systems since it's crucial to make recommendations for goods and services that are relevant to the interests of the consumer.
5. Anomaly Detection
Unsupervised learning can be used to find anomalies in data by looking for odd patterns. This can be helpful in the identification of fraud since it's crucial to spot transactions that are out of the ordinary.
Wrapping up!
Anyone who appreciates taking on really difficult issues should look into artificial intelligence and machine learning. You're in luck if you enjoyed learning about a few of the distinctions between unsupervised and supervised machine learning and are interested in learning more.
To pique your interest and broaden your understanding in one of the most fascinating areas of computer science, there is a ton of materials available.
Have a happy learning and continue learning more!
FAQ:
- What is the main difference between supervised and unsupervised learning?
The main difference between supervised and unsupervised learning is that supervised learning uses labeled data, in which the input data is paired with corresponding target labels, while the latter uses unlabeled data and seeks to independently identify patterns or structures.
2. How does label data affect the choice between supervised and unsupervised learning?
Labeled data is necessary for supervised learning since it gives the model the data it needs to base its predictions. Contrarily, unsupervised learning doesn't need labeled data because it focuses on finding innate patterns or relationships within the data rather than having a specified target label.
3. What are some common applications of supervised learning?
Speech recognition, spam filtering, image classification, sentiment analysis, and recommendation systems are some examples of common supervised learning applications.
4. Can unsupervised learning be used for prediction or classification?
Unsupervised learning can be used indirectly for prediction or classification even though it is typically utilized for clustering, dimensionality reduction, and anomaly detection. This can be achieved by first applying supervised learning algorithms to create predictions or perform classification based on the patterns found in the data using unsupervised learning approaches to find patterns in the data.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
