

Evaluating and Fine-Tuning Multimodal Video Captioning Models - A Case Study


Video captioning models represent a significant advancement in the intersection of computer vision and natural language processing. These models automatically generate textual descriptions for video content, enhancing accessibility, searchability, and user engagement.
As video content continues to proliferate across various platforms, the ability to accurately describe and index this content becomes increasingly valuable.
However, to ensure these models perform optimally, continuous evaluation and fine-tuning are imperative. This process not only refines their accuracy but also ensures they remain relevant and effective in diverse and evolving contexts.
What are video captioning models?
Video captioning models are sophisticated AI systems designed to analyze video content and generate descriptive text that encapsulates the visual and auditory information presented. These models typically integrate components of computer vision to process video frames and natural language processing to construct coherent and contextually appropriate sentences.

The primary function of these models is to transform complex video data into a textual format that is easily interpretable by humans. This capability is critical for several applications, including improving the accessibility of video content for individuals with visual or hearing impairments, enhancing video search engines, and enabling more effective content moderation and management.
The significance of video captioning models extends beyond mere translation of visual data into text. They play a crucial role in indexing and retrieving video content, thus enabling better organization and easier access to information. For example, platforms like YouTube and Vimeo can use these models to automatically generate captions and descriptions, making it easier for users to find relevant videos through text-based search queries.
Additionally, in educational settings, video captioning can aid in the creation of transcripts for lectures and tutorials, facilitating learning and review.
Importance of Evaluation and Fine-Tuning
Evaluating and fine-tuning video captioning models is essential to maintain and enhance their performance over time. The primary goal of evaluation is to measure the accuracy and effectiveness of the captions generated by these models.
This involves assessing various aspects such as the relevance, coherence, and grammatical correctness of the captions. BLEU (Bilingual Evaluation Understudy), METEOR (Metric for Evaluation of Translation with Explicit Ordering), and CIDEr (Consensus-based Image Description Evaluation) are all common evaluation metrics. Each one gives you a different way to judge the quality of the generated text.
Fine-tuning, on the other hand, involves adjusting the model parameters to better align with specific datasets or application requirements. This process is crucial for several reasons:
Improving Accuracy: Initial training of video captioning models may not cover all possible scenarios and nuances present in different video content. Fine-tuning helps in adapting the models to new data, reducing errors and enhancing the precision of the captions.
Enhancing Relevance: As the context and usage of video content evolve, fine-tuning ensures that the models stay updated and generate captions that are contextually relevant. This is particularly important for applications in rapidly changing fields like news, entertainment, and social media.
User Satisfaction: Accurate and relevant captions significantly enhance user experience by providing clear and precise descriptions. This is especially critical for accessibility, where users rely on captions to understand the content fully.
Handling Diverse Data: Videos vary widely in terms of content, style, and language. Fine-tuning allows models to handle this diversity more effectively, ensuring that they perform well across different types of videos, from educational content to entertainment.
Mitigating Bias and Ethical Concerns: Continuous evaluation and fine-tuning help in identifying and addressing biases present in the models. This is crucial for ethical AI deployment, ensuring that the models do not perpetuate stereotypes or misinformation.
Evaluation Metrics for LLM-Powered Video Captioning Models
Quality Assessment Metrics
BLEU@4 Score: The BLEU (Bilingual Evaluation Understudy) score, particularly BLEU@4, is widely used for evaluating the quality of text generated by machine translation models.
For video captioning, BLEU@4 measures the overlap of n-grams between the generated captions and a set of reference captions. A higher BLEU@4 score indicates better alignment with the reference texts, suggesting that the model generates captions that are accurate and contextually appropriate. Here is how you can calculate it.

Where m is the number of words from the candidate that are found in the reference. Wt is the total number of words in the candidate. r is the effective length of the reference corpus, and c the total length of the translation corpus. Pn is the geometric average of the modified n-gram precision. N is the length of n-grams used to compute Pn.
METEOR: The METEOR (Metric for Evaluation of Translation with Explicit ORdering) metric offers a more nuanced approach to evaluating text generation. Unlike BLEU, which focuses primarily on precision, METEOR incorporates both precision and recall and also considers synonymy and stemming.
This makes METEOR particularly effective in assessing the quality of generated captions by ensuring they capture the essence of the reference captions even if the exact wording differs. Here is how to calculate METEOR score.

Number of unigrams in the candidate translation that are also found in the reference translation. wt is the total number of unigrams in the candidate translation. wr is the total number of unigrams in the reference translation. c is the number of chunks, where a chunk is defined as a set of unigrams that are adjacent in the candidate and in the reference. Um is the number of unigrams that have been mapped
ROUGE: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is another popular metric, especially useful for text summarization and generation tasks. It evaluates the quality of generated text by comparing it to reference texts, focusing on recall. ROUGE measures the overlap of n-grams, word sequences, and word pairs, providing a comprehensive assessment of the generated captions' relevance and completeness.
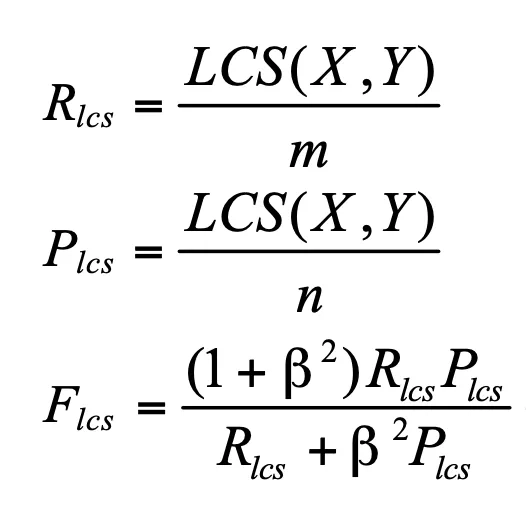
In the formula above, X is a reference summary sentence and Y is a candidate summary sentence with sizes m,n respectively. Beta is a parameter in the ROUGE-L score that controls the relative importance of precision and recall. When beta is 1 the ROUGE-L score is simply the harmonic mean of precision and recall. However, if beta is greater than 1, then recall is given more weight than precision.
CIDEr: CIDEr (Consensus-based Image Description Evaluation) is specifically designed for evaluating image and video captioning models. It measures how well a generated caption aligns with human consensus by comparing it to a set of reference captions using term frequency-inverse document frequency (TF-IDF) weights. CIDEr emphasizes the importance of generating captions that are not only accurate but also reflect the diversity and richness of human annotations. Here is the formula to calculate CIDEr.
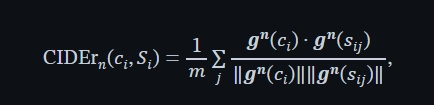
The score is calculated by taking the average cosine distance between the gradient vectors of the cost function for ‘c’ and each ‘s_ij’ in the set S. The cosine distance is a measure of the angle between two vectors, indicating how similar they are in direction.
In the formula, ‘m’ denotes the number of elements in the set S, and the summation symbol Σ indicates that the calculation is performed over the indices i and j. The dot product between the gradient vectors is divided by the product of their magnitudes, which are represented by the norms ||g^n(c_i)|| and ||g^n(s_ij)||.
Human Evaluation
Despite the robustness of automated metrics, human evaluation remains indispensable for assessing video captioning models. Human evaluators can provide insights into the relevance, coherence, and naturalness of the generated captions, aspects that automated metrics might overlook.
Human evaluation typically involves rating the captions based on criteria such as fluency, informativeness, and accuracy in describing the video content. This subjective assessment is essential for understanding how well the model performs in real-world scenarios and ensuring that the captions meet user expectations.
Temporal Consistency
Temporal consistency is a critical aspect of video captioning that automated metrics often fail to capture adequately. Evaluating temporal consistency involves assessing how well the model maintains context and continuity across different frames of the video.
This includes ensuring that the generated captions reflect the progression of events and actions in a logical and coherent manner. A model that excels in temporal consistency will produce captions that seamlessly describe the video's narrative, providing a smooth and cohesive viewing experience.
Evaluating this requires both automated methods, such as tracking the alignment of actions and events across frames, and human evaluation to ensure that the temporal flow is natural and intuitive
Fine-Tuning Strategies for LLM-Powered Video Captioning Models
One-shot Learning: One-shot learning is a powerful technique for fine-tuning video captioning models using a minimal amount of data. In this approach, the model is adapted with just a single text-video pair to better handle specific scenarios or domains.
This can be particularly useful for applications where data is scarce or for specialized tasks that require the model to understand unique contexts.
For example, a video captioning model might be fine-tuned using a single instructional video to accurately generate captions for other similar instructional videos. The key advantage of one-shot learning is its efficiency, it allows the model to quickly adapt to new tasks without requiring extensive additional training data.
Techniques such as metric learning and memory-augmented neural networks are often employed to enhance the model's ability to generalize from a single example.
Domain Adaptation: Domain adaptation involves adjusting the video captioning model to perform optimally in specific domains or types of video content. This ensures that the generated captions are not only accurate but also contextually relevant.
For instance, a model trained on general video data might be fine-tuned to better caption sports videos, where specific jargon and action sequences are prevalent.
Techniques for domain adaptation include domain-adversarial training, where the model learns to generate domain-invariant features, and domain-specific fine-tuning, where the model is fine-tuned on a targeted dataset relevant to the specific domain.
By incorporating these techniques, the model can better understand and generate captions that resonate with the specific nuances of the target domain.
Data Augmentation: Data augmentation is a strategy used to increase the diversity and quantity of training data by making modifications to existing data or generating synthetic data.
For video captioning models, data augmentation can involve various techniques such as altering video frames, changing the order of frames, and adding noise to the video or text descriptions. This helps the model become more robust and improves its generalization capabilities.
Synthetic data generation, where artificial videos and corresponding captions are created using techniques like GANs (Generative Adversarial Networks) or simulation environments, can also significantly enhance the training process.
By exposing the model to a wider range of variations in the training data, data augmentation ensures that the model can handle real-world scenarios more effectively.
Transfer Learning: Transfer learning leverages knowledge gained from pre-trained models to improve performance on specific video captioning tasks. Pre-trained models, such as those based on BERT, GPT, or specialized video captioning models, have already learned a wide range of features from large-scale datasets.
When applied to video captioning, transfer learning can significantly reduce the amount of data and computational resources required for training.
The pre-trained model can be fine-tuned on a smaller, task-specific dataset, allowing it to adapt to the nuances of the new task quickly. This approach not only accelerates the training process but also enhances the model's ability to generate high-quality captions by utilizing the rich features learned during the pre-training phase.
Case Studies
A prominent gaming company while developing a new game need to ensure it is accessible to players with hearing impairments.
However it is facing significant challenges in generating accurate and contextually relevant captions for its game footage. There was one video with nearly 14000 frames(13740 to be exact) a small portion of which is shown below as an example.
These captions were essential for accessibility, content marketing, and improving user engagement. The complexity of the gaming videos, characterized by rapid scene changes, intricate graphics, and dynamic elements, posed substantial difficulties in maintaining caption quality and consistency.
Challenge: Computational Complexity
One of the core challenges the gaming company faced was the computational complexity involved in training and fine-tuning their video captioning models.
The gaming videos featured a multitude of rapidly changing scenes, requiring the model to process and understand a vast amount of visual data in real-time. The computational demand was high, leading to delays and inefficiencies in generating accurate captions.
Solution: Reinforcement Learning from Human Feedback (RLHF)
To address this challenge, Labellerr implemented a sophisticated Reinforcement Learning from Human Feedback (RLHF) approach. This method leverages human evaluators to guide and improve the model's performance iteratively. Here's how we helped the gaming company:
Detailed Analysis Using RLHF
Frame-by-Frame Analysis: The image below illustrates the meticulous frame-by-frame analysis required for effective video captioning. Each frame of the gaming video was scrutinized based on several parameters.
Frames 1-2

Frames 3-4

Frames 5-6

Here are the captions generated by the model for the frames 1-6. Here the texts in red is denote hallucination. The text highlighted with green shows the correction done by our human annotators where the model has either missed out on certain details or has hallucinated.


Content Present in Each Frame: Human evaluators identified and labeled the key elements in each frame. This included recognizing characters, objects, environment settings, and significant actions. For instance, in a first-person shooter game, identifying whether the player is in combat, navigating through terrain, or interacting with NPCs (Non-Player Characters) is crucial.


Camera Movement: Evaluators assessed whether there was any camera movement within each frame. In gaming videos, dynamic camera angles and movements are common, which can drastically change the scene's visual context. Tracking these changes helped in maintaining the temporal consistency of the captions.
Object Movement: Evaluators checked for any movement of objects within the frames. In gaming videos, objects such as characters, vehicles, and projectiles often move rapidly. Recognizing and accurately describing these movements were essential for generating relevant captions.
Text and Watermark Detection: The presence of text overlays or watermarks in the frames was identified. This could include in-game text such as scores, player names, or mission objectives. Detecting and differentiating these from other visual elements ensured that the captions remained clear and focused on describing the core action.
Implementation of RLHF
Training Phase: Using the feedback from human evaluators, the model was fine-tuned iteratively. Initially, the model generated captions based on its existing training. Human evaluators reviewed these captions and provided feedback on accuracy, relevance, and coherence.
Reward System: The feedback from human evaluators was converted into a reward system. Captions that closely matched the evaluators' expectations received higher rewards, guiding the model to prioritize similar outputs in the future.
Iterative Refinement: This process was repeated over multiple iterations. With each iteration, the model's performance improved, as it learned to better align its captions with the evaluators' feedback. This continuous learning loop significantly enhanced the model's capability to handle the complex visual data in gaming videos.
Results and Impact
Improved Accuracy and Relevance: The RLHF approach resulted in a marked improvement in the accuracy and relevance of the captions. The model became adept at recognizing and describing complex scenes with high precision.
Enhanced User Engagement: The quality of the captions contributed to a better viewing experience, increasing user engagement and satisfaction. The captions were not only accurate but also contextually enriched, providing deeper insights into the gameplay.
Efficient Processing: Despite the high computational demands, the iterative feedback loop helped streamline the processing, making it more efficient. The model required fewer resources over time as it became more proficient in generating high-quality captions.
Conclusion
The landscape of video captioning is evolving rapidly with advancements in machine learning and artificial intelligence. The effective evaluation and fine-tuning of video captioning models are crucial steps in harnessing the full potential of these technologies.
By understanding and addressing the unique challenges inherent in video captioning, such as computational complexity, data scarcity, and ethical considerations, developers can create more accurate, relevant, and user-friendly models.
The integration of advanced evaluation metrics like BLEU@4, METEOR, ROUGE, CIDEr, and human evaluation ensures that the quality of generated captions is rigorously assessed. These metrics, combined with the importance of temporal consistency, provide a comprehensive framework for evaluating model performance.
Moreover, fine-tuning strategies such as one-shot learning, domain adaptation, data augmentation, and transfer learning play a pivotal role in enhancing model accuracy and applicability. These strategies enable models to adapt to specific scenarios, leverage existing knowledge, and become more robust through the use of synthetic data.
In conclusion, the effective evaluation and fine-tuning of video captioning models are integral to their success and applicability. By employing a combination of advanced metrics, human evaluation, and strategic fine-tuning approaches, developers can significantly improve the performance and reliability of video captioning systems.
This, in turn, enhances user experience and broadens the scope of applications for video captioning technology across various industries.
FAQ
1. What are the main benefits of using large language models (LLMs) for video captioning?
LLMs enhance video captioning by generating more accurate, contextually relevant, and coherent captions. They leverage extensive pretraining on diverse datasets to understand complex visual and textual information, leading to improved performance in describing video content. This results in better user experiences and accessibility, as LLMs can capture intricate details and maintain context over longer video sequences.
2. How do Vid2Seq, COOT, and MART models differ in their approach to video captioning?
Vid2Seq focuses on large-scale pretraining to produce dense and detailed captions, excelling in accuracy and comprehensive video descriptions. COOT employs hierarchical and cooperative learning mechanisms, providing contextually rich and reliable captions with excellent coverage. MART utilizes memory-augmented transformers to generate coherent paragraph-level captions, maintaining context over longer sequences with minimal hallucinations. Each model has unique strengths that cater to different aspects of video captioning.
3. What are some potential new applications for advanced video captioning models?
Advanced video captioning models can be applied in real-time captioning for live events, enhancing accessibility features for users with disabilities, and integrating with multimedia tools for better content management and discovery. They can also be used in educational technology, video analytics, and content recommendation systems, providing detailed and contextually relevant captions that improve user engagement and content understanding.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
