

ML Beginner's Guide To Build News Classification Model Using NLP
Learn how NLP automates news classification by categorizing articles into predefined topics using techniques like tokenization, stemming, and NER. Build a model using preprocessing, feature extraction, and evaluation for accurate categorization


Table of Contents
- Introduction
- NLP Concepts with Example
- NLP Model Building
- Challenges in NLP
- Frequently Asked Questions
Introduction
In today’s digital age, the huge amount of information available on the internet has made it increasingly challenging for all users to search through and find relevant content.
News websites consist of various categories like sports, technology, and entertainment.
News organizations, various online platforms face the difficult task of efficiently organizing and categorizing huge volumes of news articles to ensure people can access information according to their interests.
Natural language Processing(NLP) techniques offer a solution to this problem by automatically categorizing news articles into predefined topics or themes.
It is like navigating through a library where each book is neatly categorized based on title, saving your time and effort.

NLP Concepts with Example
Let’s break down the concept of NLP and explore its key components:
- Tokenization: Tokenization is the process of breaking down text into smaller chunks, like words or phrases, known as tokens. These tokens serve as the basic building blocks for building up our NLP model.
- Stemming and Lemmatization: These are techniques used to reduce words to their base or root forms. Stemming removes prefixes and suffixes from words, while lemmatization maps words to their canonical forms based on dictionary definitions.
- Part-of-Speech(POS) Tagging: POS tagging assigns words into grammatical categories like noun,verb,adjective etc. This helps in understanding the structure of sentences and is useful for text analysis.
- Named Entity Recognition(NER): NER is the process of identifying and categorizing named entities like people, organizations, and locations mentioned in text.This is useful for extracting structured information from unstructured text data.
- Sentiment Analysis: It involves determining the sentiment or opinion expressed, which can be positive, negative, or neutral.
Let’s take an example:
News Article:
“Apple is reportedly working on at least two foldable iPhones and a foldable iPad. According to several reports, Apple is likely to focus on a clamshell foldable, similar to the Galaxy Z Flip5 and it is expected to be more durable and more expensive compared to the other foldable in the market.”
NLP Categorization of the article:
Primary Category: Technology(with high confidence)
Secondary Categories: Business (medium confidence),Products(medium confidence)
Here’s how NLP analysis reached this conclusion:
Keywords: Apple, Foldable, iPhone, iPad, Galaxy Z Flip5, durable, expensive, market
Named Entity Recognition(NER): Apple, Galaxy Z Flip5
Topic Modeling: The article clearly focuses on Apple’s development of new foldable iPhone and iPad. This clearly indicates that it is a technology-related topic.
Additional Signs: Mentions of pricing and market comparison suggests about the business of the company hence business categorization also becomes important.
NLP would analyze the text of the news article, extract key features and identify relevant terms and phrases that indicate focus on any particular topic. Based on these features, the article would be categorized as technology.
NLP Model Building
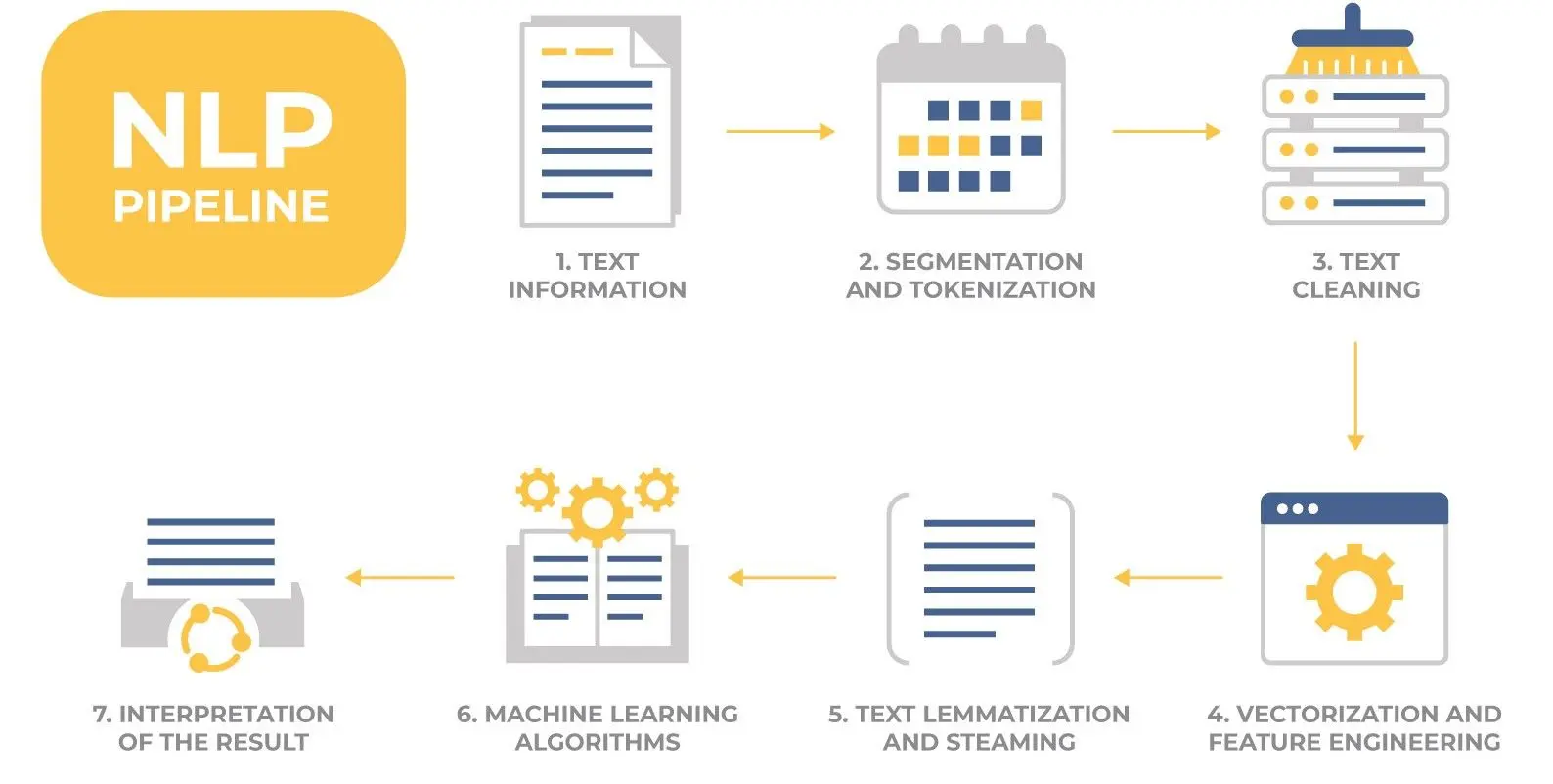
Process for building a News categorization Model:
The process typically involves several steps, including data preprocessing, feature extraction, model training, and evaluation.
- Data Collection: The first step is to collect a dataset of news articles from different categories. These articles should also be labeled with their corresponding categories.
- Data Pre-Processing: After data collection, the next step would be to clean and normalize the text data. This involves removing tags, punctuation, special characters, and stopwords. Also, text is often converted to lowercase, and lemmatization and stemming techniques are applied to reduce words to their root forms.
- Feature Extraction: Features are extracted from the text data to represent them in a particular format for the machine learning models to easily understand them. Some of the common techniques used for feature extraction are Bag-of-Words(BoW), Term Frequency-Inverse Document Frequency(TF-IDF), Word Embeddings.
- Model Selection and Training: Once the features are extracted,a machine learning model is trained to classify news articles into different categories. Some of the commonly used algorithms are Naive Bayes,Support Vector Machines (SVM), and Logistic Regression.
- Model Evaluation: Once the model is trained,it needs to be evaluated to assess its performance. It is usually done using metrics such as accuracy,precision, recall, and the F1-score.
Let's Build our own NLP Model:
For the following tutorial we have used the dataset from kaggle.
- Import all the required Libraries:
import os
import re
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
import nltk
import string
from nltk.corpus import stopwords
2. The data is present in the form of json. We would convert this into a dataframe using pandas library.
import json
import pandas as pd
with open('News_Category_Dataset_v3.json', 'r') as f:
json_data = f.read()
json_data2 = [json.loads(line) for line in json_data.split('\n') if line]
df = pd.DataFrame.from_records(json_data2)
3. Let’s see the columns present in our dataset.
df.head()
4. Now we would use the top 10 categories to train our model.
top_10_categories = df['category'].value_counts().nlargest(10).index
print("Top 10 categories:", top_10_categories)
# Filtering data for top 10 categories
data = df[['category', 'short_description']][df['category'].isin(
top_10_categories)].reset_index(drop=True)
display(data['category'].value_counts())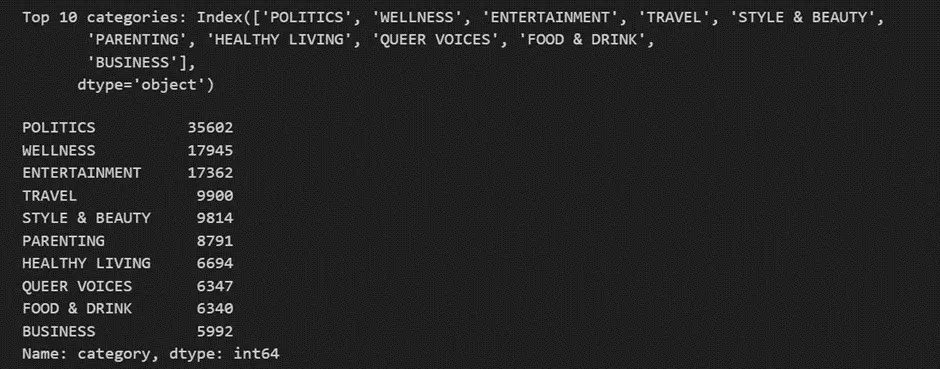
5. Now let’s visualize the data in form of pie chart:
import matplotlib.pyplot as plt
# Counting occurrences of each category
category_counts = data['category'].value_counts()
# Creating a pie chart
plt.figure(figsize=(6, 6))
plt.pie(category_counts, labels=category_counts.index,
autopct='%1.1f%%', startangle=140)
plt.title('Distribution of Top 10 Categories')
plt.axis('equal')
plt.show()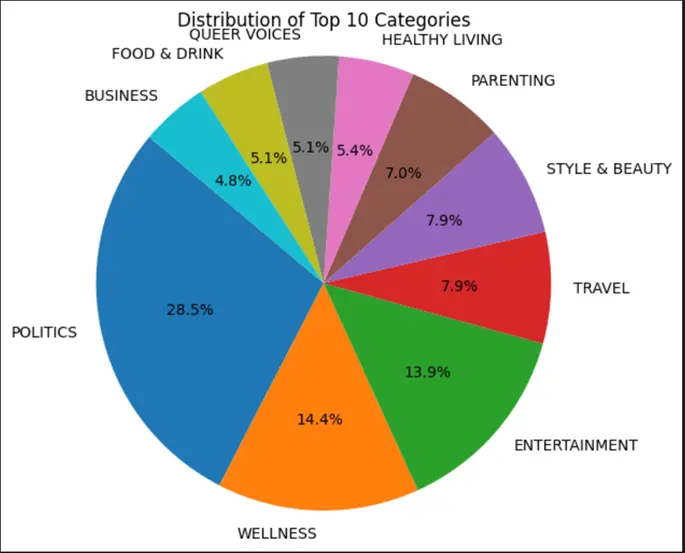
6. Now we will pre-process our dataset to remove any unwanted text or strings from the dataset.
import re
import string
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
nltk.download('wordnet')
def preprocess_text(text):
'''Preprocess text by making it lowercase, removing text in square brackets,
removing links, removing punctuation, and removing words containing numbers.'''
return re.sub('\[.*?\]|\w*\d\w*|https?://\S+|www\.\S+|<.*?>+|[%s]' %
re.escape(string.punctuation), '', str(text).lower())
def eliminate_stopwords(text):
'''Remove stopwords from the text'''
stop_words = stopwords.words('english')
words = text.split(' ')
words = [word for word in words if word not in stop_words]
return ' '.join(words)
def apply_stemming(sentence):
stemmer = nltk.SnowballStemmer("english")
return ' '.join(stemmer.stem(word) for word in sentence.split(' '))
def preprocess_and_clean(sentence):
'''Preprocess and clean the text'''
cleaned_text = preprocess_text(sentence)
stop_words = stopwords.words('english')
removed_stopwords_text = ' '.join(word for word in
cleaned_text.split(' ') if word not in stop_words)
stemmed_text = ' '.join(apply_stemming(word) for word
in removed_stopwords_text.split(' '))
return stemmed_text
data['clean_text'] = data['short_description'].apply(preprocess_text)
data['clean_text_without_stopwords'] = data['clean_text'].apply(eliminate_stopwords)
data['stemmed_text'] = data['clean_text'].apply(apply_stemming)
data['preprocessed_text'] = data['clean_text'].apply(preprocess_and_clean)

7. Now before model training we will convert the text data into numerical vectors.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
vectorizer = TfidfVectorizer()
# fit_transform for train data
tfid_X_train = vectorizer.fit_transform(Xtrain['clean_text'])
tfid_y_train = Xtrain['category']
# transform for test data
tfid_X_test = vectorizer.transform(Ytest['clean_text'])
tfid_y_test = Ytest['category']8. For model training and prediction we will be using Logistic Regression
from sklearn.linear_model import LogisticRegression
X_train, X_val, Y_train, Y_val = train_test_split(tfid_X_train,
tfid_y_train, test_size=0.25, random_state=42)
model = LogisticRegression(random_state=42)
model.fit(X_train, Y_train)
9. For evaluating the model we can use metrics such as accuracy, precision, recall
from sklearn.metrics import accuracy_score, precision_score, recall_score
y_pred = model.predict(X_val)
acc = accuracy_score(Y_val, y_pred)
print(f'Accuracy: {acc}')
precision = precision_score(Y_val, y_pred, average='weighted')
print(f'Precision: {precision}')
# Calculate recall
recall = recall_score(Y_val, y_pred, average='weighted')
print(f'Recall: {recall}')Challenges in NLP
- Imbalance Data: Often, many categories have fewer examples compared to others,leading to biased models that favor the dominant categories.
- Evolving Language and New Topics: Language has constantly evolved, with new slang terminology emerging. Models need continuous updates to handle these changes.
- Dynamic News: News changes rapidly, requiring constant updates and retraining of models to maintain accuracy. This is very resource-intensive and computationally expensive. This is very resource-intensive and computationally expensive, especially when processing large datasets or handling real-time news updates, making it important to manage system data on iPhone and other devices efficiently to ensure smooth performance.
- Scalability and Performance: Dealing with massive volumes of news data requires highly efficient NLP solutions , while maintaining good performance and response times.
Frequently Asked Questions
Q1) What does classification of news mean?
Classification of news refers to the process of categorizing news articles into different categories such as Technology ,politics, sports, entertainment, business and other fields.
Q2) What are the different algorithms that can be used for news classification?
For the task of news classification algorithms like Support Vector Machine(SVM), Random forest, Naive bayes are used.
Q3) What are the other applications of NLP?
NLP have many applications across various domains including Spell Checkers, Online Search, Language Translators, Voice Assistants.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
