

Boosting Efficiency in Data Annotation with Active Learning
Data annotation is resource-heavy, slowing AI projects. Active learning helps by selecting only essential data to label, saving time and costs. It enhances model accuracy while reducing manual effort, especially valuable for projects with massive datasets.


Data annotation is the most manual intensive, time taking and resource heavy task in computer vision AI development. This causes delay, brings errors, and also contributes heavily to project costing. Making it the most efficient component of the data pipeline brings huge ROI.
However, there’s a promising solution: active learning. This innovative approach allows machine learning algorithms to interactively engage with users, streamlining the data labeling process.
By selectively choosing the most informative data points to annotate, active learning significantly reduces the amount of labeled data required, leading to faster and more cost-effective outcomes.
In this blog, we’ll explore what active learning is, its various types, and how it can effectively minimize the time spent on data annotation, ultimately enhancing the efficiency of your AI projects.
Table of Contents
- Active Learning: What is it?
- Types of Active Learning
- How Active Learning is Effective in Reducing the Time During Data Annotation?
- Conclusion
Active learning: What is it?
"Active learning" is a from of machine learning that allows learning algorithms to engage with users to categorize data with desired outcomes.
The algorithm actively chooses the subset of instances from the unlabeled data labeled next in active learning.
The fundamental concept of active learner algorithms is that when given the freedom to choose the data they want to learn from, machine learning algorithms can achieve higher accuracy while requiring fewer training labels.
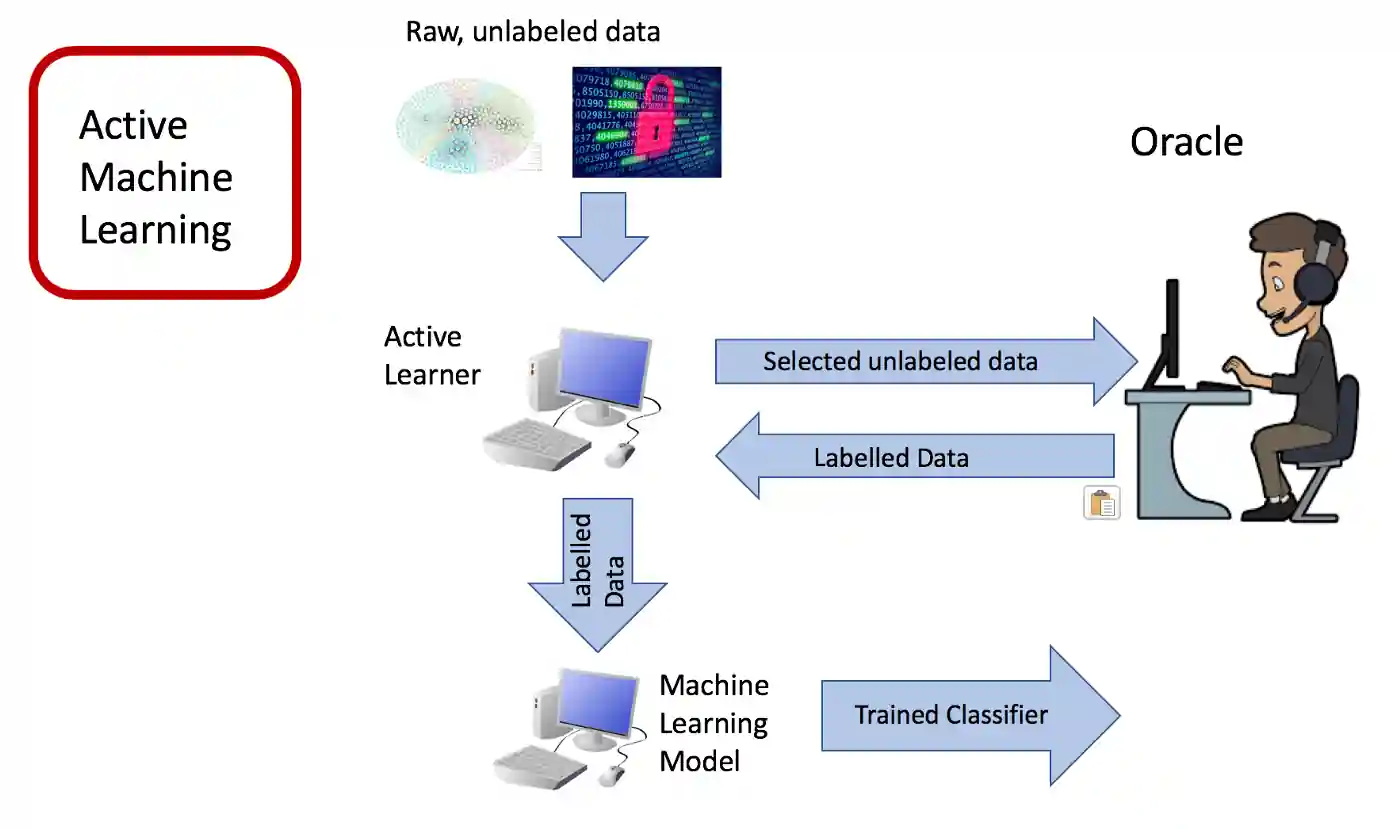
As a result, active learners are welcome to ask questions interactively during the training phase.
These requests typically involve sending unlabeled data instances to a human annotator, who then labels the instances. Active learning stands out as one of the most effective examples of success within the Human-in-the-loop paradigm.
Types of Active Learning
There are three categories of Active Learning such as:
- Active Pool-Based Learning
- Active Stream-based learning
- Querying
Active Pool-Based Learning
The most well-liked method is frequently applied when working on projects involving active learning.
The model is primarily trained on a labeled subset of a vast pool of unlabeled data.
Data is retrieved and labeled every time, it is taken out of the pool and used to train the model. As the model queries data to better understand the distribution and structure of the data, the pool slowly runs out. This method, however, uses a lot of RAM.
Active Stream-Based Learning
The method involves going through the datasets one sample at a time. It is established if a sample has to be inquired for its label each time it is submitted to the model.
The effectiveness over time is frequently below that of the pool-based strategy. However, as the samples that can be accessed may be better, delivering the most data for the active learner. This is because not all the data is available.
Querying
Choosing the most informative/valuable data samples for the model to train on is essential for establishing an effective Active Learning model.
Queries are used to "choose" the data that will help a system train the most effectively. The querying approach affects how well an Active Learning model performs.
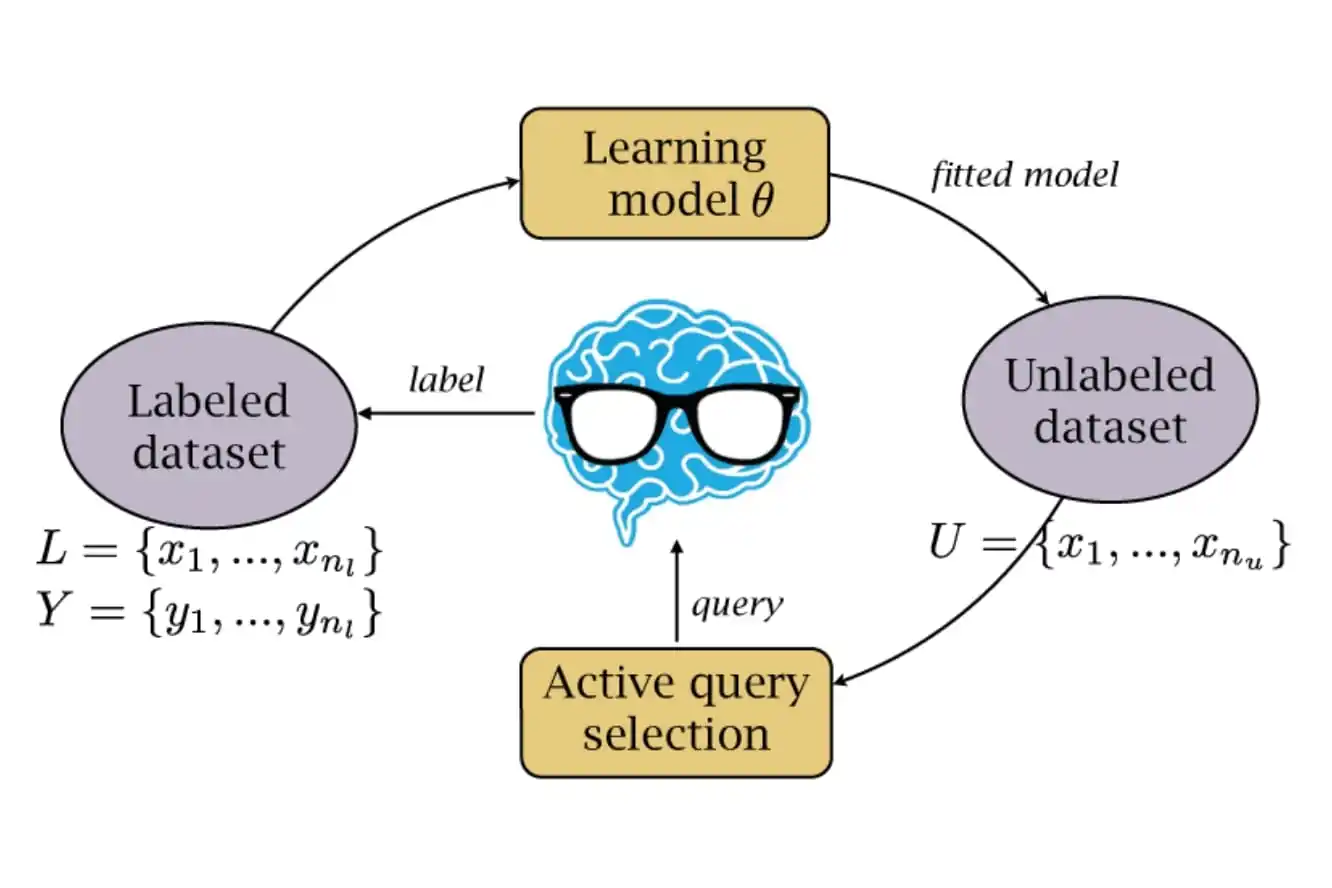
There are numerous methods for identifying the most informative data samples, and while in practice they can vary from sample to sample, there is a handful that can be applied to a wide range of use cases.
How is Active Learning effective in reducing the time during data annotation?
The Active Learning methodology's principles show that this strategy minimizes the overall quantity of data required for a model to function successfully.
This indicates that because only a portion of the information is labeled, the time and expense associated with the data labeling process are significantly reduced.
However, the responsibilities of model training and data annotation are frequently carried out independently and by various organizations.
When annotating data utilizing Human in the Loop methods, active learning is frequently used with online or progressive learning.
The retrieval of the most helpful data, iterative learning, improving model performance while annotation proceeds, and enabling a machine assistant to assist people are all tasks that are carried out by active learning.
Using active learning for video annotation would be a real-world illustration of this. In this activity, frames are closely related to one another and there are several frames every second (24–30, on average).
As a result, annotating every frame would be exceedingly time- and money-consuming. To improve performance with a much smaller number of annotated frames, it is, therefore, more appropriate to choose the frames in which the model is the most unclear and identify them.
With Labellerr’s active learning-powered platform, you can streamline your AI project pipeline by intelligently selecting the most impactful data to label. Our SaaS solution ensures high-quality annotations with minimal effort, boosting your model’s performance while saving resources. Start optimizing your data labeling process today - Book a Demo Now
Conclusion
If you are working on data-oriented projects that require labeling large volumes of data, or if you are part of an organization that manages a continuous stream of data for your AI system, you need an efficient labeling process.
Labeling the appropriate portion of this data can significantly address many of your needs.
This approach will substantially reduce the time and expense required to develop a high-performing model.
Utilizing the most recent findings in AI support, Labellerr uses active learning and several other similar strategies to maintain the highest possible speed and quality of our labels. We are pursuing the junction of progressive learning as well as active learning with its applications for high-quality data annotation as a result of our focus on increasing labeling efficiency with AI support.
To know more about such related information, stay with us!
FAQs
1. What is active learning in the context of data annotation?
Active learning is a machine learning approach where the model selectively chooses which data points to be labeled by humans, focusing on data that will improve its performance the most.
This process reduces the need for labeling large volumes of data, making it more efficient for training models.
2. How does active learning help reduce time in data annotation?
Active learning identifies the most informative or uncertain data points, so annotators focus on labeling only the critical data.
This targeted labeling reduces the number of annotations needed, saving both time and resources compared to traditional random sampling methods.
3. Why is active learning important for AI and ML model training?
Active learning minimizes the labeled data required to achieve high model accuracy.
This efficiency is particularly valuable for tasks requiring significant human involvement, like image or video annotation in sectors like healthcare or automotive, where collecting and labeling data is expensive and time-consuming.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
