

Data annotation: key to creating high-quality training data


The algorithm-driven world is driven by data annotation. If you want to create an effective AI model, then creating high-quality trained data is important.
Few characteristics must be possessed by AI-trained data otherwise it becomes difficult to obtain high-quality trained data. We are going to take a look at such characteristics and some ways by which you can create high-quality trained data.
Table of Contents
- What is Data Annotation?
- What is AI Training Data?
- How Can Training Data for AI Be Made of Higher Quality?
- What is a Human in the Loop?
- How Can You Create High-Quality Trained Data?
What is Data annotation?
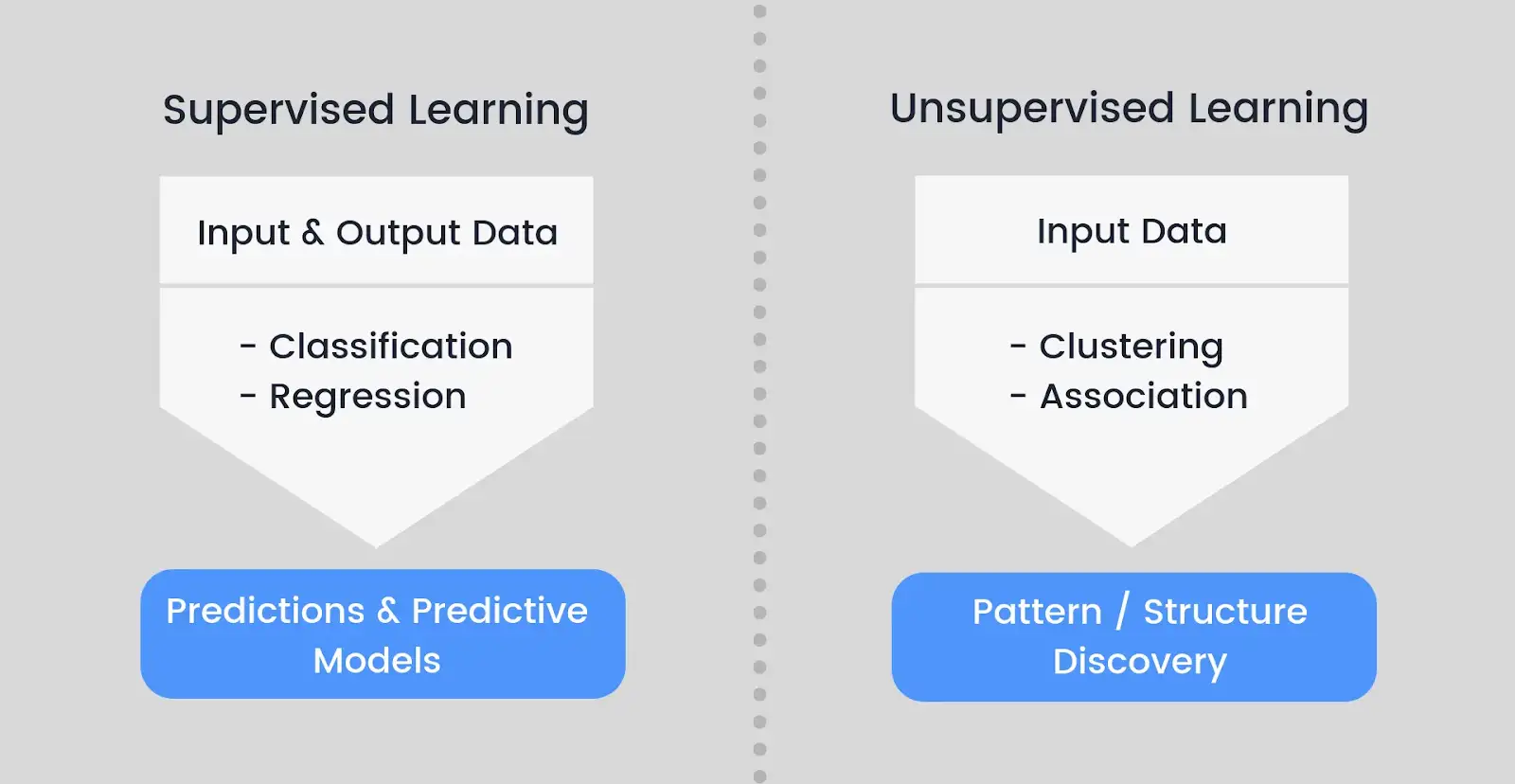
Data annotation is the process of labeling information for usage by machines. In supervised learning, in which the system uses labeled datasets to interpret, comprehend, and understand input patterns to produce desired outputs, it is very helpful.
For a particular use case, training data should be correctly categorized and annotated. Business organizations may create and enhance AI solutions that include high-quality, human-powered data annotation.
What is AI Training Data?
Training data in machine learning refers to the data used to develop a machine learning model or model. Analyzing or processing training data for AI and ML requires some human input. Depending on the machine learning techniques you're using and the kind of issue they're supposed to answer, you can vary how much participation there is from humans.
In supervised learning, the features of the data that will be utilized in the model are selected by humans. To teach the computer how to recognize the results your model is supposed to detect, training data must always be labeled, that is, augmented or annotated.
In unsupervised learning, patterns in the data—such as inferences or grouping of data points—are discovered using unlabeled data. There are machine learning models that combine supervised and unsupervised learning, known as hybrid models.
How can training data for AI be made of higher quality?
For the model of machine learning to work well, the training data must be of high quality.
Quality data is defined as data that has been cleaned and includes all qualities necessary for model learning.
Consistency and correctness of labeled data allow us to evaluate the quality of the data. Consistency eliminates unpredictability, whereas accuracy makes the model accurate.
Here are four main characteristics of high-quality training data are as follows:
Effectiveness
The information must be pertinent to the work at hand. For instance, you probably won't need photos of vegetables and fruits for training a computer vision system for autonomous vehicles. Instead, you would require training datasets that included images of streets, sidewalks, people walking, and cars.
Representative-ness
The data points or characteristics that the program is designed to forecast or classify must be present in the AI training data. Although the datasets will never be perfect, they must at least have the characteristics that the AI program is designed to identify.
Uniformity
The same attributes and single source requirement must apply to all data. There cannot be more information in one component of the data, such as gender or age. This will result in erroneous modeling and incomplete training data. Simply put, consistency is an important component of high-quality training data.
Detailed
Training data cannot ever be completely accurate. However, it ought to be a sizable dataset that covers the majority of model use scenarios. There must be enough examples in the training data for the model to train properly.
Real-world data samples are necessary because they will aid in training the model to know what to anticipate.
One of the most important factors in the training data process is Humans in the loop. Let's take a look at humans in the loop.
What is a human in the loop?
A sub-field of artificial intelligence known as "human-in-the-loop" (HITL) uses both human and artificial intelligence to develop machine learning models. People participate in a continuous cycle wherein they train, adjust, and test a specific algorithm in a classic human-in-the-loop way.
Typically, it operates as follows: Humans label data first. As a result, a model receives high-quality (and large amounts of) training data. This data is used to train a machine learning system to make choices.
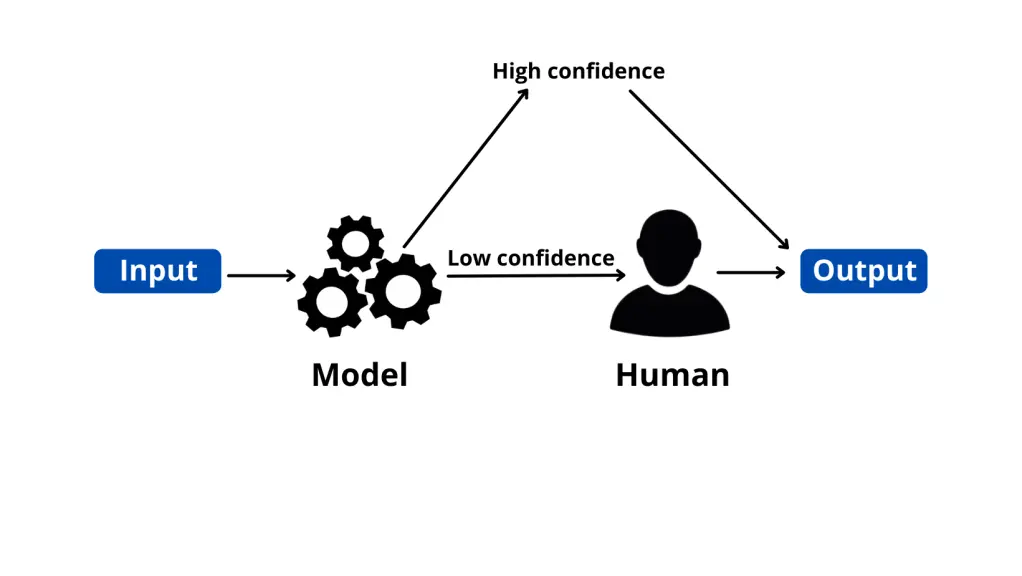
To classify the raw data and aid machine learning and prediction, humans employ annotation tools like Labellerr. To make sure the model learns appropriately, they evaluate the model's performance and verify the forecasts whenever the machine is unsure of its output.
Humans and machines work together in this loop!
How can you create high-quality trained data?
The largest challenge for many ML teams in developing a high-performance system is producing high-quality labeled training data. Making sure that every asset is appropriately labeled and labeled in a manner that will best "teach" the model about the requirement to perform might be difficult.
Creating better datasets
Your model will perform much better if datasets are compiled based on performance after each iteration, but this method is only applicable to teams with large, varied datasets to begin with.
Machine-generated data has the potential to be unreliable, and inaccurate, and to reinforce biases that the team needs to lessen or eliminate using your model.
Whereas synthetic value can undoubtedly be valuable for some use cases, it's crucial to balance its benefits with any potential drawbacks and develop extra mitigation strategies. So, it is recommended to find and create datasets that fit best with your requirements.
Understanding the model
Creating high-quality training data frequently necessitates a more detailed knowledge of the model. Although ML teams may use aggregate summary measurements to monitor model development and trends, many organizations choose not to delve deeper into the data.
As a result, unless the model is provided data that corrects them in the following iteration cycle, they ignore biases and performance differences among classes that may lead to less favorable findings.
Teams should carefully examine the model's performance with each class whenever a training period is finished to spot any potential special cases, biases, or other problems. The following training dataset should be selected by teams based on their findings.
Taking help from Experts
A model must be trained on operations that were previously only performed by humans with years of expertise and training in specialist industries like healthcare or agriculture.
Trained experts may be required to perform the labeling to create high-quality training data for such use cases, which can be a time-consuming and expensive procedure due to other requirements on their time.
If you are considering a professional place where you can obtain high-quality training data, then you can get in touch with Labellerr.
Labellerr is a data annotation platform that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers if any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from datasets—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
If you want to know more about such related information, then stay tuned!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
