

How to reduce the cost associated with data labeling


Data labeling is a laborious task and requires an ample amount of effort and money. The process of labeling data involves various steps from collecting data to annotating data with data labeling techniques to reviewing the processes. The process also involves humans in the loop which is an essential component but if your data labeling process completely depends on human factors, then you might be on the wrong track.
You can simply reduce the cost associated with data labeling by using various methods such as:
Table of Contents
- Using Transfer Learning
- Using Active Learning
- Enable Workflow Automation
- How Labellerr Can Help with All This?
Using Transfer Learning
Firstly, let’s get an idea about Transfer Learning.
Transfer learning allows you to use representations from a model that has already been trained rather than having to create a new model from start.
Typically, the pre-trained model is developed using sizable datasets, which are a recognized standard in the field of computer vision. The model-derived weights can be applied to additional computer vision applications.
The models can be included in the training process for new models or utilized directly to predict outcomes for novel tasks. The training time and generalization error of a new model is reduced by incorporating previously trained models.
When your training datasets are tiny, transfer learning is especially helpful. In this situation, you could, for example, initialize the new model's weights using the parameters from the previously trained models.
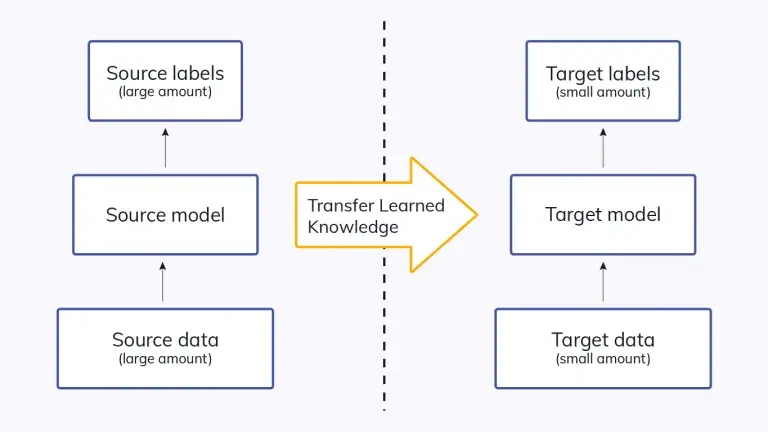
For instance- When you have trained our model to recognize Cars in an image, the same model can be used to recognized other vehicles present in the images.
Another can be that the Pedestrian detection is the key component of autonomous road vehicle location tracking because it enables a vehicle to recognise potential risks in the immediate vicinity and act accordingly to prevent traffic accidents that could cause injuries to people.
The model proposed to employ a pre-processing method to set up 3-dimensional data obtained by LiDAR sensors. Through sensor fusion, this pre-processing method is able to find potential zones that can be proposed for 3D classifications or a blend of 2D and 3D classifications. With the adaptive transfer learning model, according to some researchers one of several estimates based on transfer learning and convolutional neural networks have achieved above 98% accuracy.
Explore transfer learning for pedestrian detection in autonomous vehicles
Using Active Learning
A form of machine learning known as "active learning" allows learning algorithms to engage with users to categorize data with desired outcomes. The algorithm actively chooses the subset of instances from the unlabeled data that will be labeled next in active learning.
A wide range of activities and data sets, including computer vision and NLP, have shown active learning can yield significant cost savings in data labeling. This should be a sufficient explanation on its own, given that data labeling is one of the more costly components of training contemporary machine learning models.
People are frequently taken aback by the fact that active learning models can converge to superior final models while also learning more quickly (with fewer data). Your models will automatically adhere to the curriculum as a result of active learning, which also improves their performance as a whole.
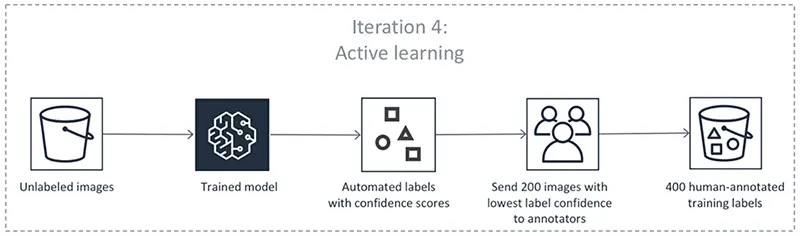
The steps that make up the iterative process of active learning are as follows:
Step 1: Instead of spending a lot of money and resources up front, start by classifying a tiny sample of data.
Step 2: Create a model based on the information above, and use it to forecast results for unlabeled data.
Step 3: Choose data points from the predictions using a sampling technique (such as uncertainty sampling, which chooses the data sets the model is least certain about), label them, and add them to the training dataset.
Step 4: (Return to Step 2) Start training the model using the revised dataset, then carry out the next steps until the quality is adequate.
Enable Workflow Automation

Workflow automation is a strategy for enabling the independent performance of tasks, documents, and information among work-related activities in compliance with established business standards. When done, this kind of automation needs to be a simple procedure that is carried out frequently to increase productivity on a day-to-day basis.
Since active learning requires frequent human interaction, users wanted a single interface where the data team could easily label new sets of data and rapidly assess how they affected the model to reduce the time between iterations. You can find a data annotation platform that will aid in fastening the data labeling process with the input of industry experts and saves you time as well.
By enabling workflow automation, you will get various other benefits apart from monetary benefits such as:
Prioritizing tasks of high importance: Automation frees workers from menial, low-value jobs so they may focus on higher-value, non-automated tasks that only people can complete.
Savings: Cost reductions are produced by higher productivity.
Visibility: It is possible to see the processes that are being automated thanks to the workflow map that is used to program automation software. This provides an organization with a top-down perspective of its workflows, which may be used to assist it to eliminate time- and resource-wasting outdated or redundant tasks.
Performance monitoring: Automation can monitor the efficiency of a workflow from beginning to end by digitizing the operations that make up the workflow. This makes it simple for a company to assess how well its operations are doing.
How Labellerr can help with all this?
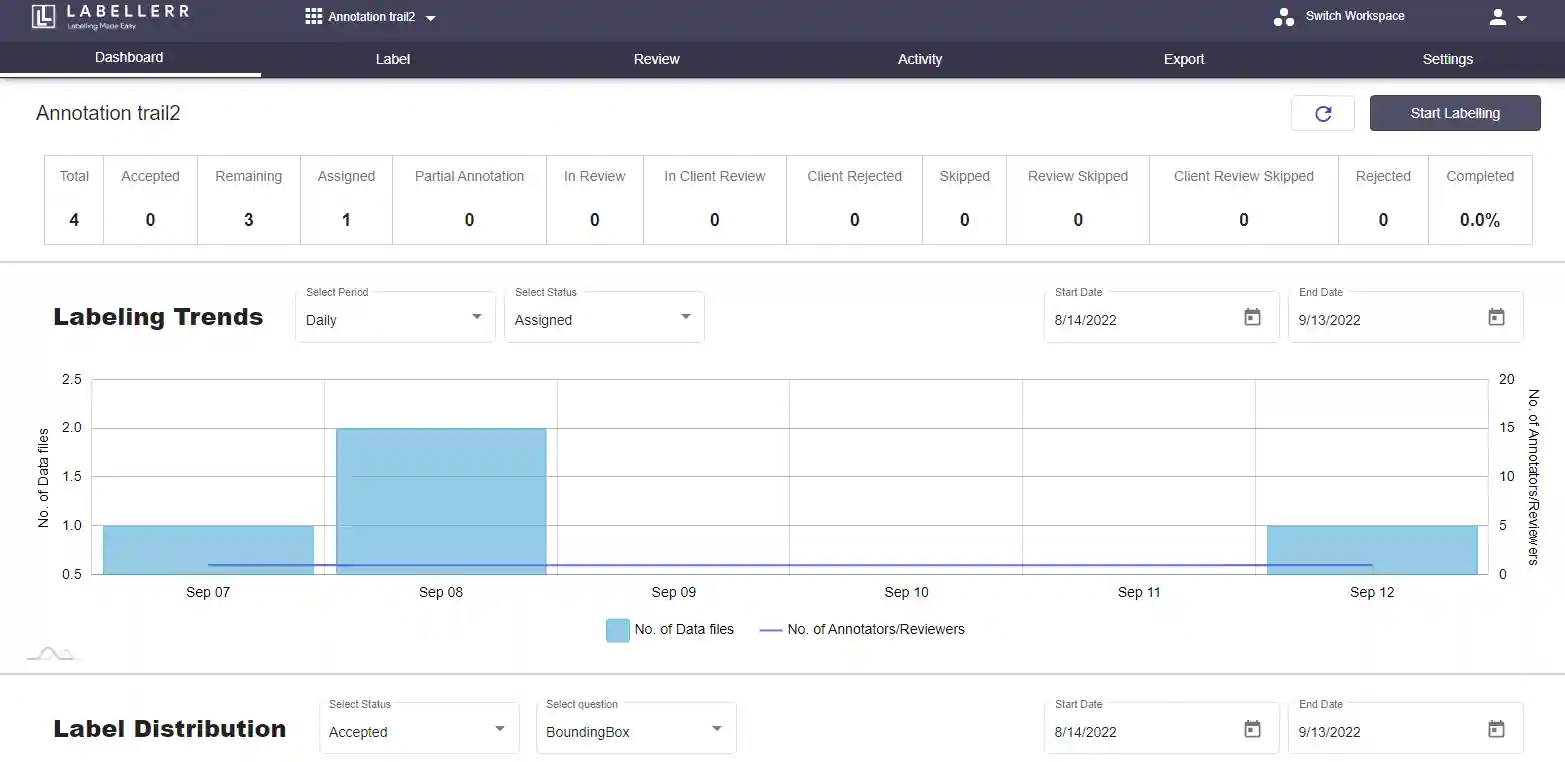
Labellerr is a computer vision data annotation workflow automation tool that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers in the event that any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from data—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
To know more about such related information, stay updated with us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
