

This 65-Billion-Parameter LLM Can Perform Unthinkable Tasks


LLaMA (Large Language Model Meta AI), a cutting-edge fundamental large language model created to aid academics, is a new large language model from Meta that was just released. A collection of foundation language models with 7 billion to 65 billion parameters is called LLaMA. It can handle a variety of natural language processing tasks and has been trained on trillions of tokens.
LLaMA has 10 times fewer parameters than its predecessor, making it a considerable advancement over earlier language models. The model has already sparked a great deal of attention among researchers and is anticipated to impact the natural language processing field substantially. In this blog, we will explore the features, llama number of parameters and capabilities of LLaMA and discuss how it can be used to solve real-world problems.
What is LLaMA?
In February 2023, Meta AI released the big language model LLaMA (Large Language Model Meta AI). It is a cutting-edge foundational large language model created to aid researchers in the advancement of their work in natural language processing.
A collection of foundation language models with 7 billion to 65 billion parameters is called LLaMA. Since 2018, transformer architecture has been the standard framework for language modeling. Instead of expanding the number of parameters, the LLaMA developers concentrated on scaling the model's performance by increasing the amount of training data.
The largest model was competitive with cutting-edge models like PaLM and Chinchilla, and it performed better on most NLP benchmarks than the considerably larger GPT-3 (with 175 billion parameters). In addition to creating text, having discussions, and summarizing written work, LLaMA can be utilized for more challenging tasks like deducing protein structures or resolving mathematical conundrums.
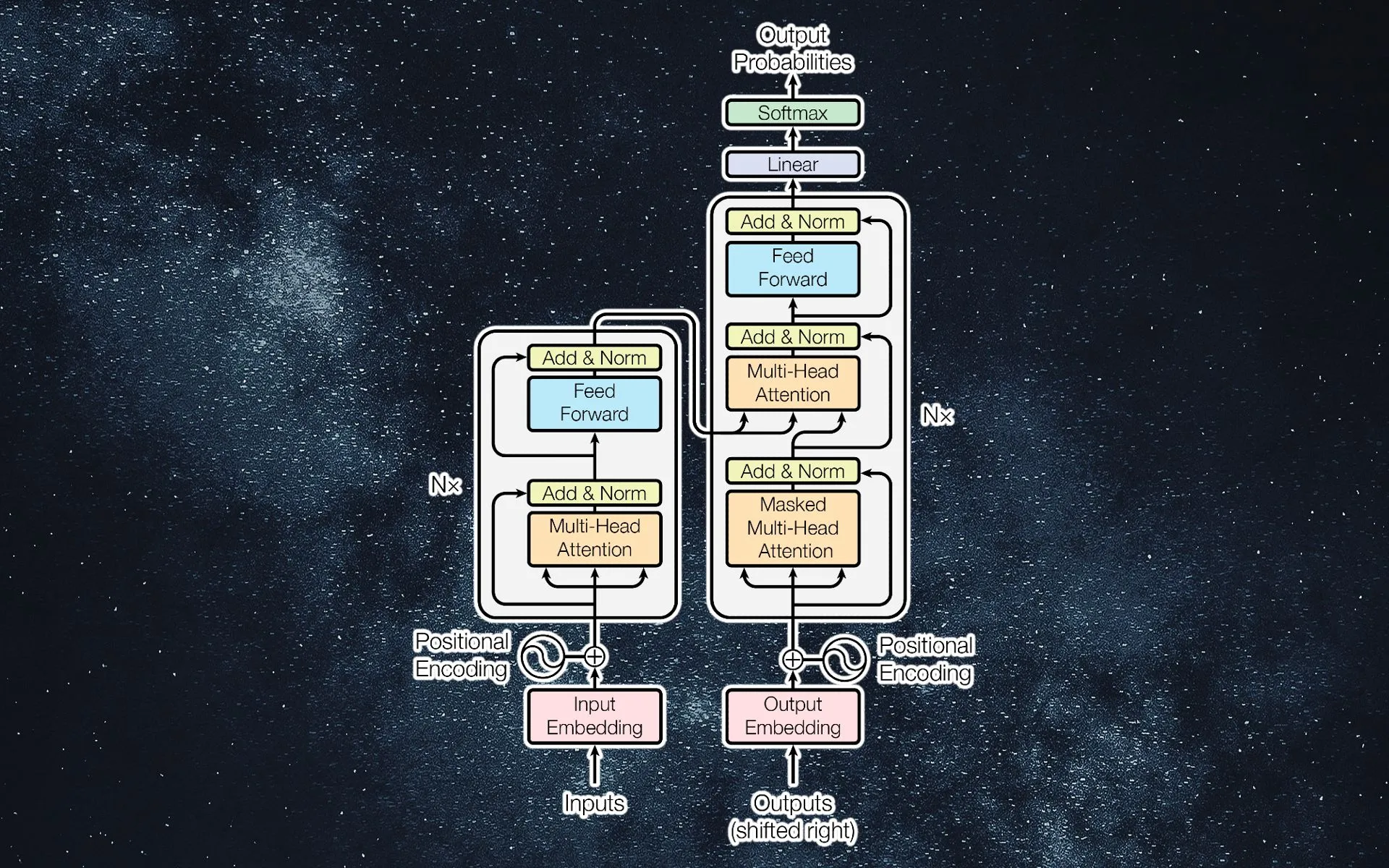
Architecture of LLaMA

Transformer architecture is used by LLaMA (Large Language Model Meta AI), which has been the industry standard for language modeling since 2018. Instead of expanding the number of parameters, LLaMA's designers concentrated on scaling the model's performance by increasing the amount of training data.
LLaMA is a collection of foundation language models with 7 billion to 65 billion parameters. llama number of parameters generates text recursively by using a sequence of words as input and predicting the following word. 1.4 trillion tokens from publicly accessible data sources, including web pages, books, and other textual materials, were used to train the LLaMA algorithm.
The 1.4 trillion tokens found in the datasets used by LLaMA came from open sources like GitHub, Wikipedia, arXiv, and Software Engineering Stack Exchange and were utilized for the byte-pair encoding step of the tokenization procedure.
Pre-normalization is used by meta-AI researchers, and it involves normalizing the input of each sub-layer of a transformer. Additionally, LLaMA utilized a cutting-edge activation function known as SwiGLU.
They also choose to use rotary embeddings, a new position embedding representation based on rotations that shows the position of position embeddings in relation to one another. The model generalization and gradient clipping to 1.0 of the classic Adam were significantly improved by the researchers using adaptive gradient techniques like AdamW.
The model is trained on a wide range of languages, concentrating on the 20 languages with the greatest number of speakers, with a preference for those that use the Latin and Cyrillic alphabets. Academic researchers, the government, civil society, academic organizations, and industry research laboratories can all access LLaMA because it is made available under a non-commercial license that is centered on research use cases.
How can LLaMA help in Computer Vision Tasks?
A large language model called LLaMA can be tailored for a number of activities, including computer vision tasks. According to LLaMA's developers, the largest model was competitive with cutting-edge models like PaLM and Chinchilla and performed better on most NLP benchmarks than the far larger GPT-3 (with 175 billion parameters).
LLaMA can be used to create text, hold discussions, summarize published content, and carry out more difficult tasks like deducing protein structures or resolving mathematical conundrums.
The ability to fine-tune LLaMA makes it perfect for computer vision jobs, where it can be used to create captions for images or videos, describe the contents of pictures, or respond to inquiries about pictures.
The open-source implementation of LLaMA is now accessible, making it simpler for academics and industry professionals to test the model. The introduction of LLaMA is anticipated to have a substantial impact on the fields of computer vision and natural language processing, and it has already sparked a great deal of curiosity among academics and industry professionals.
How can LLaMA speed up the training data process?
By leveraging foundation models, which can be fine-tuned for a number of applications and trained on a huge amount of unlabeled data, LLaMA can accelerate the gathering of training data.
The creators of LLaMA concentrated on scaling the model's performance by increasing the amount of training data rather than the number of parameters since they believed that the dominant cost for LLMs is from doing inference on the trained model rather than the computing cost of training.
Looking for Ways to Fasten Your Training Data Process?
If you want to fasten their training data process, try Labellerr and get your trained data within weeks!
Labellerr is an AI-powered data labeling platform that uses state-of-the-art machine learning algorithms to annotate large amounts of data automatically. It can help businesses and organizations save time and resources by automating the data labeling process and improving the accuracy and quality of the labeled data.
With Labellerr, users can upload their raw data, and the platform will automatically label it with 80% accuracy. The platform can be customized to fit specific labeling needs and can handle various data types such as text, images, and videos.
Additionally, the platform has a user-friendly interface that makes it easy to use for both technical and non-technical users.
Conclusion
In conclusion, LLaMA is a substantial advancement in large language models, outperforming earlier models in various language tasks and boasting an enormous 65 billion parameters. Future research and useful applications in natural language processing are made possible by its architecture and training procedure. The launch of LLaMA represents a significant turning point in the evolution of language models and establishes a new bar for what AI language technology is capable of. In the future, llama number of parameters will be improved further.
Explore more related content here with us!
FAQs
- What is LLaMA?
A cutting-edge fundamental large language model called LLaMA by Meta AI is created to assist in advancing the work in the area of AI. There are 7 billion to 65 billion parameters in this collection of foundation language models. In order to create text recursively, LLaMA uses a set of words as input and predicts the subsequent word.
2. What is the purpose of LLaMA?
The purpose of LLaMA is to assist researchers in advancing their work in the area of AI. It makes it possible for academics to investigate these models without having access to extensive infrastructure. LLaMA is a foundation model that is intended to be adaptable and can be used for a variety of use cases.
3. What is LLaMA's training process?
In training, LLaMA used billions of tokens. The 1.4 trillion tokens were used for training the 65B and 33B versions. The 20 languages with the most speakers were used to create LLaMA, with a concentration on those employing the Latin and Cyrillic alphabets.
4. What are the various sizes in which LLaMA is available?
The sizes of LLaMA include 7B, 13B, 33B, and 65B parameters.
5. How does LLaMA stack up against alternative language models?
LLaMA is a significant improvement over past language models since it has 10 times fewer parameters than its forerunner. The LLaMA developers focused on scaling the model's performance by increasing the quantity of training data rather than adding more parameters.
6. What is the license of LLaMA?
LLaMA is distributed under a noncommercial license that emphasizes open science and transparency.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
