Vision-language models How to Fine-Tune Llama 3.2 Vision On a Custom Dataset? Unlock advanced multimodal AI by fine‑tuning Llama 3.2 Vision on your own dataset. Follow this guide through Unsloth, NeMo 2.0 and Hugging Face workflows to customize image‑text reasoning for OCR, VQA, captioning, and more.
LLMs LLMs & Reasoning Models: How They Work and Are Trained! LLMs reason by analyzing data, applying logic, and solving problems step by step. They are trained with structured datasets, prompting techniques, and reinforcement learning.
Voicebot Fine Tuning 5 Best Voicebot Fine Tuning Tools in 2025 In 2025, top voicebot fine-tuning tools include Labellerr, Label Studio, Labelbox, Kili, and Databricks Lakehouse. These platforms offer customizable workflows, multi-format support, collaborative annotation, and seamless ML integration.
reinforcement learning with human feedback Complete Guide On Fine-Tuning LLMs using RLHF Explore how LLM reinforcement learning with human feedback (RLHF) fine-tunes large language models, improving natural language responses and optimizing AI behavior through rewards, human input, and iterative learning for enhanced model performance.
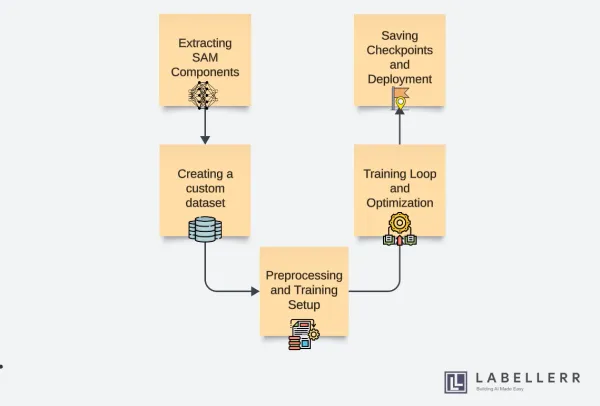
segment anything Fine-Tuning Segment Anything Model (SAM) Learn how to fine-tune Segment Anything Model (SAM) for precise image segmentation tasks. Discover techniques like one-shot learning to fine-tune SAM efficiently and improve performance on specific datasets, ensuring high accuracy with limited data.
CLIP Tutorial To Leverage Open AI's CLIP Model For Fashion Industry Discover how fine-tuning CLIP model can revolutionize fashion image recognition. Learn to optimize OpenAI's CLIP with domain-specific data for the fashion industry.
Multimodal AI Evaluation and Fine-Tuning for Image Captioning Models - A Case Study Table of Contents 1. Evaluation Metrics 2. Fine-Tuning Strategies for Image Captioning Models 3. Challenges in Image Captioning 4. Case Study 5. Conclusion 6. FAQ Image captioning models are sophisticated AI systems designed to generate descriptive text for images automatically. These models play a crucial role in various applications, such