computer vision End-to-End AI-Based Bottle Cap Quality Inspection System Learn how to build an AI-powered bottle cap inspection system using computer vision. Detect missing caps in real time, reduce defects, and improve quality control on high-speed production lines.
Ai in Security and surveillance How License Plate Recognition Works? Automatic License Plate Recognition (ALPR) explains how computer vision detects, cleans, and reads vehicle license plates using classical image processing and OCR, revealing the challenges and real-world techniques behind modern traffic and security systems.
AI in Manufacturing Building AI-Powered Quality Inspection Pipeline Learn how vision-based quality inspection uses AI and computer vision to detect defects, verify assembly, and automate pass or fail decisions on high-speed manufacturing lines.
security Perimeter Sensing using YOLO Perimeter sensing goes beyond motion detection by understanding context, object interaction, and zone awareness using computer vision to deliver reliable, real-world security intelligence.
computer vision Power Grid Inspection using Computer Vision Manual power grid inspections are risky and slow. Discover how Computer Vision and drones are transforming utility maintenance. This guide explores how AI automates defect detection, ensures worker safety, and enables predictive maintenance to prevent outages before they happen.
Yolo YOLO11 vs YOLOv8: Model Comparison A detailed expert comparison of YOLOv8 and YOLO11 object detection models, covering performance, accuracy, hardware needs, and practical recommendations for developers and researchers.
yolov12 Building a Pill Counting System with Labellerr and YOLO Fine-tuning YOLO for pill counting enables accurate detection and tracking of pills in pharmaceutical setups. Learn how to customize YOLO for your dataset to handle overlapping pills, varied lighting, and real-time counting tasks efficiently.
dino DINOv3 Explained: The Future of Self-Supervised Learning DINOv3 is Meta’s open-source vision backbone trained on over a billion images using self-supervised learning. It provides pretrained models, adapters, training code, and deployment support for advanced, annotation-free vision solutions.
cvpr CVPR 2025: Breakthroughs in GenAI and Computer Vision CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
AI KOSMOS-2 Explained: Microsoft’s Multimodal Marvel KOSMOS-2 brings grounding to vision-language models, letting AI pinpoint visual regions based on text. In this blog, I explore how well it performs through real-world experiments and highlight both its promise and limitations in grounding and image understanding.
cvpr CVPR 2025: Breakthroughs in Object Detection & Segmentation CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
Vision Language Model BLIP Explained: Use It For VQA & Captioning BLIP (Bootstrapping Language‑Image Pre‑training) is a Vision‑Language Model that fuses image and text understanding. This blog dives into BLIP’s architecture, training tasks, and shows you how to set it up locally for captioning, visual QA, and cross‑modal retrieval.
object tracking Learn DeepSORT: Real-Time Object Tracking Guide Learn to implement DeepSORT for robust multi-object tracking in videos. This guide covers setup, integration with detectors like YOLO for real-time use.
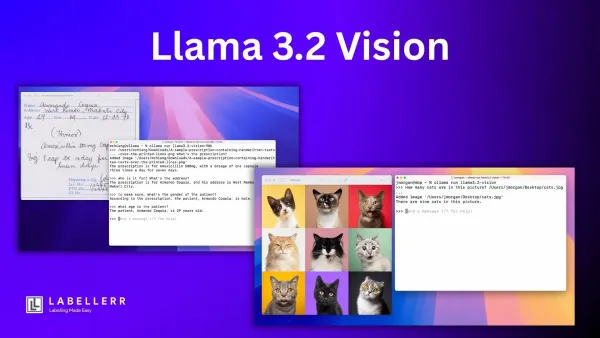
Vision-language models How to Fine-Tune Llama 3.2 Vision On a Custom Dataset? Unlock advanced multimodal AI by fine‑tuning Llama 3.2 Vision on your own dataset. Follow this guide through Unsloth, NeMo 2.0 and Hugging Face workflows to customize image‑text reasoning for OCR, VQA, captioning, and more.
object tracking How to Implement ByteTrack for Multi-Object Tracking This blog shows code implementation of ByteTrack, combining high- and low-confidence detections to maintain consistent object IDs across frames. By matching strong detections first and “rescuing” weaker ones, it excels at tracking in cluttered or occluded scenes.
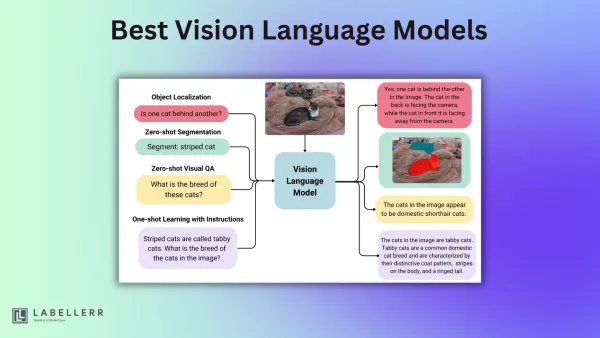
computer vision Best Open-Source Vision Language Models of 2026 Discover the leading open-source vision-language models (VLMs) of 2025 including Qwen 2.5 VL, LLaMA 3.2 Vision, and DeepSeek-VL. This guide compares key specs, encoders, and capabilities like OCR, reasoning, and multilingual support.
LLAMa A Hands-On Guide to Meta's Llama 3.2 Vision Explore Meta’s Llama 3.2 Vision in this hands-on guide. Learn how to use its multimodal image-text capabilities, deploy the model via AWS or locally, and apply it to real-world use cases like OCR, VQA, and visual reasoning across industries.
segmentation SegGPT Demo + Code: Next-Gen Segmentation is Here SegGPT is a versatile, unified vision model that performs semantic, instance, panoptic, and niche-domain segmentation via in-context “color-in” prompting—no task-specific fine-tuning required, instantly adapting to new classes from just a few annotated examples.
Semantic segmenatation SegFormer Tutorial: Master Semantic Segmentation Fast Learn how SegFormer uses Transformers and MLPs to perform semantic segmentation. Also implement Segformer yourself.
computer vision The Ultimate YOLO-NAS Guide (2026): What It Is & How to Use Explore YOLO-NAS! This guide explains its new Neural Architecture Search (NAS) for creating highly efficient and accurate object detection models for diverse hardware.
Yolo The Only YOLOv11 Multi-Labeling Guide You’ll Ever Need This guide details how to perform all vision tasks: detection, segmentation, pose estimation & more in YOLOv11.
computer vision Computer Vision in Security & Surveillance Explore how computer vision is revolutionizing security and surveillance, enabling real-time threat detection, facial recognition, and automated monitoring to enhance safety and operational efficiency across various sectors.
Vision Agent Vision Agent Using SAM-Description-Based Object Segmentation Agent Build Vision Agents using Segment Anything (SAM)! Learn how to combine text descriptions (like with Grounding DINO) and SAM for powerful, zero-shot object segmentation, bypassing traditional training needs. Understand and build your own description-based vision agent.
object detection RT-DETRv2 Beats YOLO? Full Comparison + Tutorial Explore a comparison between RT-DETR and RT-DETRv2 in real-time object detection with transformer power. Learn how to implement it using HuggingFace.
computer vision How to Perform Object Detection Tasks Using OWL v2 Explore how to implement OWLv2, a powerful open-vocabulary object detection model. Learn about its zero-shot capabilities, classification, guided image query, and how it understands text and images together for real-world use.