

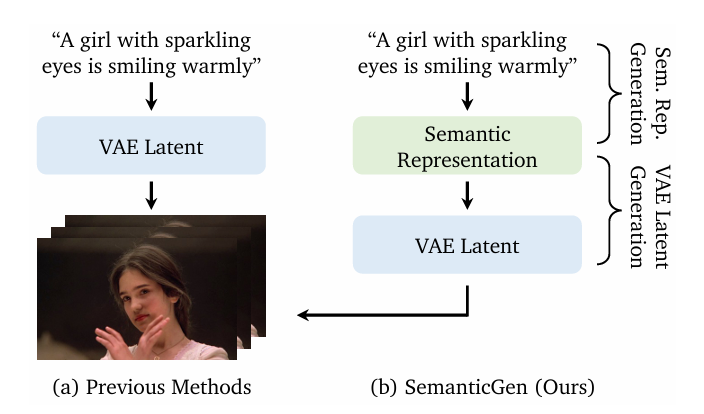
SemanticGen Framework: Revolutionizing Long-Form Video with Semantic Planning
SemanticGen redefines video generation by separating semantic planning from pixel synthesis. Using a two-stage diffusion process, it enables long-form, coherent videos while avoiding the computational limits of traditional diffusion models.

The Bottleneck of Modern Video AI
AI is great at making videos until you ask it to make a long one. What starts as a clean, impressive clip slowly unravels. Characters change. Scenes drift. The story forgets what it was supposed to be about.
The reason is simple most video models don’t actually understand what they’re creating. They brute-force every pixel, frame after frame and burning memory. As the video grows longer, the model gets overwhelmed and the narrative collapses.
SemanticGen (paper link) flips this process on its head. Instead of drawing first and thinking later, it plans the video at a high level before refining the visuals. By separating meaning from pixels, SemanticGen keeps stories consistent, cuts redundancy, and finally makes long-form AI video generation practical.
This is what happens when video models learn to think before they draw.
The SemanticGen Framework
Overview of SemanticGen Framework
Image link
It utilizes a two-stage diffusion paradigm to shift the generation focus from a computationally heavy pixel space to a compact semantic space. Standard models often struggle with the inherent redundancy of video data, continuously recalculating static elements like a background sky.
SemanticGen addresses this inefficiency by performing global planning in a "meaning" space first, and refining the visual details later.
This process mirrors the workflow of a human artist: it sketches a high-level storyboard (semantics) before painting the final textures (latents).
By decomposing the complex task of video synthesis, the framework effectively separates the narrative "what" from the visual "how".
The Two-Stage Diffusion
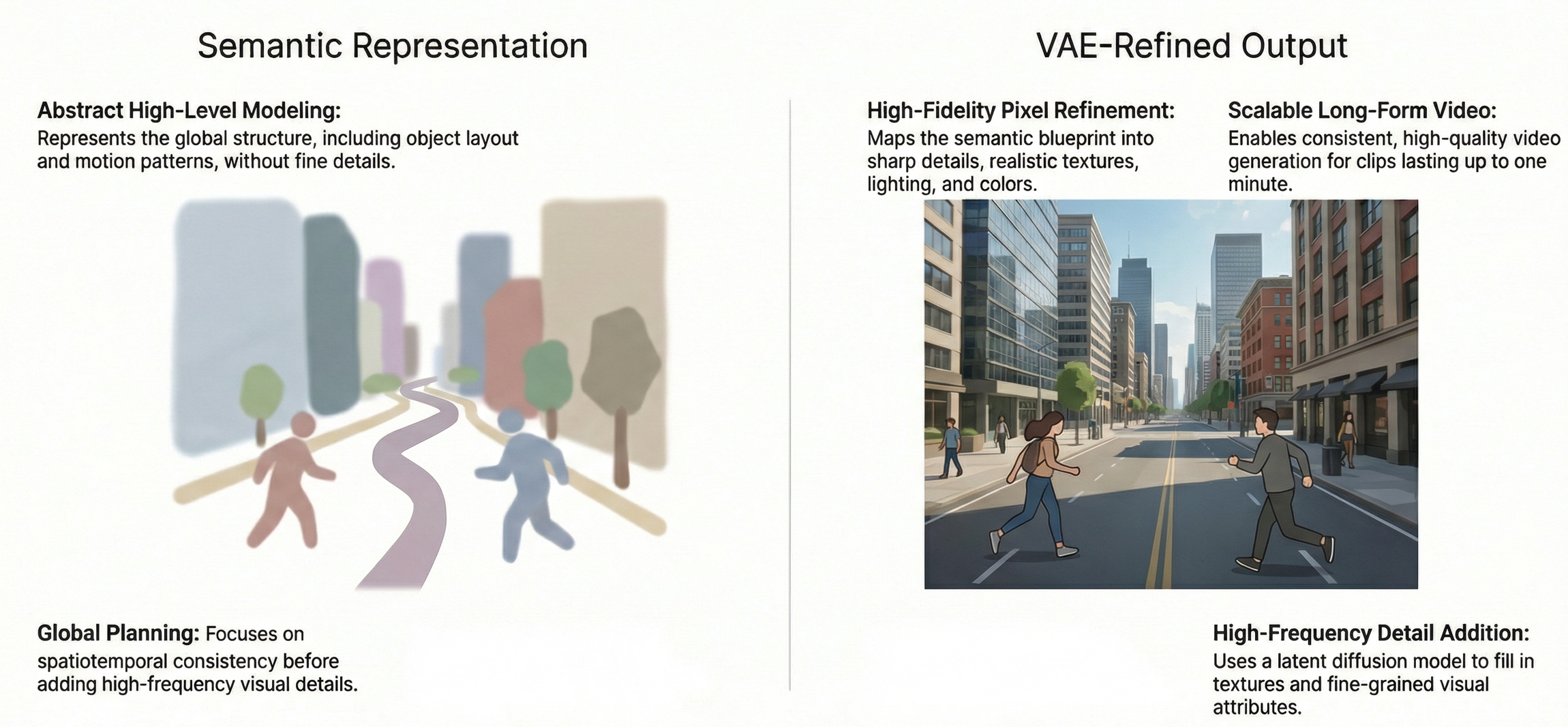
Overview of Two stage
Standard models usually try to learn video distributions directly in a VAE latent space. This is computationally expensive for anything beyond a few seconds.
SemanticGen splits this workload into two distinct, manageable stages. This ensures efficiency without sacrificing narrative control.
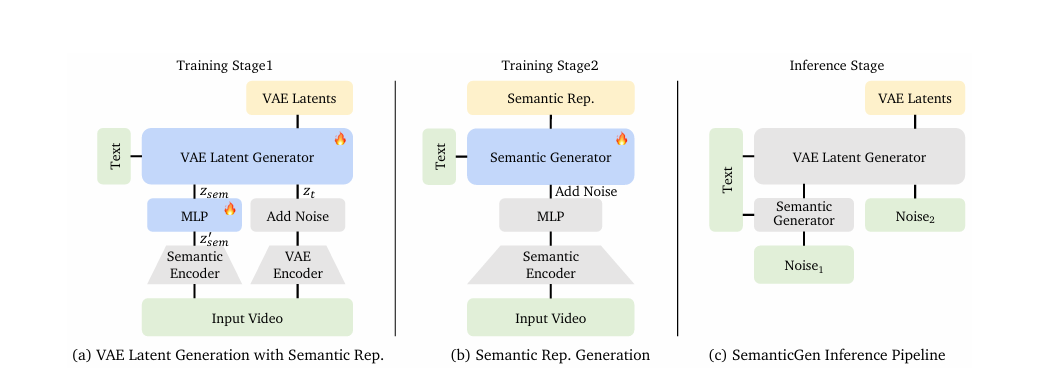
Stage 1: Semantic Representation Generation
In the first stage, the model acts as a "global planner." Rather than worrying about pixel-level details, it focuses on modelling the distribution of compact semantic features derived from the user's text prompt.
This stage creates a high-level "script" or blueprint that dictates the movement, character consistency, and scene transitions for the entire video duration.
By working in this compressed semantic space often 1/16th the volume of standard video tokens the model can perform full-attention calculations over a much longer timeline.
This ensures that the "idea" of the video remains stable; for example, if the prompt describes a person walking through a forest, Stage 1 ensures the forest layout and the person's clothing remain identical from the first second to the last.
Stage 2: VAE Latent Generation
Once the semantic plan is finalized, the framework moves to the VAE (Variational Autoencoder) Latent Generation stage.
In this phase, the model functions as the "lead animator," generating high-resolution video latents that are conditioned explicitly on the semantic features produced in Stage 1.
Because the "what" (the semantic blueprint) has already been decided, the VAE generator can focus entirely on the "how" rendering fine-grained textures, lighting effects, and fluid motion.
The semantic embeddings are injected into the latent generator via in-context conditioning, essentially guiding the denoising process. This ensures that the final visual output doesn't just look realistic, but also adheres strictly to the narrative logic established in the first stage.
Mathematical Framework
To achieve the separation between semantic planning and visual synthesis, SemanticGen relies on a rigorous mathematical formulation based on Conditional Flow Matching.
Instead of using standard diffusion processes, which often follow curved and inefficient trajectories, SemanticGen adopts a Rectified Flow formulation that enforces a straight path from noise to data.
A. Forward Process
The forward process is defined as a linear interpolation between the data distribution and a standard Gaussian noise distribution. Given a data sample z0, the noisy latent at time t ∈ [0, 1] is obtained as:
zt = (1 − t) z0 + t ε
where ε ∼ N(0, I) denotes standard Gaussian noise. As t increases from 0 to 1, the latent variable transitions smoothly from structured data to pure noise along a straight-line path.
B. Denoising Process (Training Objective)
The reverse process is formulated as an ordinary differential equation (ODE) that maps noise back to the data distribution. The time evolution of the latent variable is governed by:
dzt = vΘ(zt, t) dt
where vΘ is a neural network parameterized by Θ, which predicts the velocity field guiding the latent variable toward the data manifold. To train this velocity field, Conditional Flow Matching is used. The training objective minimizes the squared error between the predicted velocity and the target vector field ut:
LCFM = Et, pt(z, ε), p(ε) [ ∥ vΘ(zt, t) − ut(z0 ∣ ε) ∥22 ]
This objective encourages the model to learn the most direct transformation from noise to data, resulting in faster convergence and reduced sampling steps.
C. Euler Discretization for Inference
During inference, the continuous ODE is solved numerically using Euler discretization. Starting from pure noise, the latent variable is updated iteratively as:
zt = zt−1 + vΘ(zt−1, t) Δt
By repeatedly applying this update rule, the model progressively transforms random noise into a coherent semantic representation suitable for subsequent video generation.
Architecture: Encoding and Compression
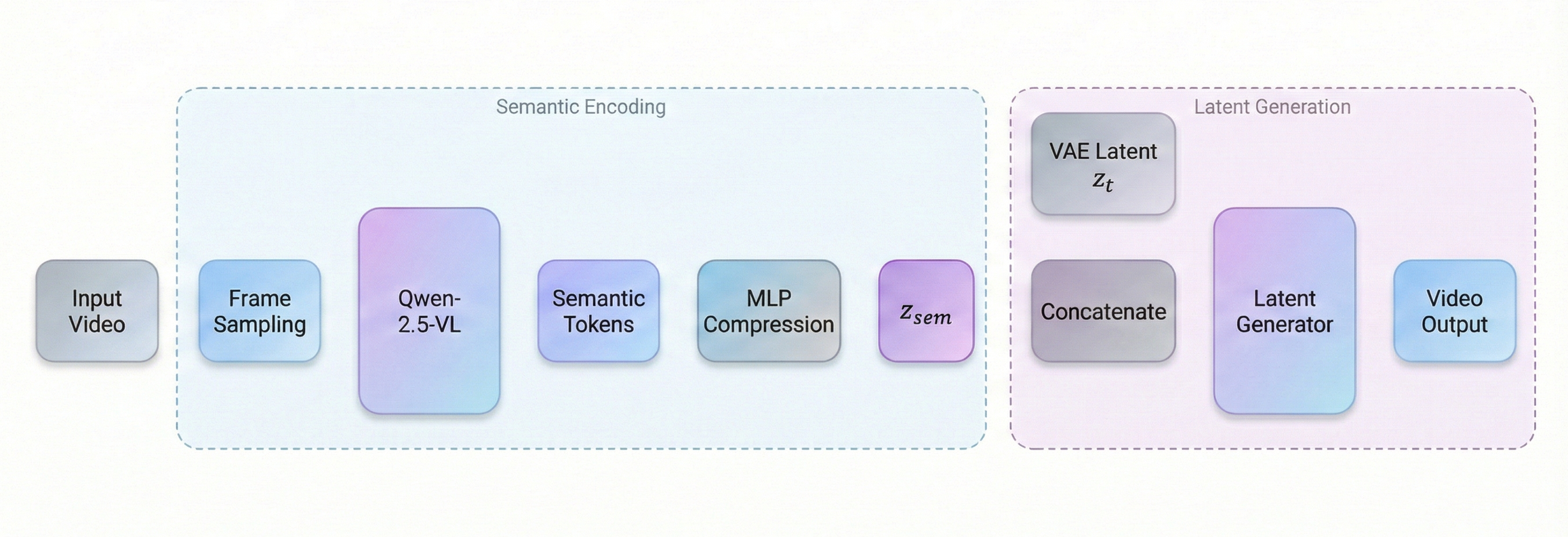
Block Diagram of Architecture
The success of high-level semantic planning depends on how the video is encoded. It employs sophisticated architectural choices to handle this. It uses advanced vision encoders and smart compression techniques.
Semantic Encoding with Qwen-2.5-VL
The framework uses the vision tower of Qwen-2.5-VL as its tokenizer. This is a powerful multimodal model capable of understanding visual context.
It samples video frames at a very low frame rate, typically around 2.0 fps. This captures the "gist" of the scene without the data bloat.
These frames are compressed into high-dimensional representations (zsem′). However, these raw features are often too complex for efficient diffusion.
Compressing the Semantic Space
The initial features are 2048-dimensional. This is difficult for diffusion models to sample from effectively.
To solve this, SemanticGen uses a lightweight Multi-Layer Perceptron (MLP). This network compresses the space down to a manageable size, like 8 or 64 dimensions.
This compressed space is modeled as a Gaussian distribution. A KL divergence objective acts as a regularizer during training to keep the space structured.
In-Context Conditioning
Once compressed, these embeddings (zsem) become the blueprint for the video. They are injected directly into the latent generator.
The model concatenates the noisy VAE latents with these semantic features. This guides the generation process explicitly:
zinput = [ zt , zsem ]
This ensures that every pixel generated in the second stage aligns perfectly with the high-level plan created in the first stage.
Scalability: Solving the Long-Video Problem
Source link.
Generating a 5-second clip is easy. Generating a one-minute video requires managing over half a million tokens.
Standard “Full-Attention” mechanisms scale quadratically. If you double the video length, the computational cost quadruples (O(N2)).
SemanticGen Framework employs a hybrid attention strategy to bypass this limit. It uses different attention types for different stages.
Full-Attention for Semantics
The semantic space is compact. The tokens here are only 1/16th the volume of standard VAE tokens.
Because the data volume is low, SemanticGen can use Full-Attention here. This ensures global consistency across the entire timeline.
The model can "see" the beginning and end of the video simultaneously. This keeps characters and scenes consistent throughout the minute-long duration.
Swin-Attention for Latents
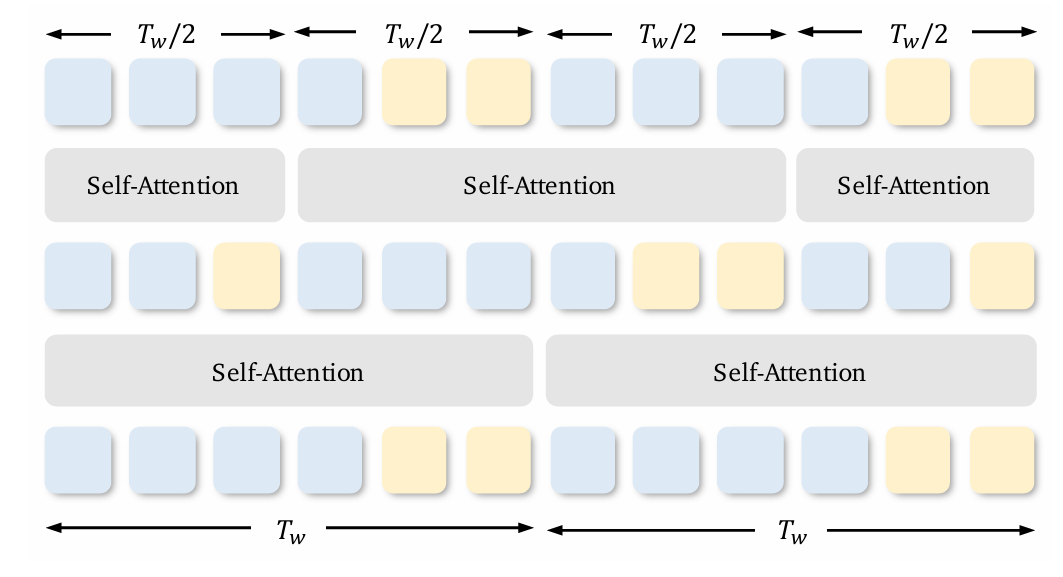
Implementation of Swin-Attention
The VAE latent space is dense and heavy. Using Full-Attention here would crash most GPUs. Instead, the framework uses Shifted-Window (Swin) Attention. It divides tokens into smaller, manageable windows of size Tw.
To ensure information flows between windows, it shifts them by Tw/2 at odd layers. This creates connections without checking every token against every other token.
This strategy prevents the quadratic cost explosion. It allows the generation of long-form content on standard hardware.
Training Methodology
Training
Image Link
The training of SemanticGen is as structured as its architecture. It follows a distinct two-step regimen to ensure stability.
Trying to learn everything at once often leads to model collapse. Separating the training stages improves convergence speed.
Step 1: Fine-Tuning the VAE Generator
First, the VAE latent generator is trained. It learns to denoise latents specifically based on ground-truth semantic conditions.
This teaches the "painter" (Stage 2) how to follow instructions. It ensures that if a semantic plan exists, the visual details will match it.
Step 2: Training the Semantic Generator
Once the generator works, the semantic model is trained. It learns to create the compressed semantic representations from text prompts.
This teaches the "planner" (Stage 1) how to interpret human language. It ensures the blueprints it creates are valid and coherent.
Capabilities and Limitations
No framework is perfect. While SemanticGen offers a leap forward, it comes with specific trade-offs. Understanding these boundaries is crucial for engineers looking to deploy this technology.
Core Capabilities
The primary advantage is long-term consistency. Because of the global semantic planning, characters don't morph randomly.
It also boasts faster convergence. The separation of semantic planning from detailing simplifies the learning task for the model.
The hybrid attention model allows for scalability. Generating minute-long videos is now computationally feasible.
Current Limitations
The focus on high-level semantics can backfire on details. The model sometimes struggles with fine-grained textures in very long videos.
Because the semantic encoder samples at a low frame rate (2.0 fps), it can miss fast events. High-frequency temporal information is lost.
For example, the rapid flickering of lightning might be smoothed out. The model prioritizes the "idea" of the storm over the millisecond-level flash.
The compressed semantic space is efficient but lossy. Extremely subtle visual nuances might be discarded during the compression phase.
Real-World Applications
The SemanticGen Framework opens doors for industries relying on coherent storytelling.
1. Pre-visualization for Film:
Directors can generate minute-long storyboards. The consistency allows them to gauge pacing and scene blocking accurately.
2. Advertising and Social Media:
Marketers can generate full-length ad spots from text. The model ensures the product remains consistent from the first frame to the last.
3. Educational Content:
Complex concepts can be visualized over longer durations. A minute-long explanation of a biological process can remain stable and clear.
Conclusion
We are moving away from the era of glitchy, short AI clips. The future lies in structured, planned video generation.
By treating video as a sequence of meanings rather than a bag of pixels, we unlock true creativity. SemanticGen is the first step toward that reality.
It bridges the gap between efficient computation and high-fidelity output. It proves that in AI, sometimes you have to think big to generate small details.
As hardware improves, the low-level limitations will fade. But the paradigm of semantic planning is here to stay.
What problem does SemanticGen solve in video generation?
SemanticGen solves the long-video consistency problem by separating high-level semantic planning from pixel-level rendering, enabling minute-long coherent videos.
How is SemanticGen different from standard diffusion video models?
Unlike standard models that operate directly on dense VAE latents, SemanticGen first generates compact semantic representations and then refines visuals, reducing redundancy and computation.
Why does SemanticGen scale better for long videos?
SemanticGen uses full-attention only in the compact semantic space and shifted-window attention in VAE latents, avoiding quadratic memory growth.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
