

How does Labellerr ensure pixel-perfect image annotation services for machine learning?

The foundation of computer vision—the labeling of objects within an image with classifications or tags—provides machine learning models with pixel-accurate training data.
The laborious process of categorizing the items in an image so that they may be recognized by machines is known as an image annotation. Consider the scenario where you wished to recognize cats in pictures.
One must annotate millions of cats depending on their color, breed, size, habitat, and other characteristics in order to create an AI-based model that can identify cats.
Here’s how you can ensure pixel-perfect image annotation services for your machine-learning project!
Table of Contents
- Image Annotation: What is it?
- Why is Image Annotation Crucial for Machine Learning and AI?
- Most Common Annotation Technique: The Bounding Box
- Image Annotation with Pixel-Precision
- Tips on How to Do Image Annotation for Attaining Pixel-Perfect Results
- Labellerr Provides 100% Pixel Enforcement
Image annotation: what is it?
Data Annotation that focuses on recognizing and labeling certain details in images is known as an Image annotation. Image annotation in computer vision is adding labels to unprocessed data, including photos and videos. An associated object class with the data is represented by each tag.
Labels are used by supervised machine learning algorithms to identify a particular object class in unstructured data. It enables these models to give meaning to the data, which aids in model training.
Data sets for computer vision algorithms are produced using Image annotation and are divided into training and test/validation sets. The training set is used to train the model initially, while the test/validation set is used to assess the model's performance.
The dataset is used by data scientists to train and test their models, after which the models may automatically categorize hidden unlabeled data.
Why is image annotation crucial for machine learning and AI?
A crucial step in creating supervised models having computer vision abilities is image labeling.
Machine learning models can be trained to label complete images or recognize groups of items within an image. Image annotation services are beneficial in the following ways:
- Image annotation tools and approaches aid in highlighting or capturing specific things in an image, assisting in the development of useful artificial intelligence (AI) models. Machines can now understand labeled images thanks to these labels, and highlighted images are frequently used as training sets for machine learning and artificial intelligence models.
- Enhancing computer vision—by enabling object recognition, image annotation, and annotation aid to enhance computer vision accuracy. Machine learning and artificial intelligence models can recognize patterns before they can detect and recognize them on their own by being trained with labels.
Most common annotation technique: the bounding box
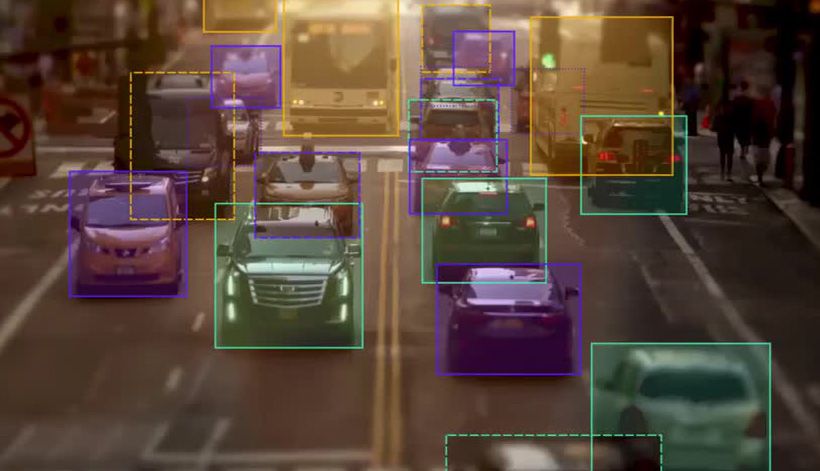
Using Bounding box annotation in a road scenario
The method of fitting a precise rectangle all around the target item is known as a bounding box, and it is the most popular annotating technique. Since bounding boxes are rather simple and so many object detection methods were created with this manner in mind, this is the most common annotation approach (YOLO, Faster R-CNN, etc).
As a result, bounding box annotation solutions are provided by all annotation providers (services or software). Box annotation, however, has several significant drawbacks:
- To achieve over 95% detection accuracy, one needs a sizable (often on the order of 100.000s) amount of bounding boxes. For instance, one typically compiles billions of bounding boxes of vehicles, pedestrians, street lights, roads, cones, etc. for the autonomous driving sector.
- No matter how much data you utilize, bounding box annotation typically prevents you from achieving superhuman detection accuracies. This is primarily due to the additional noise created by the object's proximity to the box region.
- For obscured items, detection becomes extremely difficult. In many circumstances, the target object only occupies 20% or less of the bounding box region, leaving the remainder to act as noise and confusing the recognition algorithm.
Image annotation with pixel-precision
An annotation that is pixel accurate can resolve the bounding box problems. However, the most popular tools for these annotations mainly rely on slow-level object selection tools, requiring the user to navigate the borders of the objects. This is extraordinarily time-consuming, expensive, and highly susceptible to human mistakes.
Such annotation activities often cost roughly 10 times compared to a bounding box annotation, for comparison. Additionally, it can take 10 times longer to appropriately annotate the same number of data pixels. Bounding boxes continue to be the most popular sort of annotation for a variety of applications as a result.
However, over the past seven years, deep learning methods have made significant advancements. While the most advanced algorithm (Alex-net) could only categorize photos in 2012, modern algorithms already can spot things precisely down to the pixel level. The secret to such precise item detection is pixel-perfect annotation.

Evolution of data labeling from 2012-19
Tips on how to do image annotation for attaining pixel-perfect results

Example of Segmentation Scenario
Today, we understand that only excellent datasets result in extraordinary model performance. The robust performance of a model is attributable to an exact and meticulous data labeling procedure.
It's crucial to understand that data labels use a few "tactics" to hone the data labeling procedure and provide excellent results. Please be aware that each dataset has specific labeling guidelines for its labels. As you complete the procedures, keep considering the data as a dynamic phenomenon.
1. Each image's objects of interest should be identified
Computer vision models are developed to discover which pixel patterns correspond to a particular object of interest.
Because of this, we must label each time a particular object appears in our photographs if we want to train a model to recognize it. We will be giving our model false negatives if we don't label the target in some photographs.
For instance, in a dataset of chess pieces, we must identify the appearance of each and every piece on the board; for instance, we would not name just some of the white pawns.
2. The Entire Object Should Be Labeled
The whole boundary of an object of particular interest should be contained inside the bounding boxes. When an object is only partially labeled, our model becomes confused about what a complete object is made up of.
Consider how each chess piece in the dataset is completely encased by a bounding box.
3. Identify Occluded Objects
Occlusion occurs when an object in a picture is partially hidden from view because something is obscuring it. Even obscured things should be labeled if possible. Additionally, rather than creating a bounding box for just the section of the occluded object that is partially visible, it is generally best practice to identify the occluded component as if it was fully visible.
For instance, in the chess dataset, a piece will frequently block another's view. Regardless of whether the boxes overlap, both items need labels. Contrary to popular belief, boxes can overlap.
4. Put together Tight Bounding Boxes
The things of interest should be enclosed in tightly bound boxes. (However, a box shouldn't be so small that it completely encloses an object.) To teach our model precisely which pixels make up the object of interest vs unimportant areas of a picture, precise bounding boxes are essential.
5. Make Unique Label Names
It is preferable to choose the option of being more detailed when choosing a label name for a given object. Being more generic is always simpler to achieve than being more particular, which necessitates relabeling.
Consider making a dog detector as an illustration. Although a dog is an object of interest, it could be a good idea to separate labradors and poodles into their own category.
Our labels might be merged to form the word "dog" while first building the model. However, we would have had to completely rename our dataset if we had begun with "dog" and then understood the value of having distinct breeds.
6. Keep your labeling instructions clear
We will inevitably need to expand our dataset; this is a crucial component of model improvement. We make the most of our labeling time by using strategies like active learning. In order to maintain and develop high-quality datasets, it is crucial for both our present selves and our coworkers to have clear, reproducible, and shareable labeling instructions.
Many of the strategies we've covered here should be used, such as labeling every object, making labels tight, and labeling everything. Always choose the option of greater specificity rather than less.
Labellerr provides 100% Pixel Enforcement
![]()
Using the Segmentation technique on Labellerr's platform for object detection(Here-dogs)
Yes, we are elevating semantic segmentation to a completely new level. Since every pixel needs to be classified, it is extremely accurate. It concentrates on deciphering the image's pixels, which makes it fundamentally very different from other annotation platforms, which are primarily concerned with object detection besides classification.
Pixels are simple to overlook, and I'm sure you can understand how frustrating it is to miss a few little, solitary pixels.
True data quality cannot be achieved unless the datasets are correct and comprehensive, even if you are an annotation manager whose primary responsibility is to ensure that your annotators are providing high-quality data.
The more labels you use, the more challenging this process gets because it's challenging to see the lacking pixels whenever the image is covered in annotations and layers.
We understand that a model can only be as good as its data, thus if an annotator overlooks a few pixels, it compromises the quality of your model and data.
You won't obtain the results you want if there are missing pixels. Additionally, if there are any missing pixels, an error will occur, preventing you from continuing and forcing you to return to the annotation step.
As the annotating process takes a lot of time; in fact, Google researchers determined that labeling an image for the Standard datasets requires an average of 20 mins, and fully analyzing a single image from Cityscapes data takes 1.5 hours. Even more sophisticated segmentation techniques are not mentioned here. Therefore, every second counts when calculating the time needed to annotate.
With Labellerr, you can access various annotating methods that help you deliver the best results. By doing so, you'll be able to identify anything you missed and mark it appropriately, maintaining high quality as you grow. Additionally, there is a hotkey and a highlight feature that will draw attention to the missing pixels.
You can reach out to us for more information!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
