

Enhanced Zero-shot Labeling through the Fusion of DINO and Grounded Pre-training


Table of Contents
- Introduction
- Grounding DINO Architecture
- Applications
- Image Segmentation Using Grounded DINO and SAM
- Image Editing Using Grounding DINO and Stable Diffusion
- Conclusion
- Frequently Asked Questions (FAQ)
Introduction
Visual intelligence requires the ability to understand and detect novel concepts. In the recent CVPR 2023, which occurred in June, a paper was published introducing Grounding DINO. The authors aim to develop a robust system capable of detecting arbitrary objects specified through human language inputs.
They refer to this task as "open-set object detection," which has broad applications as a versatile object detector, such as cooperating with generative image editing models.
The key to open-set object detection lies in incorporating language information for the generalization of unseen objects. Previous approaches like GLIP have shown impressive results by reformulating object detection as a phrase grounding task and employing contrastive training between object regions and language phrases.
However, the authors believe that a stronger closed-set object detector can lead to even better open-set detection results.
Motivated by the success of Transformer-based detectors, the authors propose "Grounding DINO," which builds upon the DINO detector. DINO offers state-of-the-art object detection performance and allows for the integration of multi-level text information through grounded pre-training.
The advantages of Grounding DINO over GLIP include its Transformer-based architecture, making it easier to process both image and language data, as well as its potential for better feature fusion at multiple stages, leading to improved performance.
Existing open-set detectors typically extend closed-set detectors to handle open-set scenarios by introducing language information.
The authors propose three feature fusion approaches to enhance the feature fusion process: a feature enhancer, a language-guided query selection method, and a cross-modality decoder. These approaches enable better interaction between image and language modalities, leading to superior performance in open-set object detection tasks.
In the experimental evaluation, Grounding DINO outperforms competing models by a significant margin on various benchmarks, including COCO, LVIS, ODinW, and RefCOCO/+/g datasets. For instance, it achieves a 52.5 Average Precision (AP) on COCO minival without using any COCO training data and sets a new state-of-the-art on the ODinW zero-shot benchmark with a 26.1 mean AP.
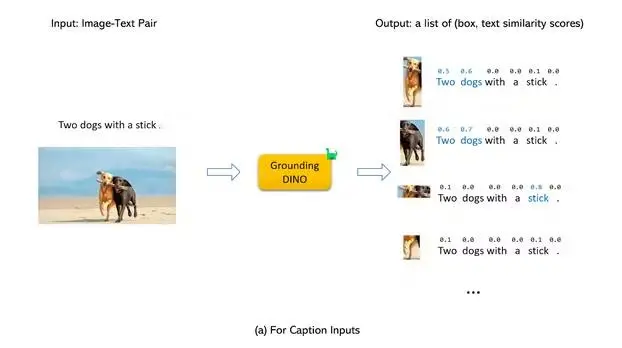
Figure: Grounded DINO
Grounding Dino Architecture
Grounding DINO outputs multiple pairs of object boxes and noun phrases based on an input (Image, Text) pair.
For example, given an input image, the model identifies objects such as a cat and a table and extracts the corresponding labels "cat" and "table" from the input text. This approach aligns both object detection and Referring Expression Comprehension (REC) tasks in the pipeline.
The architecture of Grounding DINO is a dual-encoder-single-decoder design. It consists of an image backbone for extracting image features and a text backbone for extracting text features.
These features are then processed through a feature enhancer module for cross-modality fusion. The model uses a language-guided query selection module to choose relevant cross-modality queries from the image features.
These queries are fed into a cross-modality decoder that updates itself and obtains desired features from both modalities to predict object boxes and extract corresponding phrases.
The model concatenates all category names to handle object detection tasks as input texts. For REC tasks, the model requires bounding boxes for each text input. The output with the highest score from the object detection stage is used as the final output for the REC task.
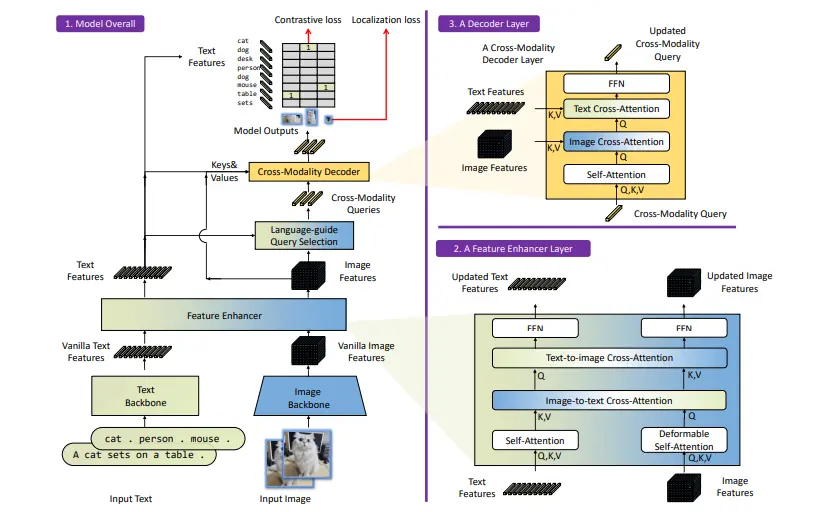
Figure: Architecture For Grounded DINO
Overall, Grounding DINO successfully aligns both image and language modalities, making it effective for various tasks such as object detection and REC. The model outputs object boxes and associated noun phrases, providing valuable information for understanding and interpreting images based on textual inputs.
Feature Extraction and Enhancer
For a given (Image, Text) pair, the model first extracts multiscale image features using an image backbone (like Swin Transformer) and text features using a text backbone (like BERT). Multi-scale features are obtained from different blocks of the backbones.
After extracting vanilla image and text features, the model uses a feature enhancer for cross-modality feature fusion. This feature enhancer includes multiple layers, with each layer leveraging Deformable self-attention for enhancing image features and vanilla self-attention for text features.
Image-to-text and text-to-image cross-attention modules are added to facilitate feature fusion and alignment between different modalities.
Language-Guided Query Selection
Grounding DINO introduces a language-guided query selection module to enhance object detection using input text. This module selects relevant features from image and text inputs and uses them as decoder queries.
The query selection process is outlined in the below image in PyTorch style. The module outputs a set of indices corresponding to the selected queries, and features can be extracted based on these indices to initialize the decoder queries.
The number of queries, denoted as "num_query," is set to 900 in the implementation.
Other variables such as "bs" (batch size) and "ndim" (feature dimension) are also used in the pseudo-code. "num_img_tokens" and "num_text_tokens" also represent the number of image and text tokens, respectively.
The language-guided query selection module combines both image and text features to form decoder queries.
These queries consist of two parts: the content part and the positional part. The positional part is formulated as dynamic anchor boxes initialized with encoder outputs, while the content queries are learnable during training.
This approach follows the concept introduced by DINO for initializing decoder queries using mixed query selection.
.webp)
Figure: Language Guided Query Selection
Cross-Modality Decoder
The researchers introduced a cross-modality decoder to combine image and text features, with each cross-modality query undergoing processing through self-attention, image cross-attention, text cross-attention, and an FFN layer.
The decoder layers were enhanced with an additional text cross-attention layer to align text information with the queries better and improve modality fusion. This approach aimed to effectively integrate information from both image and text modalities in their model.
Sub-Sentence Level Text Feature
Previous research explores two types of text prompts: sentence-level representation and word-level representation. Sentence-level representation encodes an entire sentence into a single feature, but it may lose fine-grained information if the sentence contains multiple phrases.
Word-level representation allows encoding multiple category names in one pass but introduces unnecessary dependencies, especially when the input text combines multiple category names in arbitrary order.
To address this, researchers propose a new approach called "sub-sentence" level representation, which uses attention masks to prevent interactions among unrelated category names. This approach retains per-word features, facilitating a more detailed understanding while eliminating unwanted word interactions.
Loss Functions
The authors follow previous DETR-like works and use the L1 loss and GIOU loss for bounding box regressions. They adopt contrastive loss between predicted objects and language tokens for classification, calculating logits for each text token through dot product with query embeddings and computing focal loss for each logit.
The box regression and classification costs are used for bipartite matching between predictions and ground truths. The authors also add auxiliary loss after each decoder layer and after the encoder outputs, following the DETR-like model design.
Applications
Grounded DINO has various applications in the fields of computer vision and natural language processing. Some of the key applications include:
- Open-Set Object Detection: Grounded DINO can be used to detect arbitrary objects specified by human language inputs. It extends the capabilities of traditional object detectors by incorporating language information, enabling the model to detect novel and unseen objects.
- Referring Expression Comprehension: Grounded DINO is well-suited for the task of referring expression comprehension. It can accurately identify and locate objects or regions in images based on textual descriptions, making it useful for tasks such as image captioning and human-robot interaction.
- Image Editing and Manipulation: Grounded DINO can be used in image editing and manipulation tasks, where language inputs can guide the model to modify specific objects or regions in the image according to textual instructions.
- Natural Language Interaction with Visual Data: Grounded DINO facilitates natural language interaction with visual data. It enables users to describe objects or scenes using natural language, making it useful for applications like smart assistants and human-computer interaction.
- Visual Question Answering: Grounded DINO can be applied in visual question-answering tasks, where the model can understand and respond to questions about images based on textual inputs.
- Visual Content Understanding: Grounded DINO can contribute to a deeper understanding of visual content by bridging the gap between language and visual representations, enabling a more comprehensive analysis of images and videos.
Image Segmentation Using Grounded DINO and SAM
In this section, we will demonstrate the implementation of a zero-shot object segmentation pipeline by combining Grounding-DINO with the Segment Anything Model (SAM), which is a state-of-the-art visual foundation model developed by Meta.

Figure: Image Segmentation with Grounded DINO and SAM
Grounded DINO
Grounded DINO is a self-supervised learning algorithm that utilizes grounded pre-training, effectively incorporating both visual and textual information.
This combined approach enhances the model's capability to detect and recognize previously unseen objects in real-world scenarios, leading to improved performance in open-set object detection tasks compared to existing methods.
When given an input pair of images and text, Grounding-DINO outputs 900 object boxes along with their objectness confidence. Each box is associated with similarity scores for each word in the input text. The model then performs two selection processes:
- The algorithm selects the boxes that have objectness confidence above a predefined box_threshold.
- For each selected box, the model extracts the words whose similarity scores are higher than the specified text_threshold.
While Grounding-DINO provides bounding boxes, it only solves part of the task. Another foundation model called the Segment Anything Model (SAM) is employed to achieve object segmentation. SAM utilizes the bounding box information from Grounding-DINO to segment the objects effectively.
Segment Anything Model (SAM)
The Segment Anything Model (SAM) is an advanced image segmentation model that represents a significant breakthrough in the field of computer vision.
Developed by Meta, SAM is built on foundation models and specializes in promptable segmentation tasks. It leverages prompt engineering techniques to adapt effectively to various downstream segmentation challenges.
SAM's design revolves around three key components:
- The promptable segmentation task, enabling zero-shot generalization, allows the model to handle new segmentation tasks without explicit training.
- The model architecture forms the backbone of SAM and contributes to its exceptional performance.
- The dataset that fuels the task and model provides essential training data for achieving high-quality segmentation results.
Grounded DINO with SAM
Combining Grounding-DINO and SAM enables us to achieve a comprehensive segmentation pipeline. Grounding-DINO can efficiently provide the most relevant bounding boxes for a given text prompt and image.
On the other hand, SAM excels in generating segmented masks within bounding boxes when provided with an image and bounding box information.
By stacking these two components together, we can seamlessly integrate them. As a result, when given an image and text prompt (which includes the desired classes), we can obtain accurate and precise segmentation results for the specified objects.

Figure: Object set Object Segmentation
Image Editing Using Grounding DINO and Stable Diffusion
In the below image, we see how by just giving input an image and different prompts, the image editing tasks are happening. Below, given an image of pandas and 2 different prompts:
- Detection of pandas
- Generation of images of dogs and cakes in their place.
The output image returned is the same image with the given replacements.

Figure: Grounding DINO with stable diffusion
These results are generated through a two-step process. First, the object detection phase is performed using Grounding DINO. This step involves detecting objects in the images by providing a "detection prompt" as the language input to Grounding DINO.
The model generates bounding boxes for the detected objects and creates masks by masking out the detected objects or backgrounds.
Next, the inpainting phase takes place. The original images, image masks generated in the previous step, and "generation prompts" are fed to an inpainting model, typically Stable Diffusion.
The inpainting model uses this information to render new images, completing the regions covered by the masks. The inpainting model can be found in the released checkpoints available here.
In this process, the "detection prompt" serves as the language input for Grounding DINO, guiding the object detection process. On the other hand, the "generation prompt" is used for the inpainting model to complete the masked regions in the final images.

Figure: Image Editing using Grounding DINO
Combining Grounding DINO with GLIGEN
A combination of Grounding DINO with GLIGEN is used to enhance fine-grained image editing capabilities. This approach uses a "phrase prompt" from the input phrases for each bounding box in GLIGEN.
GLIGEN is designed to accept grounding results as inputs and can generate objects at specific positions in the image. By utilizing GLIGEN, individual objects are assigned to each bounding box, resulting in bounding boxes with associated objects.
Furthermore, GLIGEN can fill each bounding box, resulting in improved visualizations, with each bounding box containing an object and the detected regions properly fulfilled.
This integration of Grounding DINO and GLIGEN allows for more precise and visually appealing fine-grained image editing, enabling object placement and fulfillment within specified regions.

Figure: Each detected panda image is replaced by Phrase Prompt
Conclusion
In conclusion, the Grounding DINO model presented in this research extends DINO to handle open-set object detection, enabling the detection of arbitrary objects using human language inputs.
The model design includes a tight fusion approach to effectively integrate cross-modality information, a sub-sentence level representation for more reasonable text prompts, and a cross-modality decoder to combine image and text features.
The results demonstrate the effectiveness of the proposed model, outperforming competing models on various benchmarks.
The research also extends open-set object detection to Referring Expression Comprehension (REC) tasks and evaluates the model's performance accordingly. However, the model has some limitations, such as its inability to handle segmentation tasks like GLIPv2 and the smaller training data compared to larger models like GLIP.
There are certain acknowledged limitations, stating that Grounding DINO is not suitable for segmentation tasks and that the smaller training data may impact the final performance compared to the largest GLIP model.
Frequently Asked Questions (FAQ)
1. What is Grounded Training?
Grounded training is a training approach in machine learning that involves using additional information or external knowledge to improve the learning process. In the context of vision and language tasks, grounded training aims to combine visual and textual information to enhance the model's understanding and performance.
In grounded training for vision and language tasks, such as image captioning, object detection, or referring expression comprehension, the model is trained using both image data and corresponding textual descriptions or annotations.
The textual information provides grounding or context for the visual elements in the images, enabling the model to learn associations between visual features and their corresponding linguistic representations.
2. What is referring to expression comprehension (REC)?
Referring Expression Comprehension (REC) is a natural language processing (NLP) and computer vision task that involves understanding and interpreting language expressions used to refer to specific objects or regions within images.
REC aims to develop models that can accurately identify the objects or regions being referred to in the image based on the given textual descriptions.
3. What is Open Set Object Detection?
Open-Set Object Detection is a training approach that uses existing bounding box annotations and aims to detect arbitrary classes by leveraging language generalization.
OV-DETR utilizes image and text embeddings from a CLIP model as queries to decode category-specified boxes within the DETR framework.
ViLD distills knowledge from a CLIP teacher model into an R-CNN-like detector, allowing learned region embeddings to incorporate language semantics.
GLIP treats object detection as a grounding problem, utilizing additional grounding data to align semantics at the phrase and region levels, resulting in improved performance on fully-supervised detection benchmarks.
DetCLIP involves large-scale image captioning datasets and employs generated pseudo labels to expand the knowledge database, effectively enhancing the detectors' generalization ability.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
