

Genie 3 by Google DeepMind Is Not a Video Generator It’s a World Builder
Genie 3 by Google DeepMind is a real-time 3D world model that creates interactive, persistent environments. It enables scalable egocentric data for robotics training, helping embodied AI learn navigation, perception, and long-horizon reasoning.

AI is moving into a fundamentally new stage. For years, progress meant better image generators, more fluent chatbots, and increasingly realistic video models.
But a new class of systems is emerging, models that do not just describe the world, but can simulate it.
In August 2025, Google DeepMind introduced Genie 3, a general-purpose real-time 3D world model that marks a major step toward this new paradigm. Genie 3 is not a conventional video generator. It does not simply play back a clip.
Instead, it creates a navigable, interactive environment that responds continuously to user or agent actions.
This capability changes what AI-generated media can be used for. Rather than passively watching content, researchers and agents can move through it, interact with it, and learn from it. For robotics and embodied AI in particular, this shift is critical.
The Architectural Shift Behind Genie 3
video source
Earlier generative models focused on producing single outputs like an image, a paragraph, or a short video clip. Even advanced video models struggled with interaction. Once generated, the sequence was fixed. There was no ability to ask, what happens if I turn left? or What if it starts raining now?
Genie 3 breaks that limitation. Instead of generating a fixed sequence, it produces a persistent 3D world that evolves over time.
The environment reacts to movement, camera changes, and high-level instructions. Objects remain where they were placed. Physics continues to apply even when they leave the field of view.
This shift from media generation to world simulation is what makes Genie 3 especially relevant for robotics and embodied intelligence.
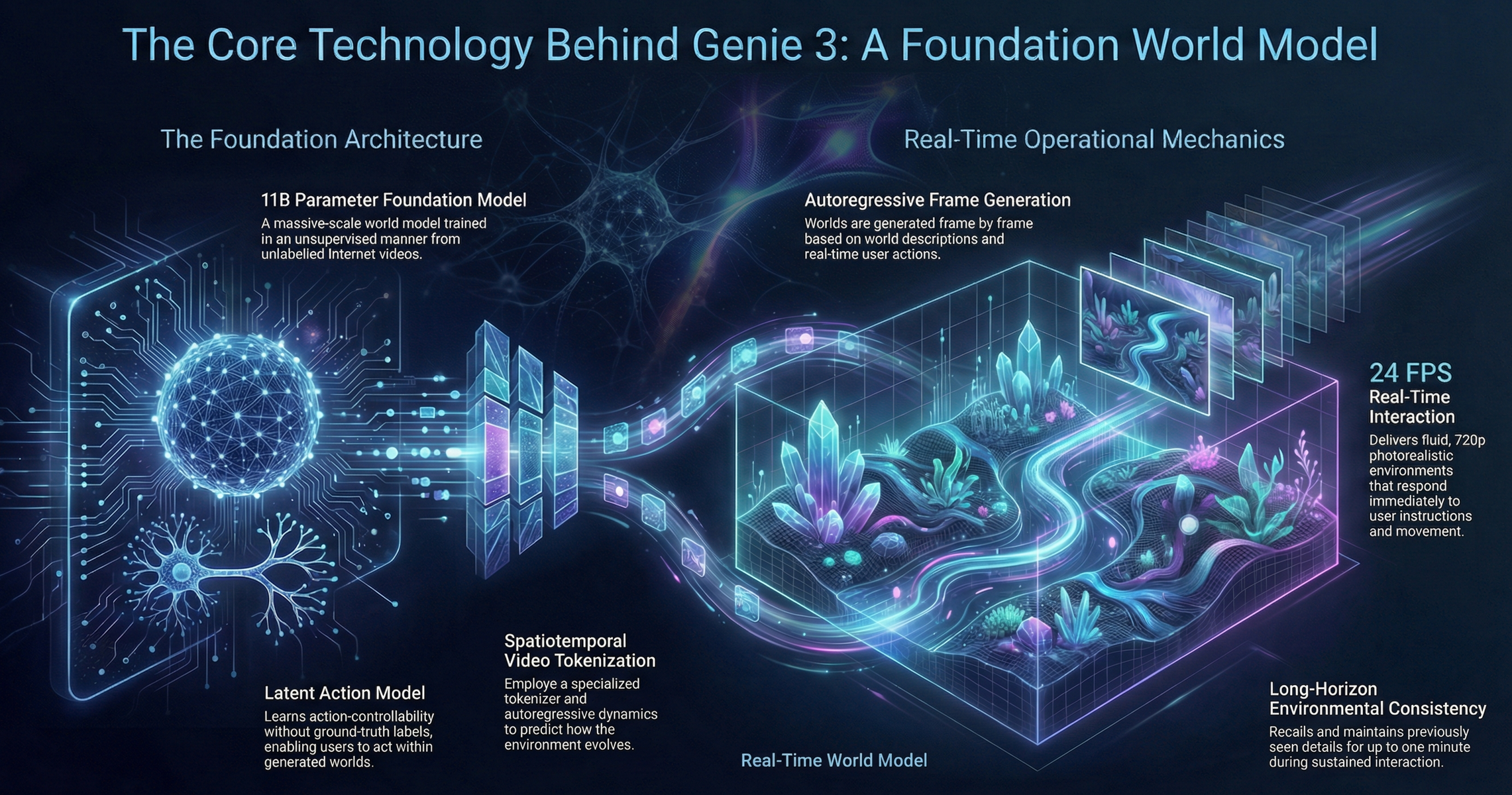
The Core Technology Behind Genie 3
Overview of Genie3
Real-Time Performance
Genie 3 operates at 24 frames per second (fps) with a 720p resolution, a deliberate design choice. This frame rate aligns with cinematic standards and is fast enough to support smooth, continuous interaction.
Unlike earlier prototypes that allowed only brief exploration windows of 10–20 seconds, Genie 3 supports several minutes of uninterrupted navigation. That time scale is essential for tasks that require planning, memory, and goal-oriented behavior.
An Auto-Regressive World Model
At its core, Genie 3 uses an auto-regressive architecture. Rather than rendering an entire world at once, it predicts the next frame based on:
- The current visual state
- The internal world representation
- The actions taken by the user or agent
Each new frame depends on what came before it. This approach allows Genie 3 to model causality. When something changes in the environment, future frames reflect that change consistently.
If an agent turns a corner, the new view is not a random hallucination it is a continuation of the same world.
Spatial Memory and Consistency
One of the hardest challenges in generative environments is memory. Traditional video models often fail when the camera looks away and then returns, causing objects to disappear or reappear incorrectly.
Genie 3 addresses this with a spatial memory window of roughly one minute, allowing it to retain object locations, environmental structure, and ongoing physical states even when they are out of view.
This ensures the environment remains coherent when revisited an essential property for robotics training, where real-world navigation depends on remembering what cannot be seen.
Interactive Worlds, Not Static Scenes

Genie 3: Real-Time 3D Worlds Responding to Interaction
Promptable World Events
One of Genie 3’s most powerful features is real-time world modification. The environment can change while exploration is ongoing. Simple text prompts are enough to trigger these shifts.
Weather can turn from clear skies to a thunderstorm. New objects or characters can appear instantly. Lighting and time of day can change on demand.
Crucially, the world does not reset. It adapts and continues. For intelligent agents, this enables realistic testing of behavior under sudden and unexpected changes just like in the real world.
Visual and Stylistic Diversity
Genie 3 is not limited to photorealistic scenes. It can generate a wide range of visual styles. These include natural landscapes like forests, oceans, and volcanic terrain. It can also create urban environments under different weather and lighting conditions.
Beyond realism, Genie 3 can produce stylized worlds. Scenes may resemble watercolor paintings, or abstract materials. This diversity is not just visual flair.
Training agents across varied visual domains reduces overfitting and makes models more robust when they face unfamiliar environments.
Physics-Aware Simulation
Genie 3 incorporates a deeper understanding of physical dynamics, informed by earlier world-modeling research such as Veo. This allows environments to behave in more realistic ways.
Water can move and react dynamically. Surface friction can change across different terrain. Aerodynamic effects influence moving or flying objects. When an agent drives through water, splashes appear. When the ground changes, movement adapts accordingly.
These details are not just visual polish. They provide realistic sensory feedback, which is critical for embodied learning and physical reasoning.
Access and Research Status
As of early 2026, Genie 3 is available primarily through limited research previews. Access has been granted to selected academic and creative partners to explore capabilities and identify failure modes.
A broader experimental rollout is underway via Project Genie in Google Labs for Google AI Ultra subscribers in the United States.
Early users are encouraged to document physics anomalies, memory inconsistencies, and interaction limits to guide future development.
Core Use Case: First-Person Data for Robotics
One of the core use cases of world models like Genie 3 is generating first-person data for robotics training. Robots need to learn from their own viewpoint as they move and interact with the world. Genie 3 enables this by simulating realistic, egocentric experiences at scale.
What Egocentric Data Really Means
video source
Egocentric data is captured from the first-person perspective of an agent. For robots, this includes visual input and sensor signals aligned with their own position, motion, and actions in the environment.
This perspective is fundamentally different from third-person datasets. Instead of observing behavior from the outside, egocentric data reflects what the robot actually sees while acting in the world. Every turn, obstacle, surface change, and interaction unfolds directly through the robot’s viewpoint.
For robotics, this kind of data is not optional. Navigation, manipulation, and decision-making all depend on how the world appears from the agent’s own frame of reference. Yet collecting egocentric data at scale has remained one of the hardest problems in embodied AI.
The Traditional Bottleneck
Historically, egocentric robotics data has come from two constrained approaches.
The first is real-world data collection. While realistic, it is slow, expensive, and risky. Robots break. Sensors drift. Dangerous or rare scenarios are difficult to capture repeatedly. Scaling this process requires significant time and hardware investment.
The second approach is hand-built simulation. These environments are safer and cheaper, but often lack realism and diversity. Physics is simplified. Visual variation is limited. Interactions are scripted. As a result, models trained purely in these settings struggle to generalize outside controlled conditions.
Because of these limitations, progress in embodied AI has often been bottlenecked not by algorithms or compute, but by the availability of high-quality first-person training data.
What Genie 3 Makes Possible
video source
Genie 3 is not a robotics simulator, and it is not designed specifically for egocentric data generation. However, its core capabilities persistent 3D worlds, real-time interaction, spatial memory, and causal consistency introduce a fundamentally different substrate for exploring first-person experience.
In Genie 3, environments are not static scenes. They evolve continuously in response to movement and actions. As an agent navigates, the camera view updates in real time. Terrain, lighting, weather, and physical interactions influence what the agent perceives.
Crucially, Genie 3 maintains spatial consistency over time. Objects remain where they were placed. Previously visited areas stay coherent when revisited. This allows agents to experience environments as continuous spaces rather than short, disconnected clips.
From an egocentric perspective, this matters deeply. It enables first-person trajectories where perception, action, and memory are tightly coupled closer to how real robots operate in the physical world.
First-Person Interaction and Long-Horizon Behavior
Genie 3 supports multi-minute interaction, it allows exploration of longer-horizon behaviors that traditional simulations struggle to support.
Agents can move toward distant goals. They can remember where they have been. They can adapt strategies after mistakes. Visual input changes naturally as the agent turns, accelerates, or encounters obstacles.
This creates a perception action loop that mirrors real-world robotics challenges, even though the environment itself is synthetic.
For researchers, this opens the door to experimenting with richer first-person experiences that were previously expensive or impractical to study.
Bridging World Models and Scalable Robotics Datasets
While Genie 3 introduces a powerful way to explore first-person interaction, turning these experiences into usable, training-ready datasets is a separate challenge.
At Labellerr, we are actively experimenting with Genie 3 that how egocentric data can be structured, annotated, and scaled for robotics and embodied AI.
This includes organizing visual streams, aligning annotations and ensuring consistency across large datasets whether data comes from simulation, real-world collection, or hybrid setups.
For teams exploring first-person learning and embodied AI, Labellerr acts as the data layer that bridges experimentation and production.
If you’re working on robots that need to see, reason, and act from their own perspective, you can explore our robotics data workflows or book a demo here:
https://www.labellerr.com/robotics-data
World models are expanding what can be explored. Scalable data infrastructure determines what can actually be trained. Together, they define the next phase of embodied AI
Current Limitations
Genie 3 is a major step forward, but it is still a research prototype. Several limitations remain that define its current scope.
Limited physical interaction
Genie 3 handles navigation and basic movement well, but complex physical manipulation is still constrained. Fine-grained interactions like grasping, tool use, or multi-step object handling are not yet reliable. This limits training for robots that require dexterous control.
Inconsistent text and symbols
Text inside generated environments is often unstable. Signs, labels, or written instructions may appear distorted or unreadable. This makes Genie 3 less suitable for tasks that depend on accurate text perception.
No exact real-world replication
The model generates realistic environments, but they are not geographically precise. Specific real-world locations cannot be recreated with exact layout or scale. This restricts direct use for location-specific robotics deployment.
Single-agent focus
Genie 3 performs best with one active agent. Simulating multiple independent agents with consistent physics, perception, and causality remains an open challenge. Multi-robot coordination is still limited.
Bounded interaction time
World consistency is maintained for minutes, not hours. This is enough for research experiments, but not for long-duration simulations or full-scale digital twins.
Conclusion
Genie 3 represents a meaningful shift in how artificial intelligence is built. Instead of focusing solely on perception or language, it emphasizes world understanding the ability to model space, time, causality, and interaction.
For robotics, its ability to generate high-fidelity egocentric data in diverse, interactive environments addresses one of the field’s longest-standing challenges. It offers a safe, scalable, and flexible training ground where embodied agents can learn through experience.
While still experimental, Genie 3 points toward a future where AI systems do not just process data, but inhabit worlds. As these models grow more stable, longer-lasting, and more precise, the boundary between simulation and reality will continue to narrow.
The era of world models has begun and Genie 3 is one of its clearest signals yet.
What makes Genie 3 different from traditional AI video models?
Genie 3 generates persistent, interactive 3D worlds instead of fixed video clips, allowing agents to move, interact, and experience cause-and-effect in real time.
Why is egocentric data critical for robotics training?
Egocentric data captures the world from a robot’s own perspective, enabling it to learn navigation, perception, and decision-making as it would in real-world conditions.
How does Genie 3 help overcome data limitations in embodied AI?
By simulating diverse, realistic environments at scale, Genie 3 enables safe, cost-effective generation of first-person training data without relying solely on real-world collection.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
