

Gemma 4 12B : Run Locally, Fine-Tune, Benchmark Performance
Google Gemma 4 12B introduces an encoder-free multimodal architecture that natively processes text, images, audio, and video. Learn how it works, benchmark results, fine-tuning advantages, and how to run it locally on consumer hardware.


Most open-source multimodal models come with a trade-off. You either get strong vision and audio understanding, or you get a model small enough to run locally, not both. Gemma 4 12B breaks that rule.
Released by Google DeepMind on June 3, 2026, Gemma 4 12B is the first medium-sized open model to natively process text, images, audio, and video, without a single separate encoder. It runs on a 16GB VRAM laptop. That is not a compromise build. It is a deliberate architectural shift.
This guide covers what makes Gemma 4 12B different, how its architecture works under the hood, what the benchmarks actually show, and how to run it locally using Hugging Face.
What Is Google Gemma 4 12B?
Gemma 4 12B is a dense, decoder-only multimodal model from Google DeepMind. It is part of the Gemma 4 family, which includes edge models (E2B, E4B), a 12B dense model, and a 26B dense model.
The 12B is the first in the Gemma family to support audio input at medium scale. Previous audio-capable Gemma models were limited to small edge sizes. It also marks the debut of an encoder-free multimodal design at this parameter count.
The model is fully open. Weights are available on Hugging Face and Kaggle under the Gemma license.
The Architecture - Encoder-Free and Unified

architecture overview
This is where Gemma 4 12B diverges from every prior Gemma release.
Traditional multimodal models bolt separate encoders onto a language backbone. A frozen vision encoder (150M–550M parameters) processes images. A separate audio encoder (up to 300M parameters) handles sound. Each encoder runs its own forward pass before the LLM ever sees a token. That means multiple memory footprints, compounding latency, and frozen weights you cannot fine-tune end-to-end.
Gemma 4 12B solves this by using a single decoder-only transformer, the same advanced decoder structure used in the Gemma 4 31B Dense model, to handle all modalities directly.
There are three key components:
Vision Embedder (35M parameters)
This replaces the 27 vision transformer layers found in other medium-sized Gemma 4 models. Raw 48×48 pixel patches are projected to the LLM hidden dimension with a single matrix multiplication. A factorized coordinate lookup, X and Y matrices, attaches spatial location information directly to each input patch.
No ViT backbone. No multi-layer visual feature extraction. One matmul.
Audio Wave Projection
This eliminates the separate audio encoder entirely, skipping the 12 conformer layers used in Gemma 4 E2B and E4B. Raw 16 kHz audio signals are sliced into 40ms frames (640 floats each) and projected linearly into the LLM input space.
The model hears audio the same way it reads text, as projected tokens in the same embedding space.
Unified Fine-Tuning
Because vision, audio, and text inputs share the exact same weights, you no longer need to co-tune separate frozen encoders. Downstream adapter fine-tuning (such as LoRA) or full fine-tuning naturally updates the entire multimodal token loop in a single pass.
This matters for teams building domain-specific multimodal models. One training loop. One set of weights. Cleaner pipelines.
Benchmark Results
The benchmark numbers are strong, especially given the model's size.
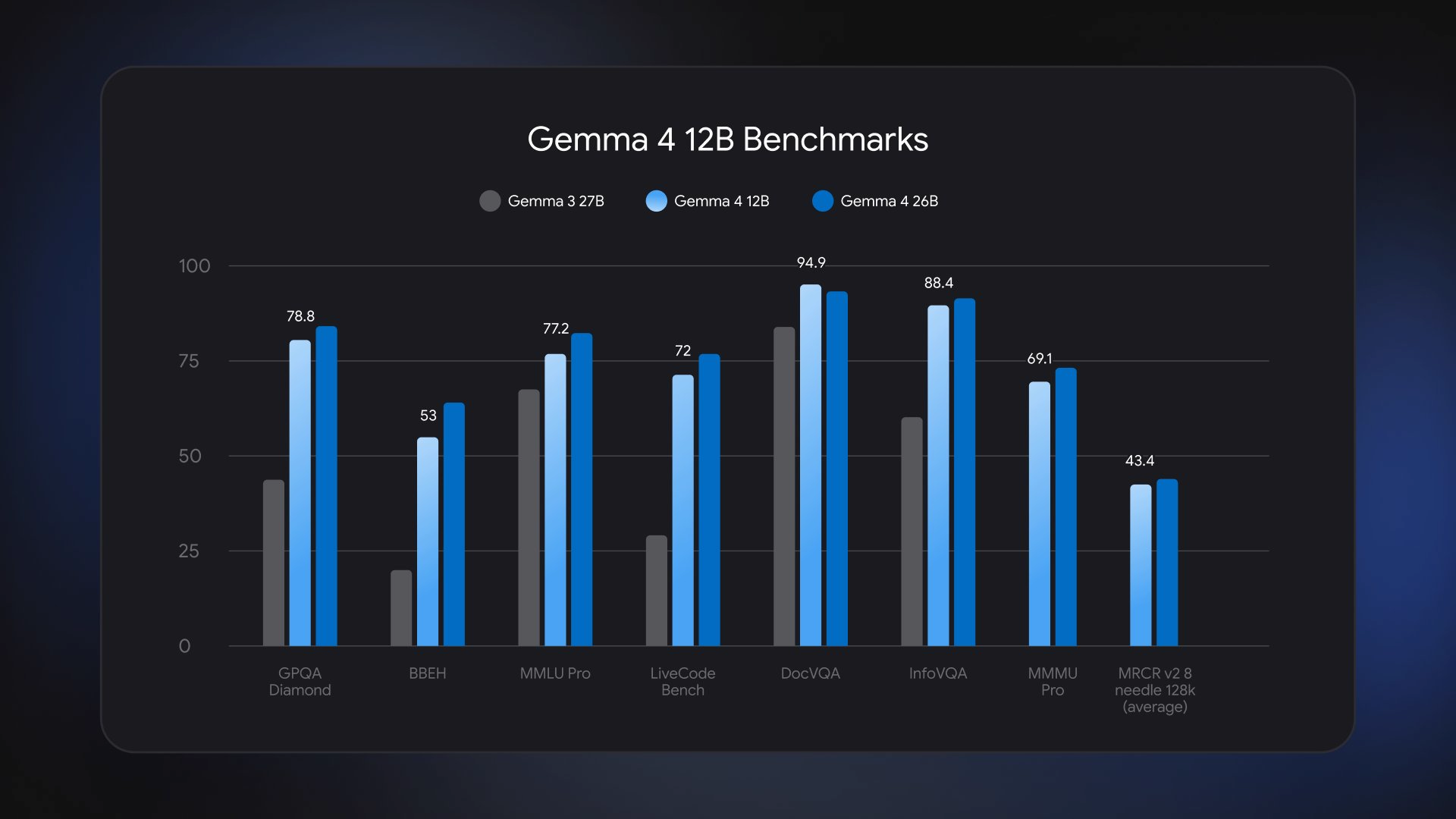
Gemma 4 12B Benchmarks
Here is what the chart shows:
On GPQA Diamond (graduate-level reasoning), Gemma 4 12B scores 78.8. That is well above where a 12B model has any right to be, and it sits close to the 26B variant.
On BBEH (a broad suite of hard reasoning tasks), the 12B scores 53, a steep jump from Gemma 3 27B's ~18. The architecture clearly helps here.
On DocVQA (document visual question answering), the 26B tops the chart at 94.9, with the 12B trailing closely. Both outperform Gemma 3 27B by a wide margin. This is where the encoder-free vision design pays off, document understanding benefits from spatial token encoding done well.
On LiveCode Bench (competitive coding tasks), the 12B scores 72, solidly above average for its size class.
On MMMU Pro (multimodal university-level tasks), the 12B scores 69.1. Again, within striking range of the 26B.
On InfoVQA, the 12B reaches 88.4, matching the 26B almost exactly.
The takeaway: Gemma 4 12B punches above its weight on every vision and reasoning task. The BBEH improvement over Gemma 3 27B is the most dramatic data point, a larger previous-gen model loses to a newer, smaller one.
Capabilities at a Glance
Gemma 4 12B supports automatic speech recognition, agentic reasoning, diarization, video understanding, and coding.
The video understanding is worth noting separately. The model was tested on a 5-minute video segment from the Google I/O Keynote, processing 313 frames at 1 FPS alongside the corresponding audio, then answering questions about what happened in the video. That is real multimodal context, not just image captioning.
video source
How to Run Gemma 4 12B Locally Using Hugging Face
The model is available at: https://huggingface.co/google/gemma-4-12B
The instruction-tuned variant (recommended for most use cases) is at google/gemma-4-12B-it.
Step 1: Install dependencies
pip install transformers accelerate torch
Step 2: Authenticate with Hugging Face
You need to accept the Gemma license on the model page, then log in:
huggingface-cli login
Step 3: Load the model
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "google/gemma-4-12B-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Step 4: Run inference
inputs = tokenizer("Explain encoder-free multimodal design in simple terms.", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
For multimodal (image + text) input, use AutoProcessor instead of AutoTokenizer. The processor handles patch extraction and projection automatically.
Hardware requirement: 16GB VRAM (GPU) or unified memory. On CPU, expect slow inference, the model is dense at 12B parameters with no quantization by default. For CPU-only setups, use the GGUF quantized build via Ollama (ollama run gemma4:12b-it-q4_K_M) or llama.cpp.
On-Device Serving Options
For developers who want a local API server rather than a Python script, Google ships three options:
LiteRT-LM serve runs Gemma 4 12B as a local, OpenAI-compatible API server. It supports stateless prefix caching in memory to match context history and instantly bypass prefill latency.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm \gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve
This gives you an endpoint at localhost:9379 that works with any tool expecting an OpenAI-compatible API, including Aider, Continue, and OpenCode.
The Google AI Edge Gallery app, now available on macOS, showcases the model's coding capability and lets you execute Python scripts on-device. The Google AI Edge Eloquent app adds fully offline voice dictation and text editing powered by the 12B model, with a new Voice Edit feature that allows you to restructure or translate text using voice commands alone.
Fine-Tuning Gemma 4 12B
The unified architecture changes fine-tuning significantly.
With encoder-based models, you typically freeze the vision encoder and only train the LLM layers. Fine-tuning the encoder too risks breaking pretrained representations. You end up with partial updates and mismatched gradients.
With Gemma 4 12B, there are no frozen encoders. A LoRA adapter or full fine-tune naturally updates the entire multimodal token loop in a single pass via Hugging Face or Unsloth.
For task-specific fine-tuning, such as document annotation, egocentric video understanding, or audio transcription, this is a meaningful practical advantage. Your fine-tune touches every pathway the model uses to process your domain's data.
Unsloth is the recommended tool for efficient fine-tuning on consumer hardware. It reduces VRAM usage significantly and supports the Gemma 4 12B architecture natively.
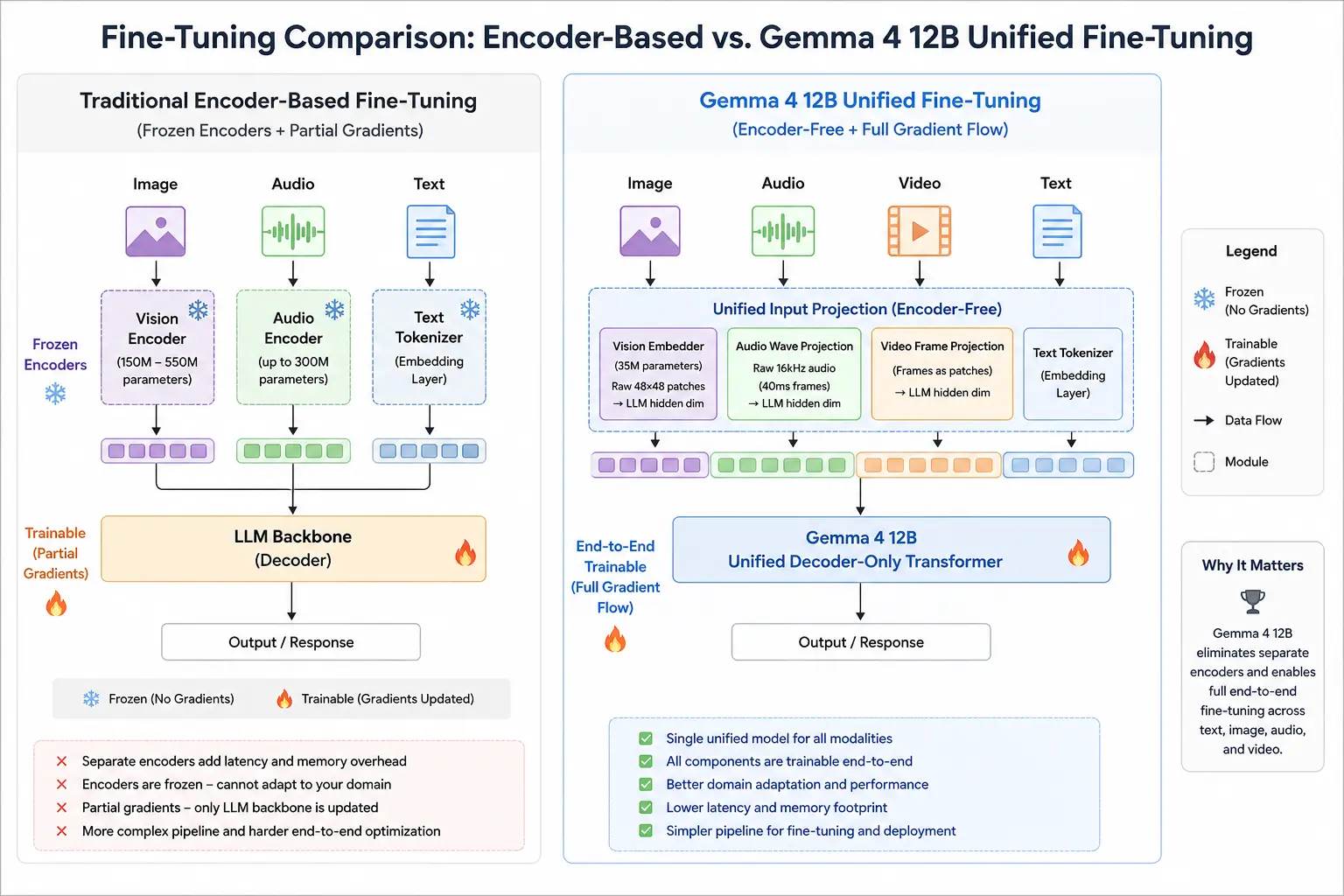
difference between encoder-based fine-tuning (frozen encoders + partial gradients) vs. Gemma 4 12B's unified fine-tuning flow
Conclusion
Gemma 4 12B is not just another open model. It introduces a real architectural shift dropping separate vision and audio encoders in favor of a single decoder-only transformer that handles every modality natively. The result is lower latency, simpler fine-tuning, and a model that fits on a 16GB laptop without meaningful capability loss.
The benchmark numbers confirm it. On DocVQA (94.9 for 26B, close behind for 12B), BBEH (53 vs. ~18 for the larger previous gen), and GPQA Diamond (78.8), Gemma 4 12B outperforms Gemma 3 27B a model with 2× the parameters.
If you are building locally, the Hugging Face model ID is google/gemma-4-12B-it. If you want a local API server, litert-lm serve is production-ready today.
FAQs
What makes Gemma 4 12B different from traditional multimodal models?
Gemma 4 12B uses an encoder-free architecture that processes text, images, audio, and video through a single decoder-only transformer, eliminating separate vision and audio encoders.
Can Gemma 4 12B run on consumer hardware?
Yes. Gemma 4 12B is designed to run locally on systems with approximately 16GB VRAM or unified memory, making advanced multimodal AI more accessible to developers.
Is Gemma 4 12B suitable for fine-tuning on custom datasets?
Yes. Since all modalities share the same weights, developers can fine-tune the entire multimodal pipeline using techniques like LoRA or full fine-tuning without managing separate encoders.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
