

EgoVerse Dataset Guide for Robot Learning
EgoVerse is redefining Physical AI with large-scale egocentric robot learning data, advanced annotation pipelines, and structured human demonstrations for scalable robot training.


Robots fail in the real world because they train on the wrong data. Third-person camera footage shows the scene. It misses hand contact. It misses the exact pixel a robot sees when it reaches for a tool.
Egocentric data fixes this. And EgoVerse, released in April 2026 by researchers from Georgia Tech, Stanford, UC San Diego, ETH Zürich, MIT, Meta Reality Labs, Mecka AI, and Scale AI - is the most important egocentric dataset built for robot learning so far.
This blog breaks down what EgoVerse is, how it works, what makes its annotation pipeline unique, and why the data quality behind it matters enormously for Physical AI.
What Is EgoVerse?
EgoVerse is a collaborative framework for building and sharing egocentric human demonstration data, designed from the ground up to train robot manipulation policies.
It is not a static dataset. It is a living ecosystem. New data flows in continuously from academic labs and industry partners. Everything is unified in one shared format.
The current release contains:
- 1,362 hours of human demonstrations
- 79,692 episodes
- 1,965 tasks
- 240 scenes
- 2,087 unique demonstrators

EgoVerse Overview
Why Egocentric Data? The Core Problem With Robot Datasets
Robot teleoperation is expensive. It requires physical hardware, expert operators, and controlled setups. You cannot scale it fast enough to match what vision and language models need.
Humans, on the other hand, do manipulation tasks all day. They cook, clean, sort, fold, and assemble, in diverse environments, with varied objects, at no extra cost. Egocentric cameras worn on the head capture this naturally.
But most prior human datasets, Ego4D, EPIC-KITCHENS, HOI4D, were not built for robot learning. They lack manipulation-relevant annotations. They include tasks robots cannot execute. They do not produce the structured signals a policy needs.
EgoVerse solves this with what the paper calls "bounded diversity." It focuses only on tasks that bimanual mobile manipulators can execute, while capturing natural variation across scenes, objects, and demonstrators.
Two Datasets in One: EgoVerse-A and EgoVerse-I
EgoVerse splits into two complementary components.
EgoVerse-A is controlled and reproducible. Academic labs collect data under shared protocols using Project Aria Gen 1 glasses, lightweight 75g head-worn devices with a wide-FoV RGB camera and two side-facing monochrome cameras for SLAM and hand tracking. Six flagship tasks are defined across all labs:
- object-in-container (single-arm)
- cup-on-saucer (bimanual precision)
- bag-grocery (long-horizon bimanual)
- fold-clothes (bimanual)
- scoop-granular (single-arm)
- sort-utensils (single-arm)
Each task is performed across 8–12 scenes per lab. Objects are randomized across trials. Demonstrators vary in height, posture, and movement style, creating natural diversity in egocentric viewpoints without requiring artificial augmentation.

Human Data Capture Setup
EgoVerse-I is built for scale and visual diversity. It contains nearly 1,400 hours of in-the-wild manipulation data across nearly 2,000 tasks. Industry partners collect this using custom stereoscopic head-mounted rigs, stereo fisheye RGB cameras at 1920×1200 resolution, 30 FPS, paired with depth streams and IMU-based SLAM for 6-DoF head pose recovery.
EgoVerse-I also supports a phone-based capture system. An iPhone mounted on a head strap records egocentric RGB at 1080p and 30 FPS. A cloud pipeline recovers 6-DoF head pose via visual tracking and estimates 3D hand poses with 21 keypoints per hand. This makes data collection accessible to anyone.
The task distribution in EgoVerse-I spans logistics (15.4%), cooking (13.7%), cleaning (11.6%), laundry (10.9%), hardware (6.8%), crafts (4.0%), and gardening (3.2%).

PDF, Dataset Composition and Diversity showing flagship tasks
The Annotation Pipeline: What Makes This Data Robot-Ready
Most video datasets give you pixels. EgoVerse gives robots something they can actually use.
For every frame, EgoVerse produces:
- 21 keypoints per hand in the camera frame, for both hands simultaneously
- 6-DoF head pose obtained from visual-inertial SLAM
- Dense language annotations at 1–2 second granularity (in EgoVerse-I)
- Active-hand indicators and static vs. mobile manipulation flags
- Scene identifiers, demonstrator metadata, and object tags
This is the annotation stack that turns raw video into a policy-learning signal.
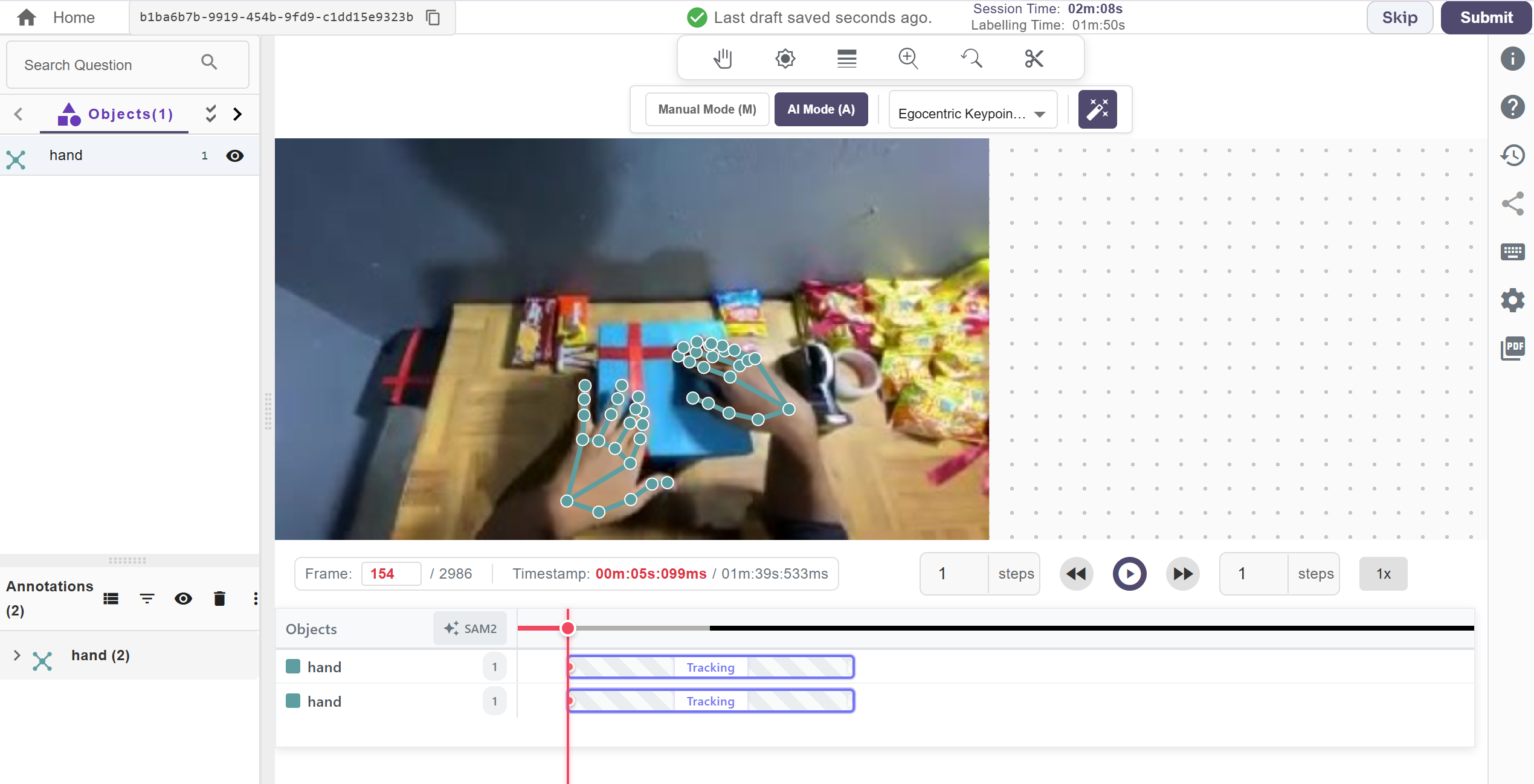
Hand landmark annotation workflow on EgoVerse data inside Labellerr
Academic labs process raw recordings through Meta's Machine Perception Services (MPS), which performs calibration, temporal alignment, and visual-inertial odometry to produce metrically consistent camera poses. Industry partners use model-based pose estimation and SLAM pipelines, all converting output into the same canonical EgoVerse format.
EgoDB: The Infrastructure Behind the Dataset
To manage this at scale, the team built EgoDB, a cloud-based data management system that runs as a living pipeline.
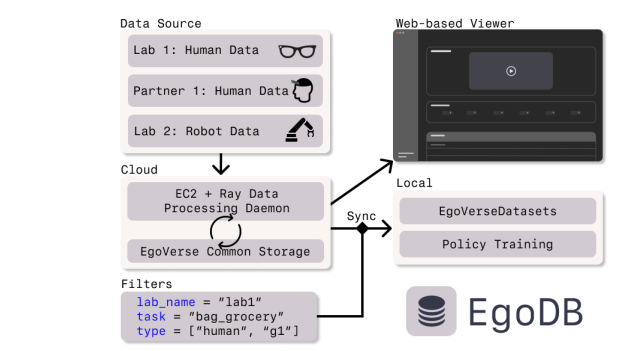
EgoDB
EgoDB handles continuous ingestion from all sources. Raw files are uploaded to S3-backed storage. A nightly Ray processing daemon runs across three clusters — one for MPS processing of Aria data, one for converting MPS output to training-ready format, and one for robot data conversion.
Episode metadata are stored in a centralized PostgreSQL database. Researchers can query by task, lab, scene, embodiment, or annotation type. A web-based viewer lets you browse demonstrations and inspect annotations before downloading.
For training, the EgoVerseDataset PyTorch interface lets users sync filtered subsets directly from S3. Parallelized downloads use the s5cmd library. Everything is reproducible without manual data management.
What the Research Found: Does Human Data Actually Help Robots?
The EgoVerse study ran experiments across three distinct robot platforms with different kinematics and sensing:
- Robot A: Two 6-DoF ARX5 arms, Aria glasses, Intel RealSense D405 wrist cameras
- Robot B: Two ARX5 arms in a shoulder-mounted human-like layout, GELLO teleoperation
- Robot C: Unitree G1 humanoid with 7-DoF arms, Inspire dexterous hands, ZED 2 stereo camera

Three robot platforms side by side with their hardware specs labeled
The results were consistent across most embodiments and tasks. Co-training with EgoVerse-A data improved both in-domain (ID) and out-of-domain (OOD) performance by up to 30% compared to training on robot data alone.
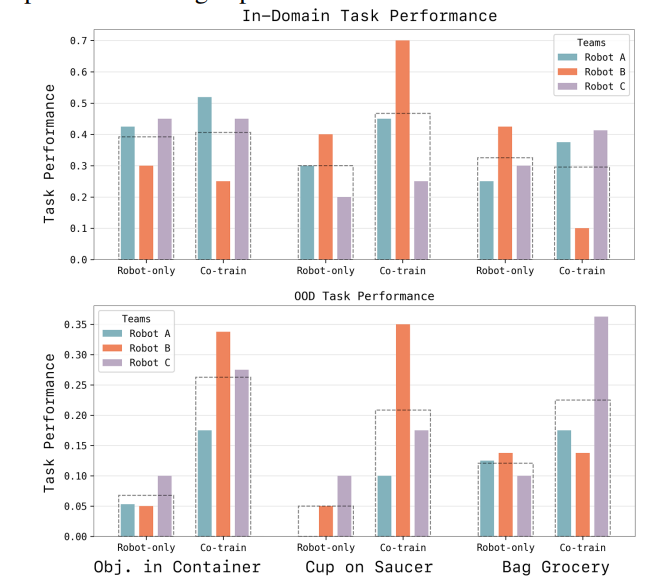
Co-training performance bar charts across robots for object-in-container, cup-on-saucer, and bag-grocery tasks
But scaling is not automatic. The study found that diverse human data only drives gains when a small amount of domain-aligned human data is also included. Just 2 hours of in-domain human data was enough to anchor learning and allow 8 hours of diverse EgoVerse-A data to transfer effectively.
The study also showed that scene diversity matters more than demonstrator diversity for generalization to novel environments. Increasing the number of scenes from 1 to 16 consistently reduced prediction error across data budgets. Demonstrator diversity helped generalization to unseen human motion patterns, but its benefit depended on the task.
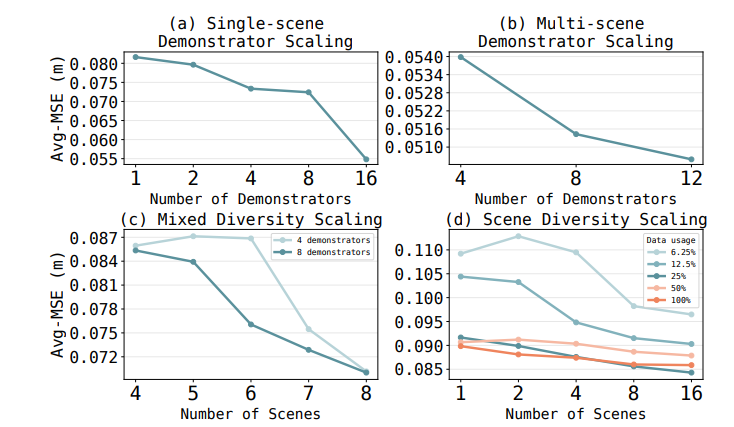
Controlled Diversity Results showing four scaling regime graphs
The Policy Architecture
The learning system uses a cross-embodiment encoder-decoder architecture. Image observations pass through a ResNet-18 backbone. Proprioceptive inputs go through an MLP. Both are tokenized and passed to a shared transformer encoder with 16 blocks, 8 attention heads, and 256-dimensional embeddings.
The action decoder is a flow matching transformer. It generates action sequences by learning a velocity field between Gaussian noise and ground-truth actions. At inference, 10 fixed-step Euler updates produce the final action sequence. Training ran for 150,000 steps with AdamW, learning rate 1×10⁻⁴, and a 1:1 human-to-robot batch ratio.
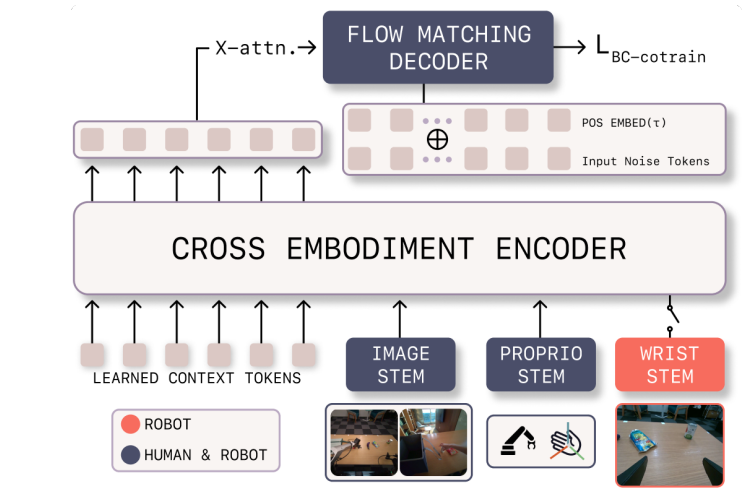
Model Architecture diagram of the cross-embodiment transformer policy backbone
Conclusion
EgoVerse proves three things clearly.
First, human egocentric data makes robots better, not just in controlled lab settings, but across embodiments and environments. Second, quality annotation is not optional. The 21-keypoint hand pose, 6-DoF head tracking, and dense language labels are what separate this from a video archive. Third, data infrastructure matters as much as data volume. EgoDB's living pipeline is what lets this dataset grow over time.
The hard part is not collecting the data. The hard part is annotating it correctly, at scale, with consistency, and in the exact format robot policies need.
Annotate Your Egocentric Data with Labellerr
Labellerr is built for exactly this. Whether you are working with EgoVerse data or building your own egocentric dataset for Physical AI, Labellerr provides the annotation infrastructure to do it right.
Our platform supports hand landmark annotation (21-keypoint skeleton annotation per hand, per frame), all the annotation types that egocentric robot learning datasets actually require.
Teams working on egocentric data pipelines for robotics use Labellerr to cut annotation time, maintain label consistency, and ship training-ready data faster.
Ready to scale your egocentric data pipeline? Book a demo with Labellerr, and see how accurate, high-throughput annotation works for Physical AI.
FAQs
What makes EgoVerse different from previous egocentric datasets?
EgoVerse is specifically designed for robot learning with structured annotations like 21-keypoint hand tracking, 6-DoF head pose estimation, and dense manipulation labels, making it usable for Physical AI training pipelines.
Why is egocentric data important for robot manipulation?
Egocentric data captures the exact visual perspective, hand interactions, and motion patterns humans use during manipulation tasks, helping robots learn more realistic and transferable behaviors.
How does EgoVerse improve robot training performance?
Research showed that combining EgoVerse human demonstrations with robot data improved both in-domain and out-of-domain robotic task performance by up to 30% across multiple robot embodiments.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
