

How NVIDIA EgoScale Trains Robots Using Human Hand Movements
NVIDIA EgoScale trains dexterous robots using 20,000+ hours of egocentric human video, enabling scalable robot learning, one-shot generalization, and improved manipulation performance across multiple robotic platforms.


What if the best teacher for a robot wasn't another robot - but you?
Every day, humans perform thousands of precise hand movements without thinking. We unscrew bottle caps, fold shirts, sort cards, and handle syringes. We do all of this with 21 articulated finger joints working in concert.
Robots have always struggled to replicate this. Not because the hardware is lacking but because the training data is. NVIDIA's new EgoScale framework flips the entire paradigm. Instead of teaching robots by recording robots, it trains them by watching humans.
The result is a 54% jump in task success rate. And the implications run much deeper than that number.
The Core Problem: Robot Data Doesn't Scale
Getting a robot to learn a manipulation task requires collecting demonstrations either by teleoperating the robot or having it explore on its own. Both approaches are slow, expensive, and narrow. You collect data for one task, on one robot, in one environment.
Humans, by contrast, perform dexterous manipulation constantly, everywhere, at a scale no robot lab can match. The question researchers at NVIDIA and UC Berkeley asked was simple: can we use that human data directly?
Prior work had tried. But earlier efforts used datasets of only tens to hundreds of hours, and they mostly focused on simple gripper-based robots, not high-degree-of-freedom dexterous hands. The finger articulation problem was left unsolved.
EgoScale attacks both limitations head-on.
What EgoScale Actually Does
EgoScale is a human-to-dexterous-manipulation transfer framework. It trains a Vision-Language-Action (VLA) model on massive amounts of first-person human video, specifically, egocentric footage where a camera mounted near the head captures what a person sees while using their hands.
The trained policy then transfers to a real dexterous robot with minimal additional robot-specific data.
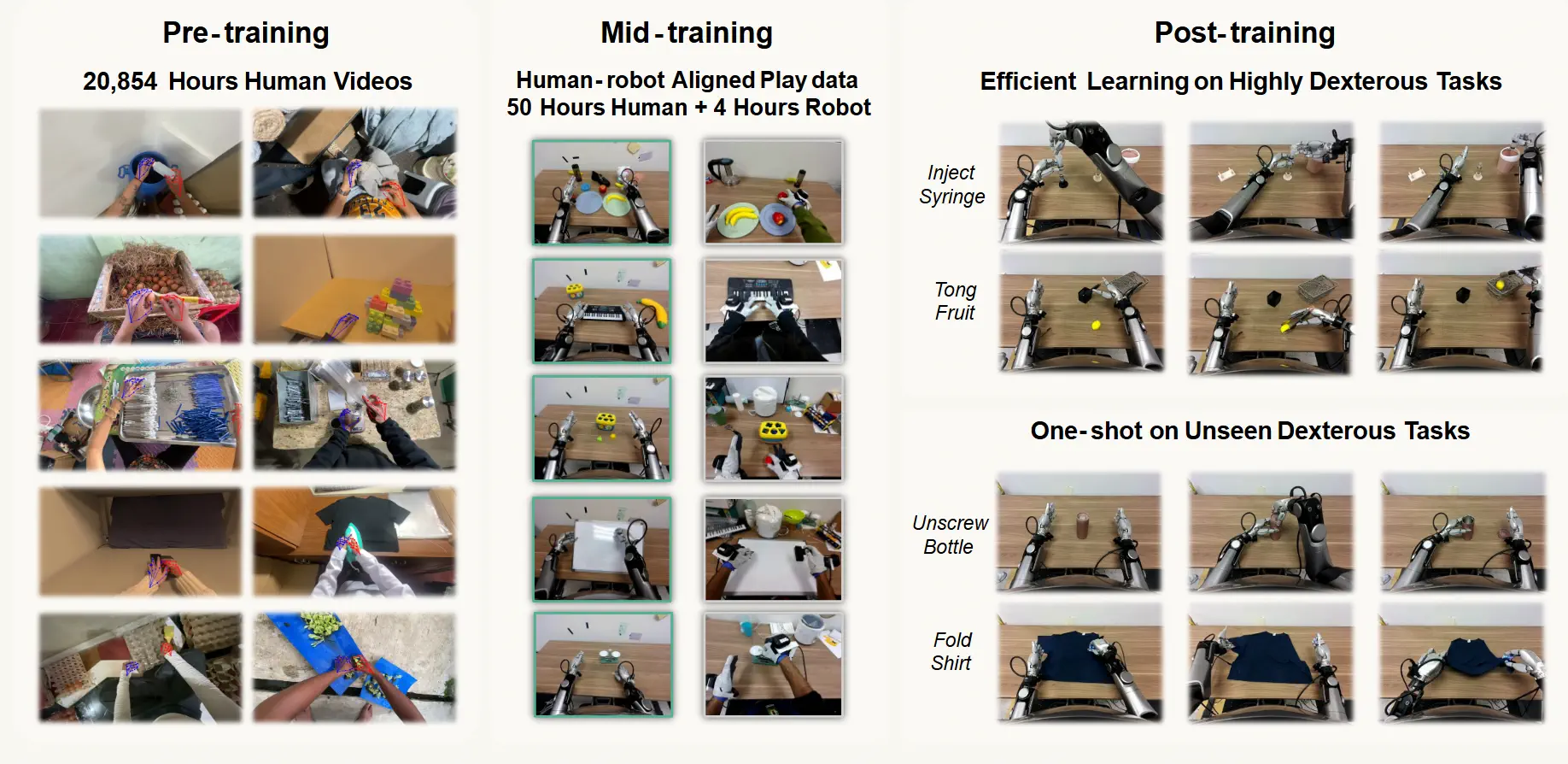
The three-stage pipeline
The framework has three stages:
Stage 1 - Human Pretraining: The model trains on 20,854 hours of egocentric human video. This is more than 20× larger than any prior human-to-robot transfer dataset. The videos span 9,869 scenes, 6,015 task types, and 43,237 distinct objects, from retail environments to home kitchens to repair shops.
Stage 2 - Mid-Training: A small aligned dataset of 50 hours of human data and just 4 hours of robot data bridges the gap between human demonstrations and robot control. Humans and robots perform the same tabletop tasks from matched camera angles. This "translation layer" is small but critical.
Stage 3 - Post-Training: The model fine-tunes on task-specific robot demonstrations, as few as one single demonstration in some cases.
The Architecture
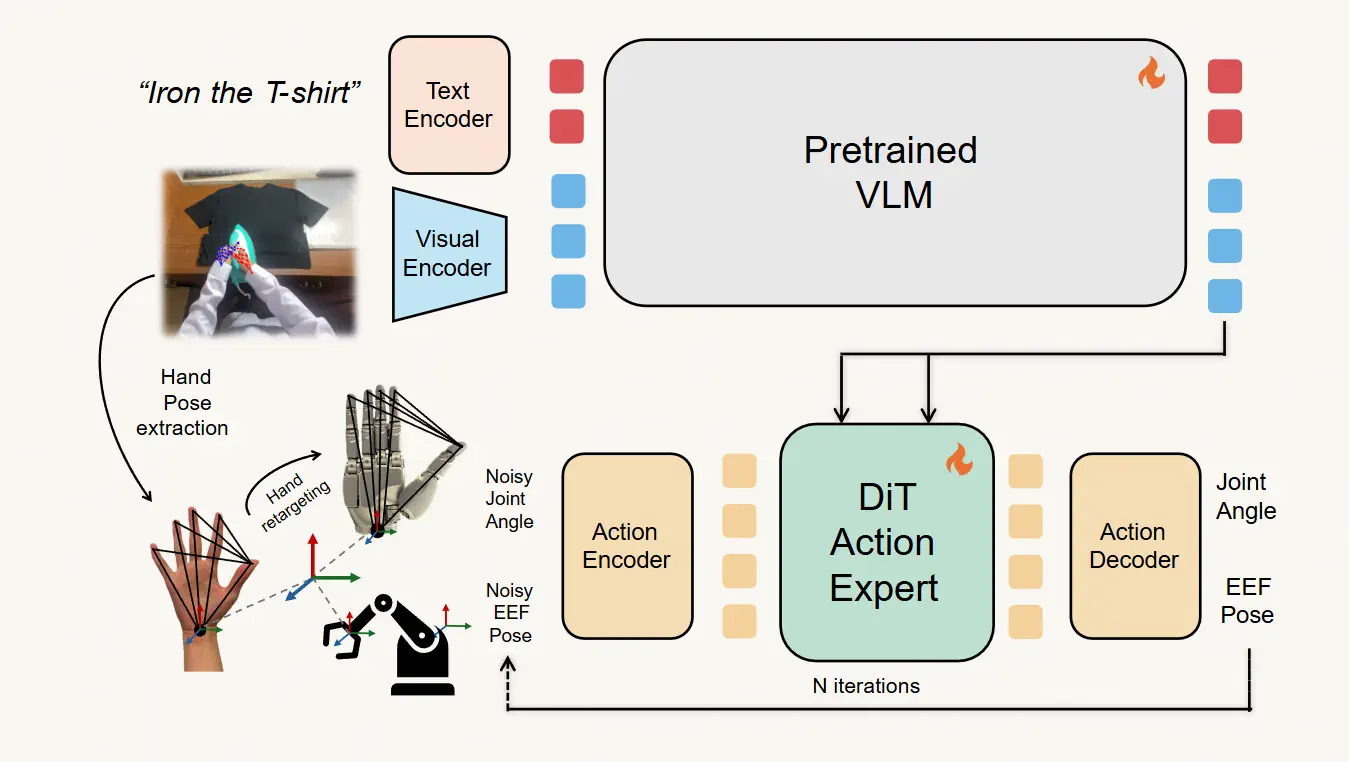
EgoScale model architecture
Image source
EgoScale's model architecture follows a flow-based VLA design similar to NVIDIA's GR00T N1 foundation model. At each timestep, the model takes an image and a language instruction as input. A pretrained Vision-Language Model (VLM) backbone encodes these into a joint embedding. A Diffusion Transformer (DiT) action expert then predicts a chunk of future actions using a flow-matching objective.
The clever part is how human and robot data coexist in the same model. Human demonstrations don't include proprioceptive signals, a robot knows its joint angles, but video of a human does not reveal this. EgoScale solves this with a learnable placeholder token that substitutes for proprioception during human training. No architectural changes needed.
For multi-robot support, lightweight embodiment-specific MLP adapters sit at the input and output. These adapters handle the proprioceptive state encoding and hand action decoding. But the VLM backbone and DiT action expert are fully shared across all embodiments. This means the core manipulation intelligence — built from human video, is reused everywhere.
Human actions are represented in two components:
First, wrist-level arm motion - relative SE(3) transforms between consecutive timesteps. This removes dependence on absolute camera position and works identically for humans and robots.
Second, hand articulation - 21 human hand key points retargeted into the 22 degrees-of-freedom joint space of the Sharpa Wave robotic hand. This is done via a per-frame nonlinear optimization implemented in CasADi and solved with IPOPT, enforcing joint limits and kinematic consistency throughout.
The Scaling Law Discovery
This is where EgoScale makes its most significant scientific contribution.
The team trained models on 1k, 2k, 4k, 10k, and 20k hours of human data. They measured validation loss, the model's error in predicting wrist and hand actions on held-out human video, at each scale.
The result was remarkably clean:
L = 0.024 − 0.003 × ln(D)
Where D is hours of human pretraining data. The R² fit was 0.9983, nearly perfect. Loss decreases log-linearly as data grows, with no sign of saturation at 20k hours.
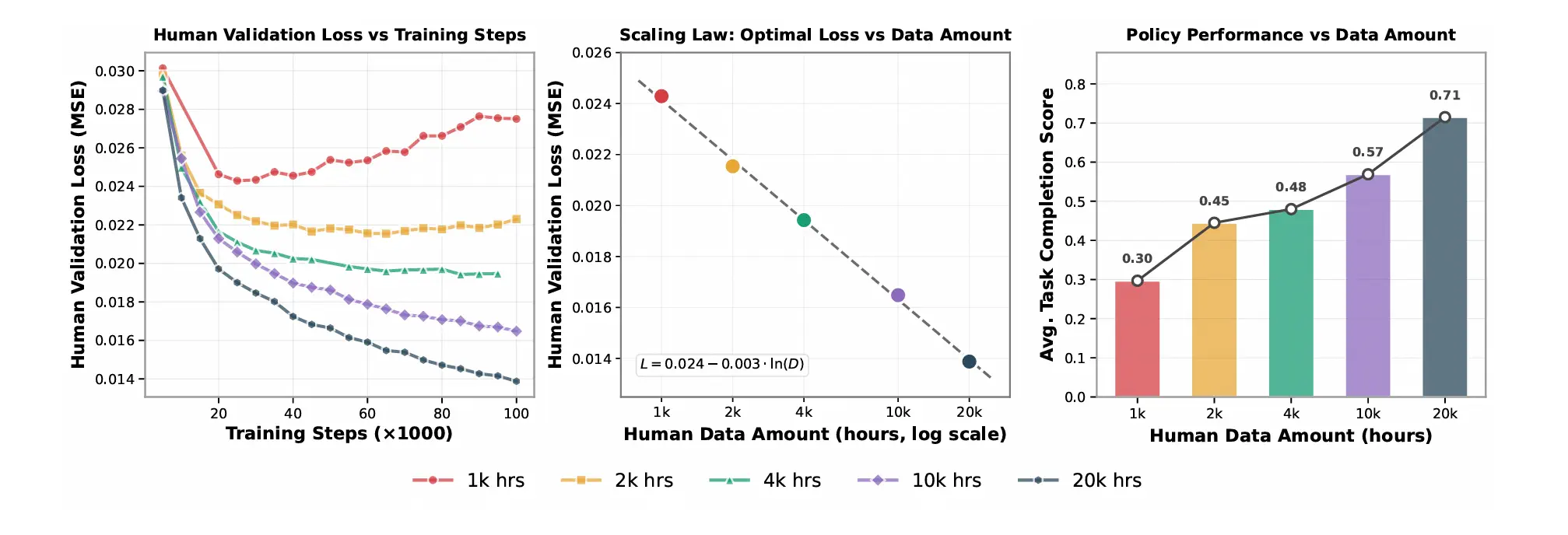
validation loss vs training steps, scaling law curve, and robot task performance vs data amount
More importantly, this offline metric directly predicted real-robot performance. Average task completion rose monotonically from 0.30 at 1k hours to 0.71 at 20k hours. Models trained on smaller datasets overfitted, their validation loss plateaued or degraded. Models trained on 10k–20k hours improved stably throughout training.
This is a genuine scaling law for embodied AI. It means performance is predictable, and more data reliably yields better robots.
Five Dexterous Tasks That Push the Limits
The evaluation suite was deliberately hard. Five tasks tested the full system on the Galaxea R1Pro humanoid robot equipped with 22-DoF Sharpa Wave dexterous hands:
video sources
Shirt Rolling - Both hands coordinate to fold and roll a T-shirt into a cylinder and place it in a basket. Deformable object manipulation with no fixed geometry.
Card Sorting - Fingers rub and separate a single card from a tightly stacked deck, then insert it into the correct color-coded holder. Requires sub-millimeter precision and tactile sensitivity.
Tong Fruit Transfer - The robot grasps tongs from a toolbox, uses them to pick up a fruit, places it in a basket, then returns the tongs. Multi-step tool use.
Bottle Cap Unscrewing - Continuous finger rotation to remove a cap, tested across four bottle sizes. Requires sustained coordinated finger motion.
Syringe Liquid Transfer - The most complex task. Pick up a syringe, draw liquid from tube A, inject into tube B, discard the syringe. Seven distinct subtasks in sequence.
Human Pretrain + Mid-training achieved average task completion scores of 0.83 and success rates of 0.56. No pretraining scored just 0.24 completion and 0.02 success. The gap is stark.
One Shot Is All It Takes
Perhaps the most striking result involves one-shot generalization. After mid-training, the policy was given only a single robot demonstration for two entirely new tasks, Fold Shirt and Unscrew Water Bottle, neither of which appeared in mid-training data.

One-shot transfer results
The Pretrain + Midtrain model achieved 88% success on shirt folding and 55% on bottle unscrewing from a single robot demonstration plus 100 aligned human demonstrations. Models without both pretraining and mid-training failed entirely in this setting.
This capability emerges from shared motion primitives. The mid-training data exposes the model to common motion structures - grasping, rotating, folding, that transfer to new objects and tasks with minimal robot supervision.
Cross-Robot Transfer: From 22 Fingers to 7
The human-learned representations also transferred to a completely different robot, the Unitree G1, which has a 7-DoF tri-finger hand instead of the 22-DoF Sharpa hand. The two platforms have fundamentally different kinematics and workspace geometry.
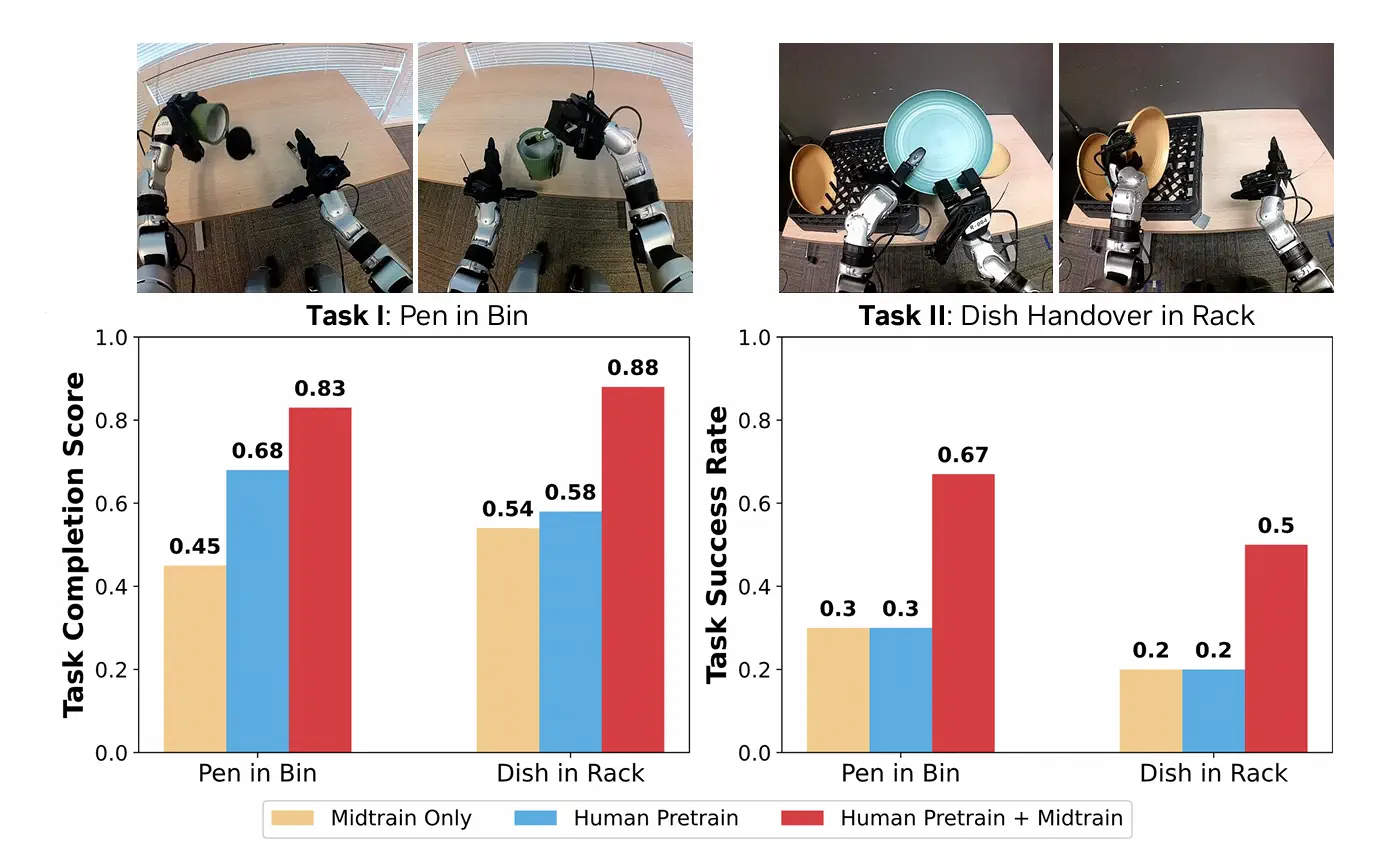
G1 cross-embodiment results
On two G1 tasks, placing a pen in a bin and transferring dishes to a rack, the human-pretrained policy with G1-specific mid-training outperformed direct training on G1 data alone by over 30% absolute improvement. Observers also noted qualitatively smoother robot motions in the pretrained policies.
This confirms that the human motor prior learned by EgoScale is genuinely embodiment-agnostic. The underlying structure of grasping and manipulation is transferable across very different mechanical designs.
Why Retargeted Joints Beat Fingertips
One design decision proved unexpectedly important: how to represent hand motion during pretraining.
The team compared three options - wrist-only (no finger information), fingertip SE(3) trajectories mapped to joints via MLP, and fully retargeted joint-space angles. The joint-space approach won on every task tested.
Wrist-only representations couldn't capture fine grasping. Fingertip representations introduced error propagation through the MLP mapping, causing implausible joint configurations in contact-sensitive tasks. Retargeted joint-space actions preserved the physical structure of human hand motion throughout — pinch semantics, fist closure, and coordinated finger timing all transferred cleanly.
Conclusion
EgoScale makes one thing undeniable: egocentric human data is no longer a supplement to robot training. It is the foundation. At 20k hours, it outperforms carefully curated robot-collected data by a margin that should make every robotics team rethink their data strategy.
The scaling law makes this concrete. Performance is predictable and improvable. More annotated egocentric video means better robots, directly and measurably. That is not a hypothesis. It is an empirical curve with an R² of 0.9983.
But raw egocentric video is worthless without precise annotation. EgoScale's pipeline depends on accurate wrist pose labeling, hand keypoint extraction, action segmentation, and task-level tagging across thousands of hours of diverse footage. That annotation work is where most teams hit a wall.
That is exactly the problem Labellerr solves
Labellerr specializes in egocentric data annotation, the high-complexity labeling that physical AI and robotics research demands. Wrist motion, hand pose, action boundaries, multi-view synchronization. We handle the data pipeline so your team can focus on the model.
Scale wins. But only when the data behind it is right.
Ready to scale your egocentric data pipeline? Talk to Labellerr
FAQs
What is NVIDIA EgoScale and why is it important for robotics?
EgoScale is a human-to-robot learning framework developed by NVIDIA that trains dexterous robots using large-scale egocentric human video data. It improves robot manipulation performance and enables one-shot task generalization.
How does EgoScale transfer human hand movements to robots?
EgoScale uses hand keypoint retargeting, wrist motion tracking, and Vision-Language-Action models to map human hand actions into robotic joint-space movements for dexterous manipulation tasks.
Why is egocentric data important for training robots?
Egocentric data captures natural first-person human interactions with objects, providing scalable and diverse manipulation demonstrations that help robots learn complex real-world tasks more effectively.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
